

|NO.Z.00001|——————————|BigDataEnd|——|Hadoop&OLAP_Kylin.V01|——|Kylin.v01|概述|
一、Apache Kylin 实战
### --- 课程概述:
~~~ 概述(历史、特点、应用场景;基本术语;技术架构;工作原理;生态)
~~~ 安装配置
~~~ 构建Cube (全量构建)
~~~ 增量构建Cube
~~~ Cube优化
~~~ 流式构建### --- Apache Kylin实战
~~~ Apache Kylin™是一个开源的分布式的分析引擎提供 Hadoop 之上的
~~~ SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据最初由 eBay
~~~ 开发并贡献至开源社区它能在亚秒内查询巨大的表。
~~~ 麒麟出没,必有祥瑞二、Kylin概述
### --- 背景、历史及特点
~~~ Apache Kylin,一种MOLAP的数据分析引擎。
~~~ 最早脱胎于eBay中国研发中心,并贡献给Apache基金会,
~~~ 目前Apache Kylin的核心开发团队已经自立门户,创建了 Kyligence (Kylin Intelligence) 公司。
~~~ 值得一提的是,Apache Kylin是第一个由中国人主导的Apache顶级项目。
~~~ eBay使用的传统数据仓库和商业智能平台遇到瓶颈,Hadoop平台虽然可以批量处理大规模数据,
~~~ 但无法提供高效的数据交互分析。于是,Kylin被eBay孵化了。### --- Apache Kylin 发展历程
~~~ 2014 年 Kylin 诞生,支持 Hive 批数据源,从海量历史数据挖掘价值
~~~ 2015 年 V1.5 首次支持 Kafka 数据源,采用单机微批次构建
~~~ 2016 年 V1.6 发布准实时(NRT Streaming), 使用 Hadoop 微批次消费流数据
~~~ 2017 年 V2.0 支持雪花模型和 Spark 引擎
~~~ eBay 团队开始尝试 real-time
~~~ 2018 年 V2.4 支持 Kafka 流数据 与 Hive 维度表 join
~~~ eBay 开源 real-time OLAP 实现
~~~ 2019 年 Q1,经过社区 review 和完善,合并 master
~~~ 2019 年 Q4,v3.0 发布 Real-time OLAP,实现秒级数据准备延迟
~~~ Kylin提供多维数据分析(MOLAP)的秒级响应。目前国内很多公司都在使用Kylin。### --- Kylin的特点:
~~~ # 数据源和模型:
~~~ 主要支持Hive、Kafka
~~~ # 构建引擎:
~~~ 早期支持MapReduce计算引擎,新版本支持Spark、Flink计算引擎。
~~~ 除了全量构建外,对基于时间的分区特性,支持增量构建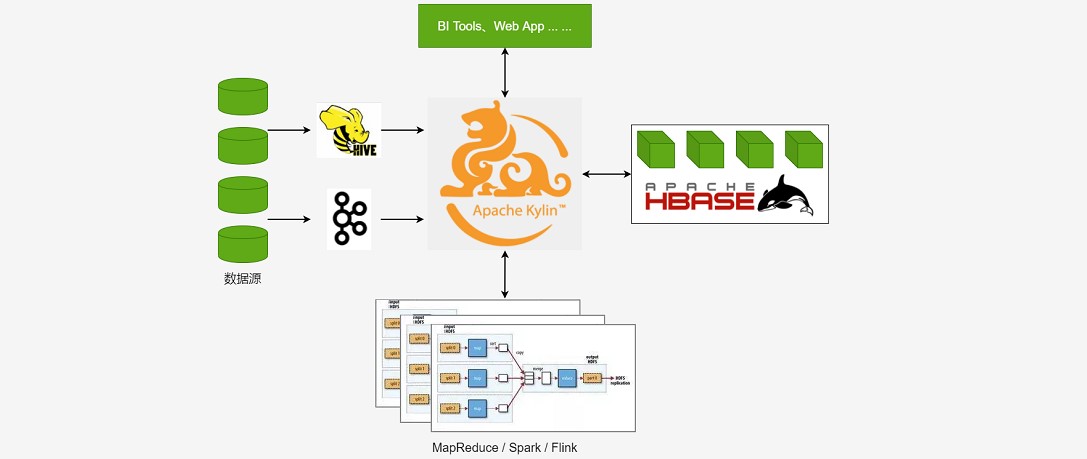
~~~ # 存储引擎:
~~~ 构建好的Cube以Key-Value的形式存储在HBase中,通过优化Rowkey加速查询。
~~~ 每一种维度的排列组合计算结果被保存为一个物化视图,叫Cuboid
~~~ # 优化算法:
~~~ Cube本身就是用空间换时间,也会根据算法,剪枝优化掉一些多余的Cuboid,寻求平衡~~~ # 访问接口:
~~~ 支持标准SQL接口,可以对接 Zeppelin、Tableau 等 BI 工具。
~~~ SQL通过查询引擎,可以被路由到对应的Cuboid上三、应用场景
### --- kylin特点
~~~ 特点:Kylin在亚秒内返回海量数据的查询结果。### --- Kylin 典型的应用场景如下:
~~~ 巨大的数据量,单个数据源表千亿行数据级别,且单个数据源达百TB级别
~~~ 巨大的查询压力(查询的高并发)
~~~ 查询的快速响应
~~~ 下游较灵活的查询方式, 需支持带有复杂条件的 SQL 查询
~~~ Kylin 的核心思想是预计算,将数据按照指定的维度和指标,
~~~ 预先计算出所有可能的查询结果,利用空间换时间来加速模式固定的 OLAP 查询。四、基本术语
### --- 数据仓库
~~~ 数据仓库是一种信息系统的资料储存理论,强调的是利用某些特殊的资料储存方式,
~~~ 让所包含的资料特别有利于分析和处理,从而产生有价值的资讯,并可依此做出决策。
~~~ 利用数据仓库的方式存放的资料,具有一旦存入,便不会随时间发生变动的特性,
~~~ 此外,存入的资料必定包含时间属性,通常一个数据仓库中会含有大量的历史性资料,
~~~ 并且它可利用特定的分析方式,从其中发掘出特定的资讯。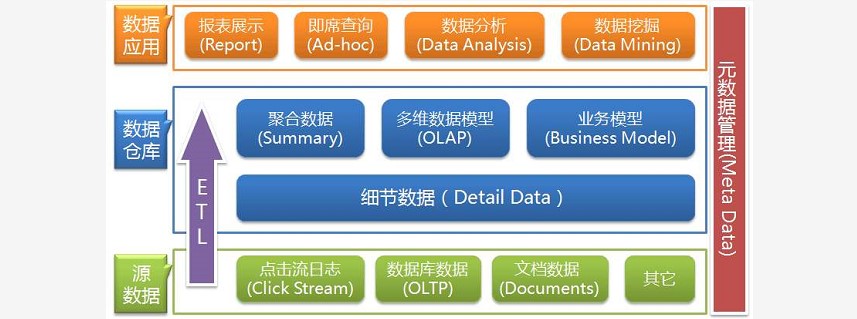
### --- OLTP
~~~ 联机事务处理。传统的关系型数据库的应用。
~~~ # OLAP分类
~~~ OLAP(Online Analytical Process),联机分析处理,以多维度的方式分析数据。
~~~ 它是呈现集成性决策信息的方法,多用于数据仓库 或 商务智能。
~~~ 其主要的功能在于方便大规模数据分析及统计计算,可对决策提供参考和支持。
~~~ 与之相区别的是联机交易处理(OLTP),联机交易处理,侧重于基本的、日常的事务处理,
~~~ 主要是数据的增删改查。~~~ # OLAP的概念
~~~ 在实际应用中存在广义和狭义两种不同的理解方式。
~~~ 广义上的理解与字面上的意思相同,泛指一切不会对数据进行更新的分析处理。
~~~ 但更多的情况下OLAP被理解为其狭义上的含义,即与多维分析相关,
~~~ 基于立方体(Cube)计算而进行的分析。
~~~ OLAP有多种实现方法,根据存储数据的方式不同可以分为ROLAP、MOLAP、HOLAP。
~~~ ROLAP(Relational OLAP),细节数据、聚合后的数据都保存在类关系型的数据库中。
~~~ Hive、SparkSQL等属于ROLAP。
~~~ MOLAP(Multidimensional OLAP),事先将汇总数据计算好,存放在自己特定的多维数据库中,
~~~ 用户的OLAP操作可以直接映射到多维数据库的访问,不通过SQL访问,其实质是空间换时间。
~~~ Apache Kylin本质上是 MOLAP。
~~~ HOLAP(Hybrid OLAP),表示基于混合数据组织的OLAP实现(Hybrid OLAP)。
~~~ 如低层是关系型的,高层是多维矩阵型的。这种方式具有更好的灵活性。### --- 事实表和维度表
~~~ # 事实表(Fact Table)
~~~ 是指存储有事实记录的表,如系统日志、销售记录、传感器数值等;
~~~ 事实表的记录是动态增长的,所以它的体积通常远大于维度表。~~~ # 维度表(Dimension Table)或维表,也称为查找表(Lookup Table),
~~~ 是与事实表相对应的一种表;它保存了维度的属性值,可以跟事实表做关联;
~~~ 相当于将事实表上经常重复的属性抽取、规范出来用一张表进行管理。
~~~ 常见的维度表有:日期表(存储与日期对应的周、月、季度等属性)、
~~~ 地区表(包含国家、省/州、城市等属性)等。维度表的变化通常不会太大。~~~ # 使用维度表有许多好处:
~~~ 缩小了事实表的大小
~~~ 便于维度的管理和维护,增加、删除和修改维度的属性,不必对事实表的大量记录进行改动
~~~ 维度表可以为多个事实表重用~~~ # 维度和度量
~~~ userid,2020-10-01 09:00:00, produceid,shopid,orderid,299~~~ # 维度:
~~~ 是指审视数据的角度,它通常是数据记录的一个属性,例如时间、地点等。
~~~ # 度量:
~~~ 就是被聚合的统计值,也就是聚合运算的结果。
~~~ 通常是一个数值,如总销售额、不同的用户数等。
~~~ 分析人员往往要结合若干个维度来审查度量值,以便在其中找到变化规律。
~~~ 在一个SQL查询中,Group By的属性通常就是维度,而所计算的值则是度量。~~~ # 以上查询中,part_dt、lstg_site_id是维度,sum(price)、count(distinct seller_id)是度量。
select part_dt,
lstg_site_id,
sum(price) as total_selled,
count(distinct seller_id) as sellers
from kylin_sales
group by part_dt, lstg_site_id;### --- 星型模型 & 雪花模型
~~~ # 星型模型(Star Schema)是数据仓库维度建模中常用的数据模型之一。
~~~ 它的特点是一张事实表,以及一到多个维度表,事实表与维度表通过主外键相关联,
~~~ 维度表之间没有关联,就像许多小星星围绕在一颗恒星周围,所以名为星型模型。~~~ # 另一种常用的模型是雪花模型(SnowFlake Schema),
~~~ 就是将星型模型中的某些维表抽取成更细粒度的维表,然后让维表之间也进行关联,
~~~ 这种形状酷似雪花的的模型称为雪花模型。
~~~ 低版本的Kylin只支持星型模型,从 2.0 开始支持雪花模型。
~~~ Cube和Cuboid:Cube 即多维立方体,也叫数据立方体。
~~~ 这是由三个维度(维度数可以超过 3 个,
~~~ 上图仅为了方便画图表达)构成的一个 OLAP 立方体,
~~~ 立方体中包含了满足条件的 cell(子立方块)值,这些 cell 里面包含了要分析的数据,
~~~ 称之为度量值。~~~ # 立方体:
~~~ 由维度构建出来的多维空间包含了所有要分析的基础数据所有的聚合数据操作都在立方体上进行
~~~ # 维度:
~~~ 观察数据的角度。一般是一组离散的值。对于N个维度来说,所有可能的组合有2 的 N 次方个~~~ # 度量:
~~~ 即聚合计算的结果,一般是连续的值
~~~ # Cuboid:
~~~ 特指 Kylin 中在某一种维度组合下所计算的数据
~~~ 事实表中的一个字段,要么是维度,要么是度量(可以被聚合)
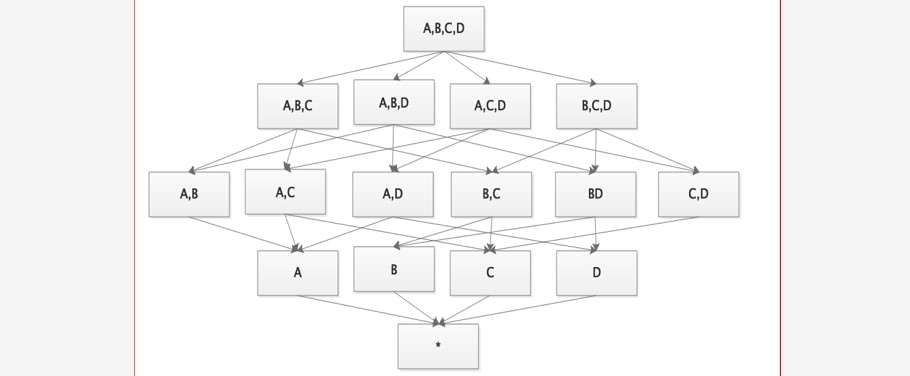
~~~ 给定一个数据模型可以对其上的所有维度进行组合。
~~~ 对于N个维度来说,所有可能的组合有2 的 N 次方个
~~~ Cube(或称Data Cube),即数据立方体,是一种常用于数据分析与索引技术,
~~~ 它可以对原始数据建立多维度索引,大大加快查询效率。数据立方体只是多维模型的一个形象的说法
~~~ Cuboid 特指 Kylin 中在某一种维度组合下所计算的数据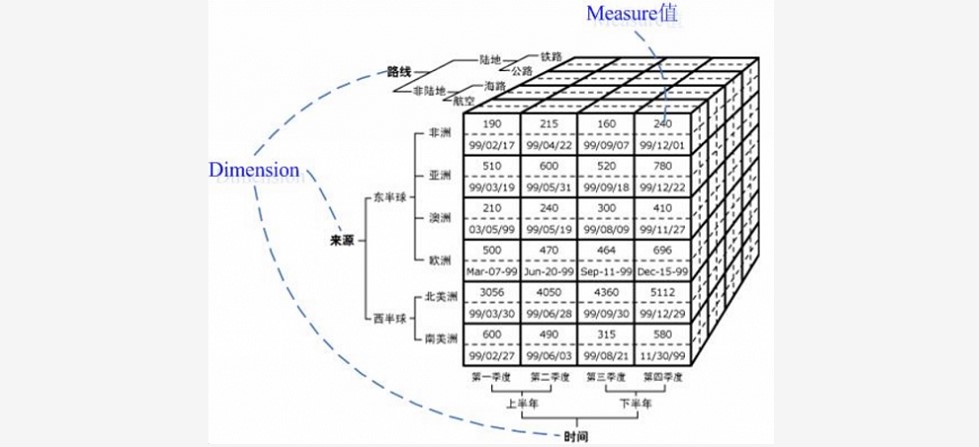
组合示意图
五、Kylin的技术架构
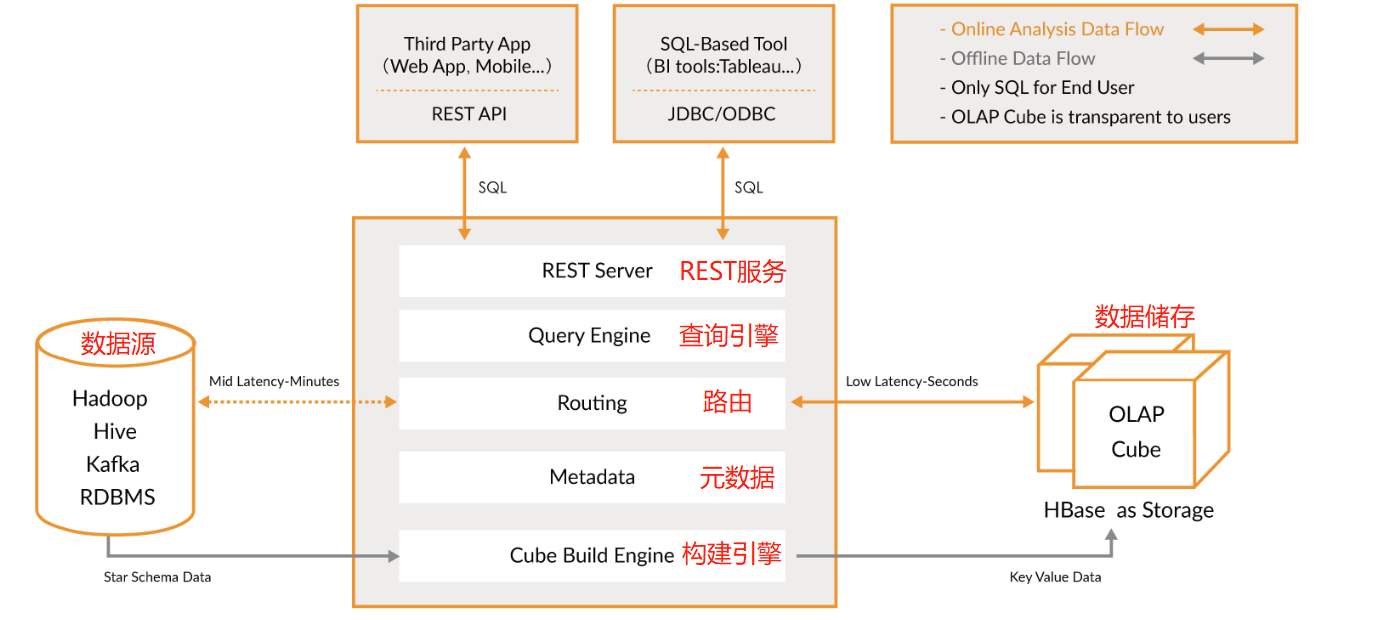
### --- Apache Kylin系统可以分为:在线查询和离线构建两部分。
~~~ # 在线查询模式主要处于上半部分,离线构建处于下半部分。Kylin技术架构如下:
~~~ 数据源主要是Hadoop Hive,数据以关系表的形式输入,保存着待分析的数据。
~~~ 根据元数据的定义,构建引擎从数据源抽取数据,并构建Cube
~~~ Kylin可以使用 MapReduce 或 Spark 作为构建引擎。
~~~ 构建后的Cube保存在右侧的存储引擎中,一般选用HBase作为存储
~~~ 完成了离线构建后,用户可以从查询系统发送SQL进行查询分析
~~~ Kylin提供了各种Rest API、JDBC/ODBC接口。
~~~ 无论从哪个接口进入,SQL最终都会来到Rest服务层,再转交给查询引擎进行处理~~~ # SQL语句是基于数据源的关系模型书写的,而不是Cube
~~~ Kylin在设计时,刻意对查询用户屏蔽了Cube的概念
~~~ 只需要理解关系模型就可以使用Kylin,没有额外的学习门槛,传统的SQL应用也很容易迁移
~~~ 查询引擎解析SQL,生成基于关系表的逻辑执行计划,然后将其转换为基于Cube的物理执行计划,
~~~ 最后查询预计算生成的Cube并产生结果,整个过程不会访问原始数据源### --- 组件的功能:
~~~ # REST Server:
~~~ 提供 Restful 接口,例如创建、构建、刷新、合并等 Cube 相关操作,
~~~ Kylin 的 Projects、Tables 等元数据管理,用户访问权限控制,SQL 的查询等~~~ # Query Engine:
~~~ 使用开源的 Apache Calcite 框架来实现 SQL 解析,可以理解为 SQL 引擎层
~~~ # Routing:
~~~ 负责将解析 SQL 生成的执行计划转换成 Cube 缓存的查询,
~~~ 这部分查询是可以在秒级甚至毫秒级完成~~~ # Metadata:
~~~ Kylin 中有大量的元数据信息,
~~~ 包括 Cube 的定义、星型模型的定义、Job 和执行 Job 的输出信息、模型的维度信息等等,
~~~ Kylin 的元数据和 Cube 都存储在 HBase 中,存储的格式是 json 字符串
~~~ # Cube Build Engine:
~~~ 所有模块的基础,它主要负责 Kylin 预计算中创建 Cube,
~~~ 创建的过程是首先通过 Hive 读取原始数据,
~~~ 然后通过一些 MapReduce 或 Spark 计算生成 Htable,最后将数据 load 到 HBase 表中六、工作原理
### --- Apache Kylin的工作原理是对数据模型做Cube预计算,并利用计算的结果加速查询。具体工作过程如下:
~~~ 指定数据模型,定义维度和度量
~~~ 预计算Cube,计算所有Cuboid并保存为物化视图(存储到HBase中)
~~~ 执行查询时,读取Cuboid,计算并产生查询结果### --- 高效OLAP分析:
~~~ Kylin的查询过程不会扫描原始记录,而是通过预计算预先完成表的关联、聚合等复杂运算
~~~ 利用预计算的结果来执行查询,相比非预计算的查询技术,
~~~ 其速度一般要快一到两个数量级,在超大的数据集上优势更明显
~~~ 数据集达到千亿乃至万亿级别时,Kylin的速度可以超越其他非预计算技术1000倍以上七、Kylin生态
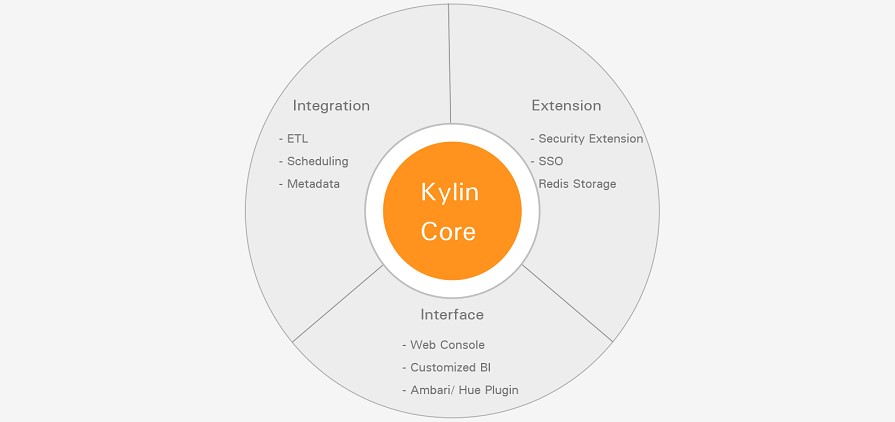
### --- Kylin生态
~~~ Apache Kylin核心:Kylin的OALP 引擎由元数据引擎、查询引擎、任务引擎、存储引擎组成。
~~~ 另外它还有一个 REST 服务器对外提供查询请求的服务
~~~ 可扩展性:提供插件机制支持额外的特性和功能
~~~ 与其他系统的整合:可整合任务调度器,ETL工具、监控及告警系统
~~~ 驱动包(Drivers):提供ODBC、JDBC驱动支持与其他工具(如Tableau)的整合Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv023-kylin



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)