|NO.Z.00003|——————————|^^ 配置 ^^|——|Hadoop&OLAP_Kylin.V03|——|Kylin.v03|Kylin构建Cube|准备数据源|
一、使用Kylin构建Cube:Kylin数据结构
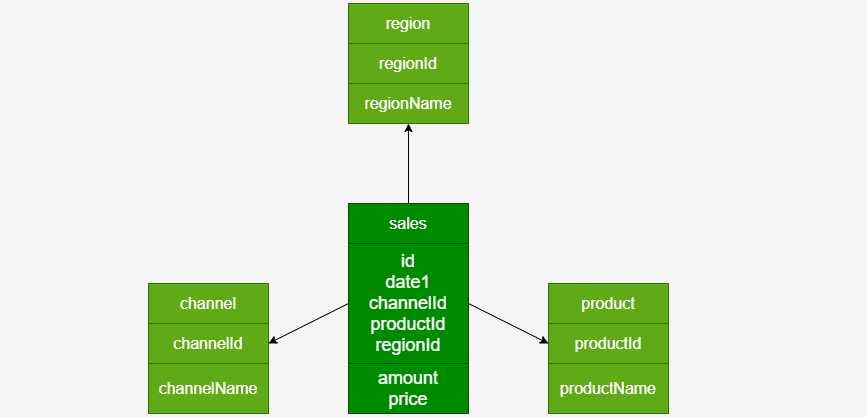
二、准备Kylin构建cube的数据文件
### --- 准备数据:准备脚本
~~~ # 准备数据文件dw_sales_data.txt、dim_channel_data.txt、dim_product_data.txt、dim_region_data.txt
[root@hadoop01 ~]# ll /data/kylin/
dim_channel_data.txt
dim_product_data.txt
dim_region_data.txt
dw_sales_data.txt
kylin_examples.sql
~~~ # 发送到其它主机
[root@hadoop01 ~]# rsync-script /data/kylin/### --- 准备数据文件:dim_channel_data.txt
[root@hadoop01 ~]# cat /data/kylin/dim_channel_data.txt
01,商场
02,京东
03,天猫### --- 准备数据文件:dim_product_data.txt
[root@hadoop01 ~]# cat /data/kylin/dim_product_data.txt
01,meta20
02,p30
03,ihpone Xs
04,小米 9### --- 准备数据文件:dim_region_data.txt
[root@hadoop01 ~]# cat /data/kylin/dim_region_data.txt
010,北京
021,上海### --- 准备数据文件:dw_sales_data.txt
[root@hadoop01 ~]# cat /data/kylin/dw_sales_data.txt
0001,2021-11-01,01,01,010,1,3400.00
0002,2021-11-01,02,02,021,2,6800.00
0003,2021-11-01,01,01,010,1,3400.00
0004,2021-11-01,01,02,021,1,3400.00
0005,2021-11-01,02,01,010,1,3400.00
0006,2021-11-01,01,01,021,2,6800.00
0007,2021-11-01,03,02,010,1,3400.00
0008,2021-11-01,01,01,021,1,3400.00
0009,2021-11-01,01,03,010,1,3400.00
0010,2021-11-01,02,01,021,3,10200.00
0011,2021-11-01,01,04,010,1,3400.00
0012,2021-11-01,03,01,021,1,3400.00
0013,2021-11-01,01,04,010,1,3400.00
0014,2021-11-02,01,01,010,1,3400.00
0015,2021-11-02,02,02,021,2,6800.00
0016,2021-11-02,01,01,010,1,3400.00
0017,2021-11-02,01,02,021,1,3400.00
0018,2021-11-02,02,01,010,1,3400.00
0019,2021-11-02,01,01,021,2,6800.00
0020,2021-11-02,03,02,010,1,3400.00
0021,2021-11-02,01,01,021,1,3400.00
0022,2021-11-02,01,03,010,1,3400.00
0023,2021-11-02,02,01,021,3,10200.00
0024,2021-11-02,01,04,010,1,3400.00
0025,2021-11-02,03,01,021,1,3400.00
0026,2021-11-02,01,04,010,1,3400.00
0027,2021-11-02,01,04,010,1,3400.00### --- 准备数据文件:kylin_examples.sql
~~~ # kylin_examples.sql脚本文件内容
[root@hadoop01 ~]# cat /data/kylin/kylin_examples.sql
-- 创建订单数据库、表结构
create database if not exists `yanqi_kylin`;~~~ # 1、销售表:dw_sales
-- id 唯一标识
-- date1 日期
-- channelId 渠道ID
-- productId 产品ID
-- regionId 区域ID
-- amount 数量
-- price 金额
create table yanqi_kylin.dw_sales(
id string,
date1 string,
channelId string,
productId string,
regionId string,
amount int,
price double
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
~~~ # 2、渠道表:dim_channel
-- channelId 渠道ID
-- channelName 渠道名称
create table yanqi_kylin.dim_channel(
channelId string,
channelName string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';~~~ # 3、产品表:dim_product
create table yanqi_kylin.dim_product(
productId string,
productName string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
~~~ # 4、区域表:dim_region
create table yanqi_kylin.dim_region(
regionId string,
regionName string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';~~~ # 导入数据
LOAD DATA LOCAL INPATH '/data/kylin/dw_sales_data.txt' OVERWRITE INTO TABLE yanqi_kylin.dw_sales;
LOAD DATA LOCAL INPATH '/data/kylin/dim_channel_data.txt' OVERWRITE INTO TABLE yanqi_kylin.dim_channel;
LOAD DATA LOCAL INPATH '/data/kylin/dim_product_data.txt' OVERWRITE INTO TABLE yanqi_kylin.dim_product;
LOAD DATA LOCAL INPATH '/data/kylin/dim_region_data.txt' OVERWRITE INTO TABLE yanqi_kylin.dim_region;三、在hive导入数据
### --- 执行命令 hive -f kylin_examples.sql
~~~ # 在hive导入数据
[root@hadoop02 ~]# hive -f /data/kylin/kylin_examples.sql### --- 检查建表、数据导入操作是否成功
~~~ # 检查数据是否导入成功
[root@hadoop02 ~]# hive
hive (default)> show databases;
yanqi_kylin~~~ # 检查表是否创建成功
hive (default)> use yanqi_kylin;
hive (yanqi_kylin)> show tables;
tab_name
dim_channel
dim_product
dim_region
dw_sales### --- 按照日期统计订单量、订单总金额
~~~ # 按照日期统计订单量、订单总金额
hive (default)> use yanqi_kylin;
hive (yanqi_kylin)> select date1, sum(price) as total_money,
sum(amount) as total_amount from dw_sales group by date1;
~~~输出参数:
date1 total_money total_amount
2021-11-01 57800.0 17
2021-11-02 61200.0 18四、hive表数据变化
### --- 维度表的优化
~~~ 要具有数据一致性,主键值必须是唯一的(否则 Kylin 构建过程会报错)
~~~ 维度表越小越好,因为 Kylin 会将维度表加载到内存中供查询,
~~~ 过大的表不适合作为维度表,默认的阈值是 300MB
~~~ 改变频率低,Kylin 会在每次构建中试图重用维度表的快照(Snapshot),
~~~ 如果维度表经常改变的话,重用就会失效,这就会导致要经常对维度表创建快照
~~~ 维度表最好不要是 Hive 视图(View),因为每次都需要将视图进行物化,从而导致额外的时间开销### --- 事实表的优化
~~~ 移除不参与 Cube 构建的字段,可以提升构建速度,降低 Cube 构建结果的大小
~~~ 尽可能将事实表进行维度拆分,提取公用的维度
~~~ 保证维度表与事实表的映射关系,过滤无法映射的记录Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor

 浙公网安备 33010602011771号
浙公网安备 33010602011771号