

|NO.Z.00008|——————————|BigDataEnd|——|Hadoop&OLAP_ClickHouse.V05|——|ClickHouse.v05|表引擎|MergeTree|索引|
一、索引:一级索引
### --- 一级索引
~~~ 文件:primary.idx
~~~ MergeTree的主键使用Primary Key定义,主键定义之后,
~~~ MergeTree会根据index_granularity间隔(默认8192)为数据生成一级索引并保存至primary.idx文件中。
~~~ 这种方式是稀疏索引
~~~ 简化形式:通过order by指代主键~~~ # 稀疏索引
~~~ primary.idx文件的一级索引采用稀疏索引。
~~~ 稠密索引:每一行索引标记对应一行具体的数据记录
~~~ 稀疏索引:每一行索引标记对应一段数据记录(默认索引粒度为8192)### --- 密集索引和稀疏索引的区别
~~~ 稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存,取用速度快!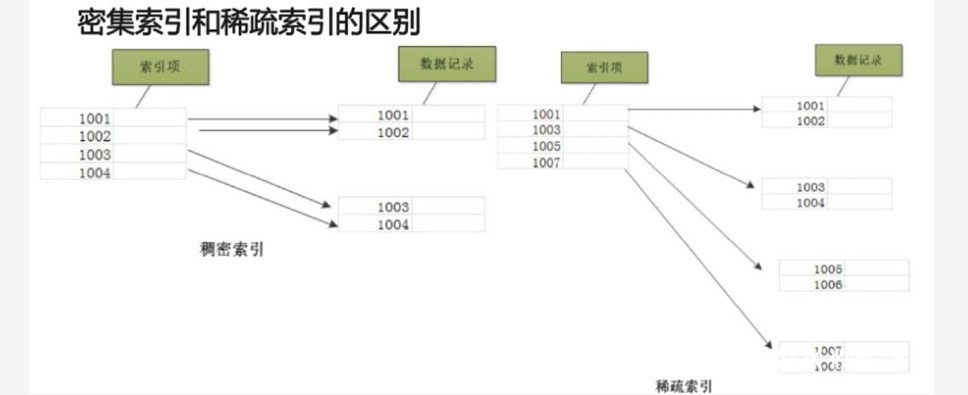
~~~ # 索引粒度
~~~ index_granularity参数,表示索引粒度。新版本中clickhouse提供了自适应索引粒度。
~~~ # 索引粒度在MergeTree引擎中很重要。
~~~ 索引数据的生成规则
~~~ 借助hits_v1表中的真实数据观察:
~~~ # primary.idx文件
~~~ 由于稀疏索引,所以MergeTree要间隔index_granularity行数据才会生成一个索引记录,
~~~ 其索引值会根据声明的主键字段获取。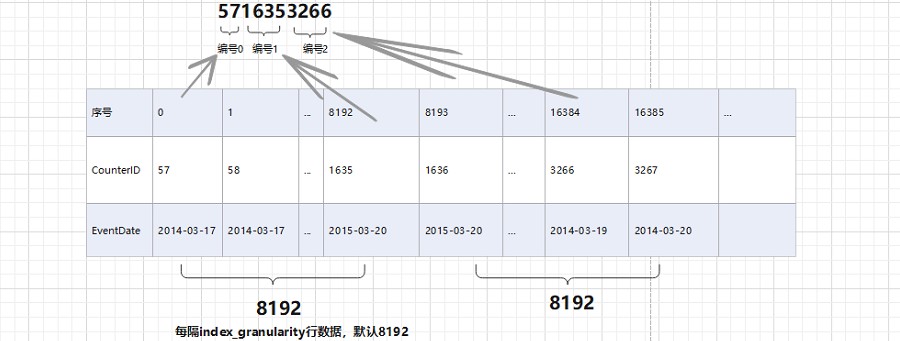
~~~ # 索引的查询过程
~~~ 索引是如何工作的?对primary.idx文件的查询过程
~~~ # MarkRange:一小段数据区间
~~~ 按照index_granularity的间隔粒度,将一段完整的数据划分成多个小的数据段,小的数据段就是MarkRange,MarkRange与索引编号对应。### --- 案例:
~~~ 共200行数据
~~~ index_granularity大小为5
~~~ 主键ID为Int,取值从0开始
~~~ 根据索引生成规则,primary.idx文件内容为:05101520253035404550...200
~~~ 共200行数据 / 5 = 40个MarkRange
~~~ 索引查询 where id = 3
~~~ 第一步:形成区间格式: [3,3]
~~~ 第二步:进行交集 [3,3]∩[0,199]
~~~ 以MarkRange的步长大于8分块,进行剪枝
~~~ 第三步:合并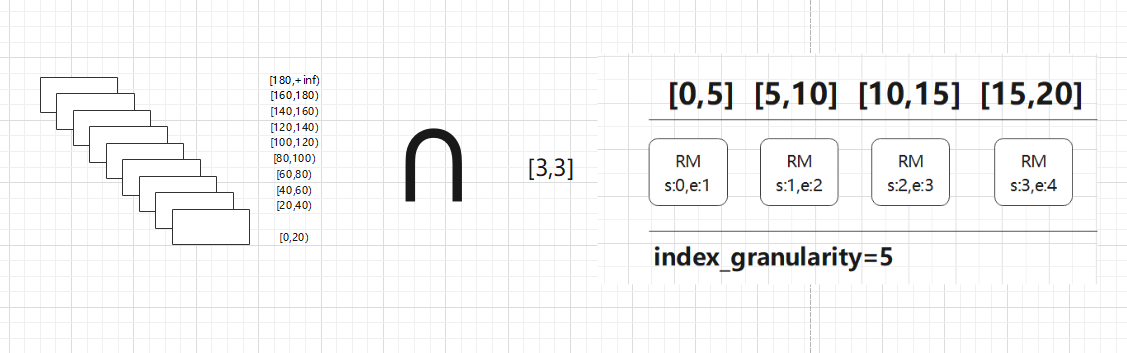
### --- MarkRange:(start0,end 20)
~~~ 在ClickHouse中,MergeTree引擎表的索引列在建表时使用ORDER BY语法来指定。
~~~ 而在官方文档中,用了下面一幅图来说明。
~~~ 这张图示出了以CounterID、Date两列为索引列的情况,即先以CounterID为主要关键字排序,
~~~ 再以Date为次要关键字排序,最后用两列的组合作为索引键。
~~~ marks与mark numbers就是索引标记,
~~~ 且marks之间的间隔就由建表时的索引粒度参数index_granularity来指定,默认值为8192。
~~~ # ClickHouse MergeTree引擎表中,每个part的数据大致以下面的结构存储。
~~~ . ├── business_area_id.bin ├── business_area_id.mrk2 ├── coupon_money.bin ├── coupon_money.mrk2├── groupon_id.bin ├── groupon_id.mrk2 ├── is_new_order.bin ├── is_new_order.mrk2 … ├── primary.idx… 其中,
~~~ bin文件存储的是每一列的原始数据(可能被压缩存储),
~~~ mrk2文件存储的是图中的mark numbers与bin文件中数据位置的映射关系。
~~~ 另外,还有一个primary.idx文件存储被索引列的具体数据。
~~~ 另外,每个part的数据都存储在单独的目录中,目录名形如20200708_92_121_7,
~~~ 即包含了分区键、起始mark number和结束marknumber,方便定位。~~~ # 在ClickHouse之父Alexey Milovidov分享的PPT中,有更加详细的图示。
~~~ 这样,每一列都通过ORDER BY列进行了索引。
~~~ 查询时,先查找到数据所在的parts,再通过mrk2文件确定bin文件中数据的范围即可。
~~~ 不过,ClickHouse的稀疏索引与Kafka的稀疏索引不同,可以由用户自由组合多列,
~~~ 因此也要格外注意不要加入太多索引列,防止索引数据过于稀疏,增大存储和查找成本。
~~~ 另外,基数太小(即区分度太低)的列不适合做索引列,
~~~ 因为很可能横跨多个mark的值仍然相同,没有索引的意义了。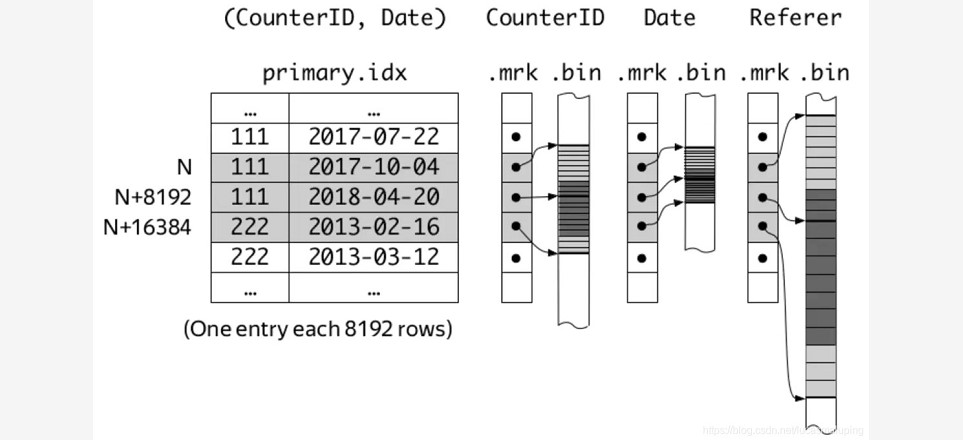
二、跳数索引
### --- granularity和index_granularity的关系
~~~ index_granularity定义了数据的粒度 granularity定义了聚合信息汇总的粒度 换言之,
~~~ granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据~~~ # 索引的可用类型
~~~ minmax 存储指定表达式的极值(如果表达式是 tuple ,则存储 tuple 中每个元素的极值),
~~~ 这些信息用于跳过数据块,类似主键。
~~~ set(max_rows) 存储指定表达式的惟一值(不超过 max_rows 个,max_rows=0
~~~ 则表示『无限制』)。这些信息可用于检查 WHERE 表达式是否满足某个数据块。
~~~ ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
~~~ 存储包含数据块中所有 n 元短语的 布隆过滤器 。只可用在字符串上。
~~~ 可用于优化 equals , like 和 in 表达式的性能。
~~~ n – 短语长度。 size_of_bloom_filter_in_bytes – 布隆过滤器大小,
~~~ 单位字节。(因为压缩得好,可以指定比较大的值,如256或512)。
~~~ number_of_hash_functions – 布隆过滤器中使用的 hash 函数的个数。
~~~ random_seed –hash 函数的随机种子。
~~~ tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
~~~ 跟 ngrambf_v1 类似,不同于 ngrams 存储字符串指定长度的所有片段。
~~~ 它只存储被非字母数据字符分割的片段。### --- granularity和index_granularity的关系示例
hadoop01 :) INDEX sample_index (u64 * length(s)) TYPE minmax GRANULARITY 4
hadoop01 :) INDEX sample_index2 (u64 * length(str), i32 + f64 * 100, date, str) TYPE set(100) GRANULARITY 4
hadoop01 :) INDEX sample_index3 (lower(str), str) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 4Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通