

|NO.Z.00047|——————————|BigDataEnd|——|Hadoop&Flink.V02|——|Flink.v02|Flink Connector|kafka|源码理解|源码示例|
一、Flink-Connector (Kafka)
### --- 源码理解
~~~ # Funtion:UDF---处理数据的逻辑
~~~ RichFunction: open/close 管理函数的生命周期的方法 ...RunTimeContext函数的运行时上下文
~~~ SourceFunction: 提供了自定义数据源的功能,run方法是获取数据的方法
~~~ ParallelSourceFunction: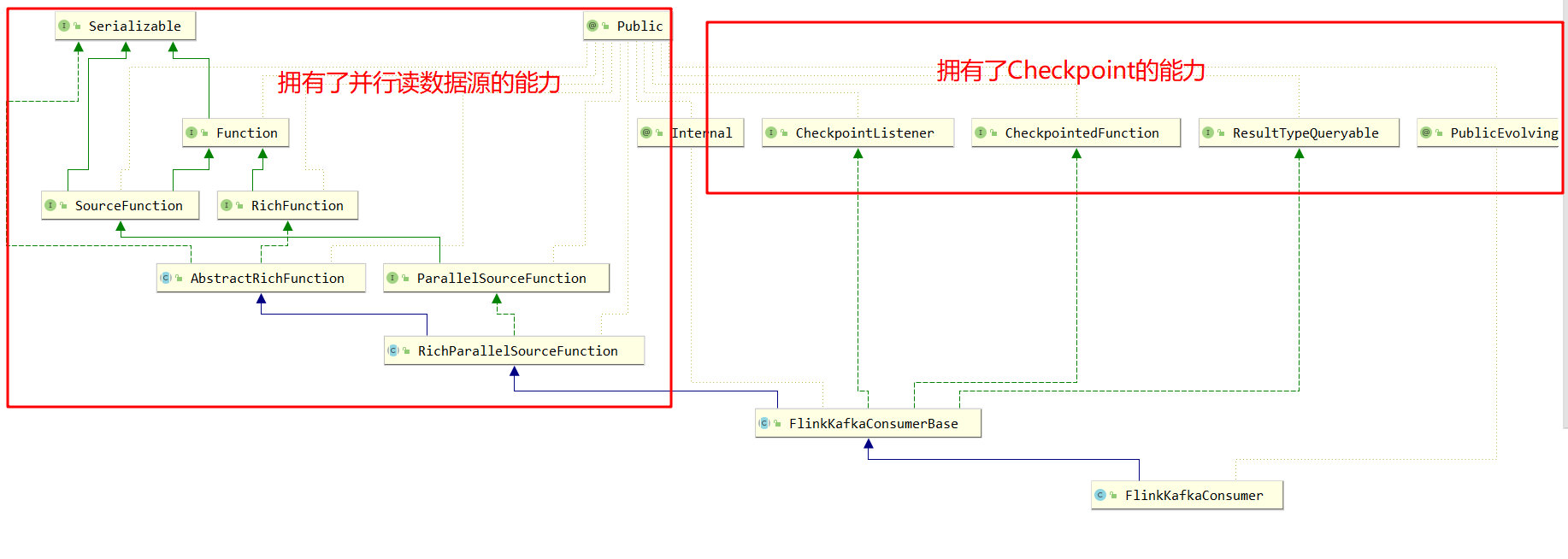
### --- 创建一个新的流数据源消费者
~~~ Flink Kafka Consumer是一个流数据源,它从Apache Kafka提取并行数据流。
~~~ 使用者可以在多个并行实例中运行,每个实例将从一个或多个Kafka分区提取数据。
~~~ Flink Kafka消费者参与检查点并保证没有数据丢失
~~~ 当出现故障时,计算过程只处理一次元素。
~~~ (注:这些保证自然假设Kafka本身不会丢失任何数据。)
~~~ 请注意,Flink在内部快照偏移量,将其作为分布式检查点的一部分。
~~~ 提交到kafka上的offset只是为了使外部的outside view of progress与Flink的view of progress同步。
~~~ 通过这种方式,监视和其他工作可以了解Flink Kafka消费者在某个主题上消费了多少数据。
~~~ # FlinkKafkaConsumerBase:
~~~ 所有Flink Kafka Consumer数据源的基类。这个类实现了所有Kafka版本的公共行为
~~~ 回顾自定义数据源---二、编程实现
### --- open方法和run方法
~~~ # FlinkKafkaConsumerBase.java
open(Configuration:void AbstractRichFunction
run (SourceContext<T>):void SourceFunction### --- 编程实现:Flink-Kafka-Consumer:
package com.yanqi.streamdatasource;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.executiongraph.restart.RestartStrategy;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.runtime.state.memory.MemoryStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.internals.KafkaTopicPartition;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Properties;
public class SourceFromKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000);
long checkpointInterval = env.getCheckpointConfig().getCheckpointInterval();
System.out.println("checkpointInterval:" + checkpointInterval + "..." + env.getCheckpointConfig().getCheckpointingMode());
CheckpointConfig config = env.getCheckpointConfig();
// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】
config.setMinPauseBetweenCheckpoints(500);
// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】
config.setCheckpointTimeout(60000);
// 同一时间只允许进行一个检查点
config.setMaxConcurrentCheckpoints(1);
// env.setRestartStrategy(new RestartStrategies.NoRestartStrategyConfiguration());
// 设置模式为exactly-once
config.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 设置checkpoint的周期, 每隔1000 ms进行启动一个检查点
config.setCheckpointInterval(1000);
long checkpointInterval1 = config.getCheckpointInterval();
System.out.println("......after:" + checkpointInterval1);
// 任务流取消和故障时会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint,即退出后不删除checkpoint
config.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// String checkPointPath = new Path("hdfs://");
//FsStateBackend fsStateBackend = new FsStateBackend(new Path("hdfs:hadoop01:9000/flink/checkpoints"));
//env.setStateBackend(fsStateBackend);
// env.setStateBackend(new MemoryStateBackend());
String topic = "lucasone";
Properties props = new Properties();
props.setProperty("bootstrap.servers","hadoop02:9092");
props.setProperty("group.id","mygp");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>(topic, new SimpleStringSchema(), props);
consumer.setStartFromGroupOffsets();
consumer.setCommitOffsetsOnCheckpoints(true);
// consumer.setStartFromLatest();
// consumer.setStartFromEarliest();
//从指定offset位置开始消费
/*HashMap<KafkaTopicPartition, Long> specifiStartOffsets = new HashMap<>();
specifiStartOffsets.put(new KafkaTopicPartition("animal",0),558L);
// specifiStartOffsets.put(new KafkaTopicPartition("animal",1),0L);
// specifiStartOffsets.put(new KafkaTopicPartition("animal",2),43L);
consumer.setStartFromSpecificOffsets(specifiStartOffsets);*/
DataStreamSource<String> data = env.addSource(consumer);
int parallelism = data.getParallelism();
System.out.println("...parallelism" + parallelism);
SingleOutputStreamOperator<Tuple2<Long, Long>> maped = data.map(new MapFunction<String, Tuple2<Long, Long>>() {
@Override
public Tuple2<Long, Long> map(String value) throws Exception {
System.out.println(value);
Tuple2<Long,Long> t = new Tuple2<Long,Long>( 0L, 0L );
String[] split = value.split(",");
try{
t = new Tuple2<Long, Long>(Long.valueOf(split[0]), Long.valueOf(split[1]));
} catch (Exception e) {
e.printStackTrace();
}
return t;
}
});
KeyedStream<Tuple2<Long,Long>, Long> keyed = maped.keyBy(value -> value.f0);
/*SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndeOne = data.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String word : s.split(",")) {
collector.collect(new Tuple2<String, Integer>(word, 1));
}
}
});*/
/*KeyedStream<Tuple2<String, Integer>, String> tuple2StringKeyedStream = wordAndeOne.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});*/
// SingleOutputStreamOperator<Tuple2<String, Integer>> result = tuple2StringKeyedStream.sum(1);
// result.print();
//按照key分组策略,对流式数据调用状态化处理
SingleOutputStreamOperator<Tuple2<Long, Long>> flatMaped = keyed.flatMap(new RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>>() {
ValueState<Tuple2<Long, Long>> sumState;
@Override
public void open(Configuration parameters) throws Exception {
//在open方法中做出State
ValueStateDescriptor<Tuple2<Long, Long>> descriptor = new ValueStateDescriptor<>(
"average",
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {
}),
Tuple2.of(0L, 0L)
);
sumState = getRuntimeContext().getState(descriptor);
// super.open(parameters);
}
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Long>> out) throws Exception {
//在flatMap方法中,更新State
Tuple2<Long, Long> currentSum = sumState.value();
currentSum.f0 += 1;
currentSum.f1 += value.f1;
sumState.update(currentSum);
out.collect(currentSum);
/*if (currentSum.f0 == 2) {
long avarage = currentSum.f1 / currentSum.f0;
out.collect(new Tuple2<>(value.f0, avarage));
sumState.clear();
}*/
}
});
flatMaped.print();
env.execute();
}
}Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv020-flink



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY