

|NO.Z.00014|——————————|BigDataEnd|——|Hadoop&ElasticSearch.V14|——|ELK.v14|集群|索引管理|映射操作|
一、映射操作
### --- 映射操作
~~~ 索引创建之后,等于有了关系型数据库中的database。
~~~ Elasticsearch7.x取消了索引type类型的设置,不允许指定类型,默认为_doc,但字段仍然是有的,
~~~ 我们需要设置字段的约束信息,叫做字段映射(mapping)字段的约束包括但不限于:### --- 字段的数据类型
~~~ 是否要存储
~~~ 是否要索引
~~~ 分词器
~~~ 我们一起来看下创建的语法。一、创建映射字段
### --- 语法
PUT / 索引库名 / _mapping
{
"properties": {
"字段名": {
"type": "数据类型",
"index": true, //是否索引,不索引就无法针对这个字段查询
"store": false, //存储,默认不存储,_source:存储了文档的所有字段内容;从_source字段中可以获取所有字段, 但是需要自己解析, 如果对某个字段指定了存储, 在查询时直接指定返回的字段会增加io开销。 "analyzer": "分词器"
}
}
}~~~ # 语法说明
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/mapping-params.html
// 字段名: 任意填写,下面指定许多属性,例如:
// type: 类型,可以是text、long、short、date、integer、object等
// index: 是否索引,默认为true
// store: 是否存储,默认为false
// analyzer: 指定分词器### --- 示例:发起请求:
~~~ # 示例一:
PUT /yanqi-company-index
~~~输出参数
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "yanqi-company-index"
}~~~ # 示例二:
~~~ # 响应结果:
PUT /yanqi-company-index/_mapping/
{
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"job": {
"type": "text",
"analyzer": "ik_max_word"
},
"logo": {
"type": "keyword",
"index": "false"
},
"payment": {
"type": "float"
}
}
}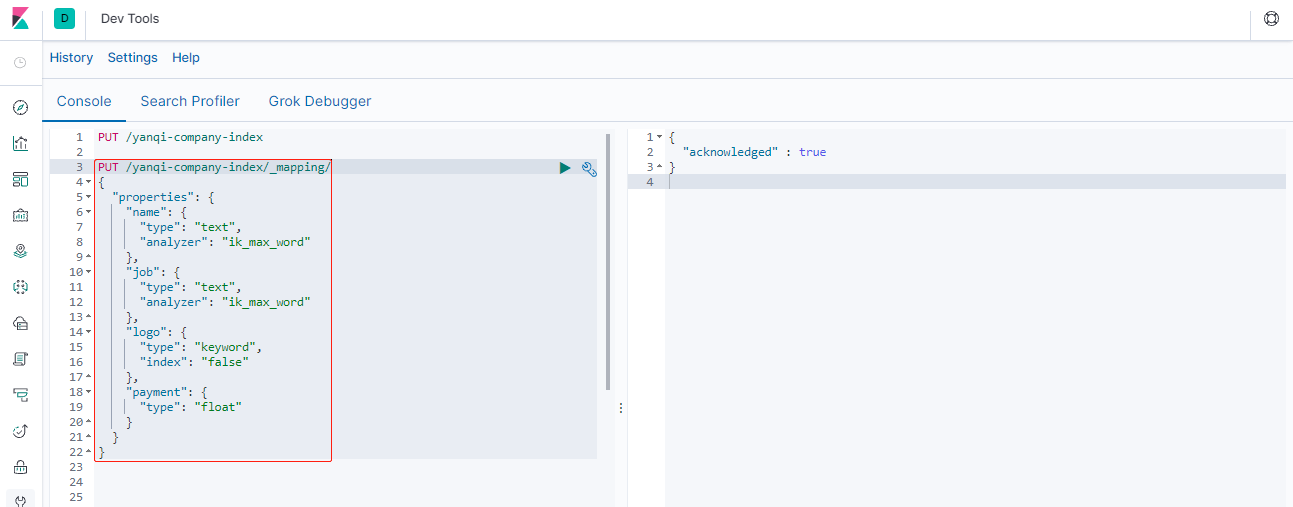
### --- 上述案例中,就给yanqi-company-index这个索引库设置了4个字段:
~~~ name:企业名称
~~~ job: 需求岗位
~~~ logo:logo图片地址
~~~ payment:薪资
~~~ 并且给这些字段设置了一些属性,至于这些属性对应的含义,我们在后续会详细介绍。二、映射属性详解
### --- type:Elasticsearch中支持的数据类型非常丰富:
~~~ https://www.elastic.co/guide/en/elasticsearch/reference/7.3/mapping-types.html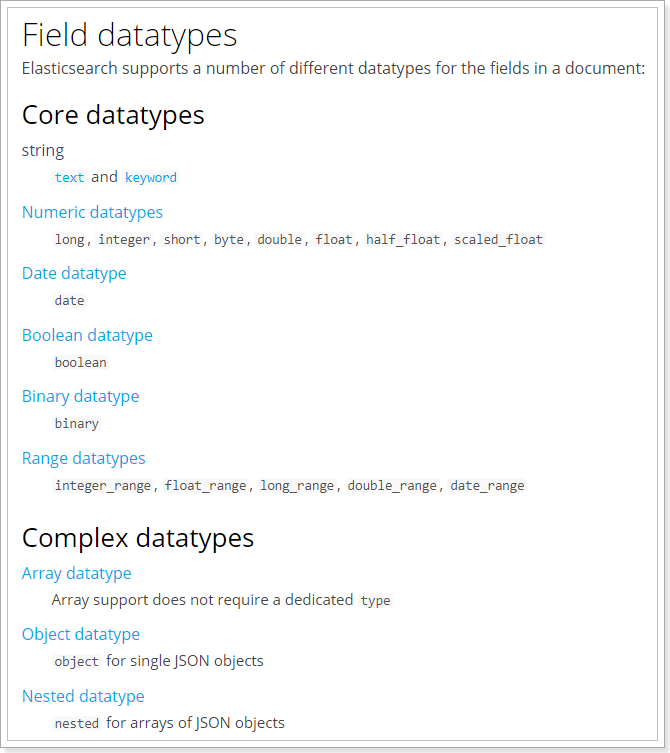
### --- 我们说几个关键的:
~~~ # String类型,又分两种:
~~~ text:可分词,不可参与聚合
~~~ keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
~~~ # Numerical:数值类型,分两类
~~~ 基本数据类型:long、interger、short、byte、double、float、half_float
~~~ 浮点数的高精度类型:scaled_float
~~~ 需要指定一个精度因子,比如10或100。
~~~ elasticsearch会把真实值乘以这个因子后存储,取出时再原。~~~ # Date:日期类型
~~~ elasticsearch可以对日期格式化为字符串存储,
~~~ 但是建议我们存储为毫秒值,存储为long,节省空间。
~~~ # Array:数组类型
~~~ 进行匹配时,任意一个元素满足,都认为满足
~~~ 排序时,如果升序则用数组中的最小值来排序,如果降序则用数组中的最大值来排序### --- Object:对象
~~~ # 如果存储到索引库的是对象类型,例如上面的girl,会把girl变成两个字段:girl.name和girl.age
{
name:"Jack",
age:21,
girl:{
name: "Rose", age:21
}
}### --- index
~~~ index影响字段的索引情况。
~~~ true:字段会被索引,则可以用来进行搜索。默认值就是true
~~~ false:字段不会被索引,不能用来搜索
~~~ index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。
~~~ 但是有些字段是我们不希望被索引的,比如企业的logo图片地址,就需要手动设置index为false。### --- store
~~~ 是否将数据进行独立存储。
~~~ 原始的文本会存储在_source 里面,
~~~ 默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。
~~~ 当然你也可以独立的存储某个字段,只要设置store:true即可,
~~~ 获取独立存储的字段要比从_source中解析快得多,但是也会占用更多的空间,
~~~ 所以要根据实际业务需求来设置,默认为false。### --- analyzer:指定分词器
~~~ 一般我们处理中文会选择ik分词器 ik_max_word ik_smart三、查看映射关系
### --- 查看单个索引映射关系
### --- 示例:响应:查看所有索引映射关系
~~~ # 语法:
~~~ GET /索引名称/_mapping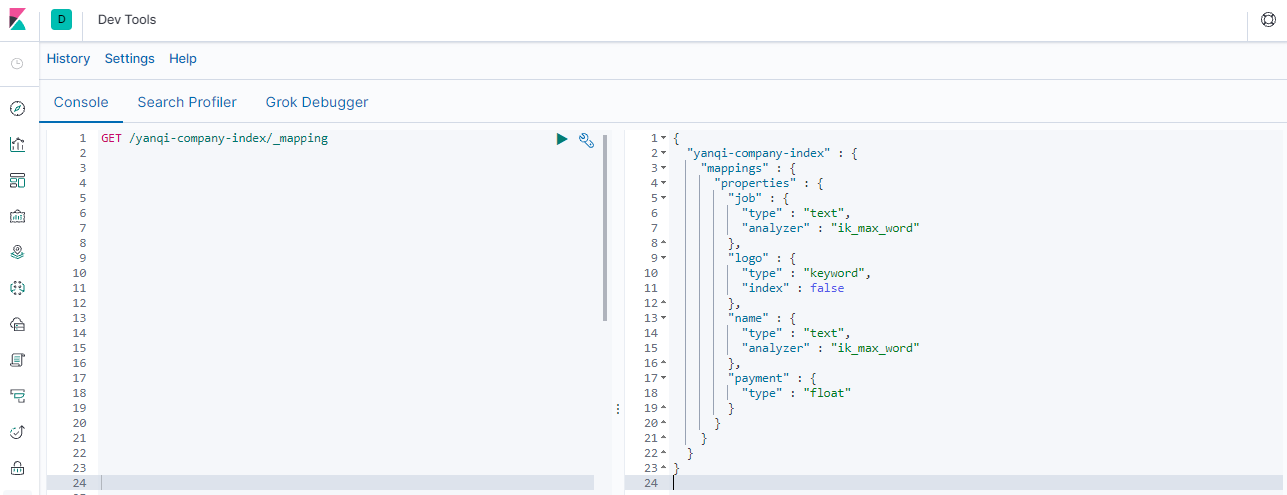
~~~ # 方式一
~~~ GET _mapping~~~ # 方式二
~~~ GET _all/_mapping### --- 修改索引映射关系
~~~ # 语法:注意:修改映射只能是增加字段操作,做其它更改只能删除索引 重新建立映射 。
PUT /索引库名/_mapping
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}四、一次性创建索引和映射
### --- 一次性创建索引和映射
~~~ 刚才 的案例中我们是把创建索引库和映射分开来做,
~~~ 其实也可以在创建索引库的同时,直接制定索引库中的索引,### --- 基本语法:
put / 索引库名称 {
"settings": {
"索引库属性名": "索引库属性值"
},
"mappings": {
"properties": {
"字段名": {
"映射属性名": "映射属性值"
}
}
}
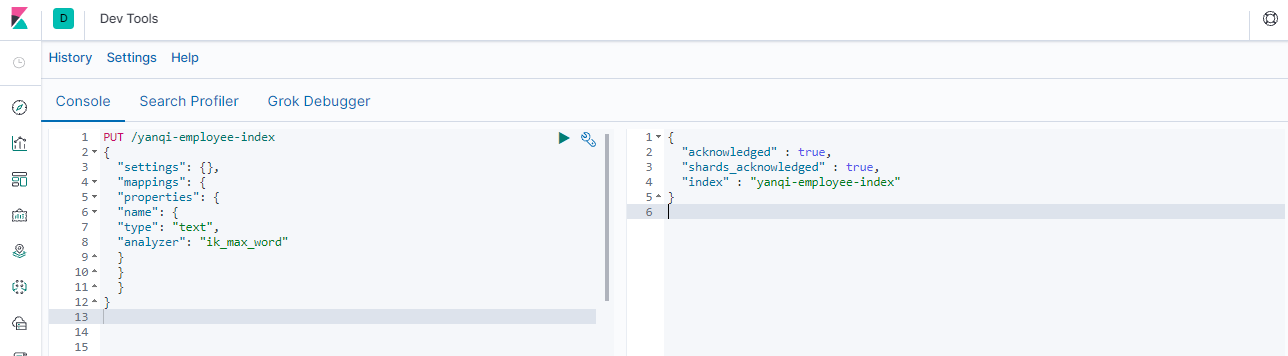
}### --- 案例
PUT /yanqi-employee-index
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv025-elk



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通