

|NO.Z.00008|——————————|BigDataEnd|——|Hadoop&OLAP_Kylin.V08|——|Kylin.v08|Kylin构建Cube|增量构建Cube.V1|
一、增量构建Cube
### --- 增量构建cube
~~~ 在大多数业务场景下,Hive中的数据处于不断增长的状态
~~~ 为了支持在构建Cube时,无需重复处理历史数据,引入增量构建功能二、Segment
### --- Kylin将Cube划分为多个Segment(对应就是HBase中的一个表)
~~~ 一个Cube可能由1个或多个 Segment 组成。
~~~ Segment是指定时间范围的Cube,可以理解为Cube的分区
~~~ Segment 是针对源数据中的某一个片段计算出来的 Cube 数据,代表一段时间内源数据的预计算结果
~~~ 每个Segment用起始时间和结束时间来标志
~~~ 一个 Segment 的起始时间等于它之前 Segment 的结束时间;
~~~ 它的结束时间等于它后面那个Segment的起始时间
~~~ 同一个 Cube 下不同的 Segment 除了背后的源数据不同之外,
~~~ 其他如结构定义、构建过程、优化方法、存储方式等都完全相同三、segment流程结构
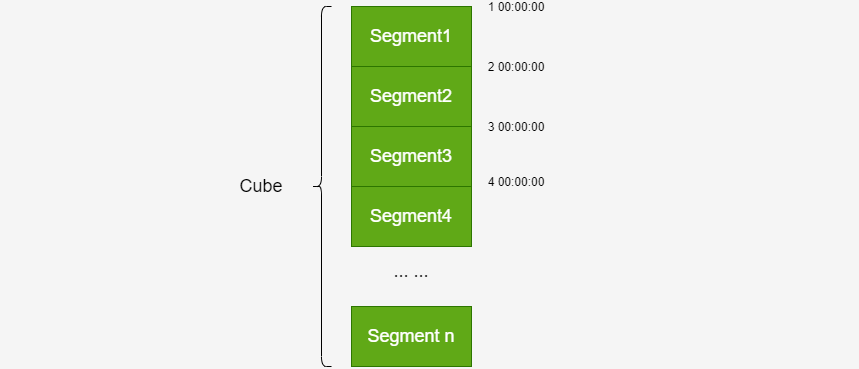
四、segment示意图
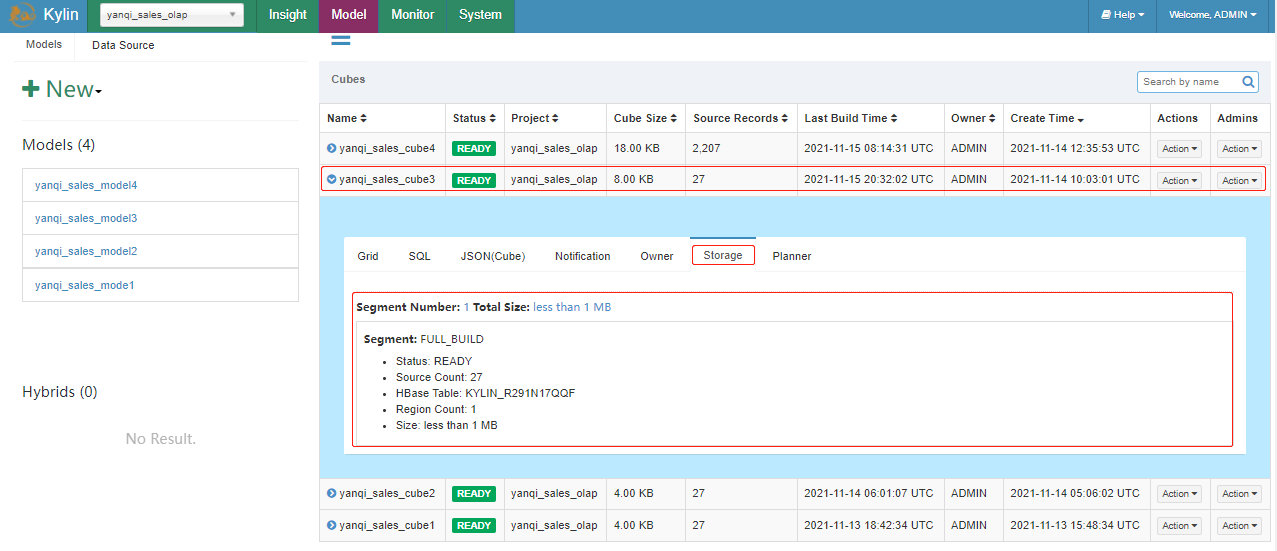
五、例如:以下为针对某个Cube的Segment
| segment名称 | 分区时间 | HBase表名 |
| 202110110000000-202110120000000 | 20211011 | KYLIN_41Z8123 |
| 202110120000000-202110130000000 | 20211012 | KYLIN_5AB2141 |
| 202110130000000-202110140000000 | 20211013 | KYLIN_7C1151 |
| 202110140000000-202110150000000 | 20211014 | KYLIN_811680 |
| 202110150000000-202110160000000 | 20211015 | KYLIN_A11AD1 |
六、全量构建与增量构建
### --- 全量构建:在全量构建中:
~~~ Cube中只存在唯一的一个Segment
~~~ 该Segment没有分割时间的概念,即没有起始时间和结束时间
~~~ 对于全量构建来说,每当需要更新Cube数据时,它不会区分历史数据和新加入的数据,
~~~ 即在构建时会导入并处理所有的数据### --- 增量构建:在增量构建中:
~~~ 只会导入新 Segment 指定的时间区间内的原始数据,
~~~ 并只对这部分原始数据进行预计算全量构建和增量构建的对比| 全量构建 | 增量构建 |
| 每次更新时都需要更新整个数据集 | 每次只对需要更新的时间范围进行更新,计算量相对较小 |
| 查询时不需要合并不同Segment的结果 | 查询时需要合并不同Segment的结果, 因此查询性能会受影响 |
| 不需要后续的Segment合并 | 累计一定量的Segment之后,需要进行合并 |
| 适合小数据量或全表更新的Cube | 适合大数据量的Cube |
### --- 全量构建与增量构建的Cube查询方式对比:
~~~ # 全量构建Cube
~~~ 查询引擎只需向存储引擎访问单个Segment所对应的数据,无需进行Segment之间的聚合
~~~ 为了加强性能,单个Segment的数据也有可能被分片存储到引擎的多个分区上,
~~~ 查询引擎可能仍然需要对单个Segment不同分区的数据做进一步的聚合~~~ # 增量构建Cube
~~~ 由于不同时间的数据分布在不同的Segment之中,
~~~ 查询引擎需要向存储引擎请求读取各个Segment的数据
~~~ 增量构建的Cube上的查询会比全量构建的做更多的运行时聚合,
~~~ 通常来说增量构建的Cube上的查询会比全量构建的Cube上的查询要慢一些
~~~ 对于小数据量的Cube,或者经常需要全表更新的Cube,
~~~ 使用全量构建需要更少的运维精力,以少量的重复计算降低生产环境中的维护复杂度。
~~~ 对应大数据量的Cube,例一个包含较长历史数据的Cube,
~~~ 如果每天更新,那么大量的资源是在用于重复计算,这种情况下可以考虑使用增量构建。七、增量构建Cube过程
### --- 指定分割时间列
~~~ 增量构建Cube的定义必须包含一个时间维度,
~~~ 用来分割不同的Segment,这样的维度称为分割时间列(Partition Date Column)。### --- 增量构建过程
~~~ 在进行增量构建时,
~~~ 将增量部分的起始时间和结束时间作为增量构建请求的一部分提交给Kylin的任务引擎
~~~ 任务引擎会根据起始时间和结束时间从Hive中抽取相应时间的数据,并对这部分数据做预计算处理
~~~ 将预计算的结果封装成为一个新的Segment,并将相应的信息保存到元数据和存储引擎中。
~~~ 一般来说,增量部分的起始时间等于Cube中最后一个Segment的结束时间Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv023-kylin



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通