

|NO.Z.00040|——————————|BigDataEnd|——|Hadoop&Flink.V07|——|Flink.v07|Flink State|状态原理|原理剖析|状态存储|Keyed State|Operator State|
一、Keyed State & Operator State
### --- state 分类
~~~ # Operator State (或者non-keyed state )
~~~ 每个 Operator state 绑定一个并行 Operator 实例。
~~~ Kafka Connector 是使用 Operator state 的典型示例:
~~~ 每个并行的 kafka consumer 实例维护了每个 kafka topic 分区和该分区 offset 的映射关系,
~~~ 并将这个映射关系保存为 Operator state。
~~~ 在算子并行度改变时,Operator State 也会重新分配。~~~ # Keyed State
~~~ 这种 State 只存在于 KeyedStream 上的函数和操作中,
~~~ 比如 Keyed UDF(KeyedProcessFunction…) window state 。
~~~ 可以把 Keyed State 想象成被分区的 Operator State。
~~~ 每个 Keyed State 在逻辑上可以看成与一个 <parallel-Operator-instance, key> 绑定,
~~~ 由于一个 key 肯定只存在于一个 Operator 实例,
~~~ 所以我们可以简单的认为一个 <operaor, key> 对应一个 Keyed State。### --- 每个 Keyed State 在逻辑上还会被分配到一个 Key Group。分配方法如下:
~~~ # maxParallelism 为最大并行度
MathUtils.murmurHash(key.hashCode()) % maxParallelism;~~~ 其中 maxParallelism 是 flink 程序的最大并行度,这个值一般我们不会去手动设置,
~~~ 使用默认的值(128)就好,这里注意下,
~~~ maxParallelism 和我们运行程序时指定的算子并行度(parallelism)不同,
~~~ parallelism 不能大于 maxParallelism ,parallelism 最多只能设置为 maxParallelism 。~~~ # 为什么会有 Key Group 这个概念呢?
~~~ 举个栗子,我们通常写程序,会给算子指定一个并行度,运行一段时间后,
~~~ 积累了一些 state ,这时候数据量大了,需要增大并行度;
~~~ 我们修改并行度后重新提交,那这些已经存在的 state 该如何分配到各个 Operator 呢?
~~~ 这就有了最大并行度(maxParallelism ) 和 Key Group 的概念。
~~~ 上面计算 Key Group 的公式也说明了 Key Group 的个数最多是 maxParallelism 个。### --- 当并行度更改后,我们再计算这个 key 被分配到的 Operator:
~~~ 可以看到, 一个 keyGroupId 会对应到一个 Operator,当并行度更改时,
~~~ 新的 Operator 会去拉取对应 Key Group 的 Keyed State,
~~~ 这样就把 KeyedState 尽量均匀地分配给所有的 Operator 啦!
keyGroupId * parallelism / maxParallelism;### --- 根据 state 数据是否被 flink 托管,flink 又将 state 分类为 managed state 和 raw state:
~~~ managed state: 被 flink 托管,保存为内部的哈希表或者 RocksDB; checkpoint 时,
~~~ flink 将 state进行序列化编码。例如 ValueState ListState…
~~~ raw state: Operator 自行管理的数据结构,checkpoint 时,它们只能以 byte 数组写入checkpoint。
~~~ 当然建议使用 managed state 啦!使用 managed state 时,
~~~ flink 会帮我们在更改并行度时重新分发state,并且优化内存。二、使用 managed keyed state
### --- 如何创建
~~~ # 上面提到,Keyed state 只能在 keyedStream 上使用,可以通过 stream.keyBy(…) 创建keyedStream。
~~~ # 我们可以创建以下几种 keyed state:
ValueState
ListState
ReducingState
AggregatingState<IN, OUT>
MapState<UK, UV>
FoldingState<T, ACC>~~~ # 每种 state 都对应各自的描述符,通过描述符从 RuntimeContext 中获取对应的 State,
~~~ # 而RuntimeContext 只有 RichFunction 才能获取,所以要想使用 keyed state,
~~~ # 用户编写的类必须继承RichFunction 或者其子类。
ValueState getState(ValueStateDescriptor)
ReducingState getReducingState(ReducingStateDescriptor)
ListState getListState(ListStateDescriptor)
AggregatingState<IN, OUT> getAggregatingState(AggregatingStateDescriptor<IN, ACC, OUT>)
FoldingState<T, ACC> getFoldingState(FoldingStateDescriptor<T, ACC>)
MapState<UK, UV> getMapState(MapStateDescriptor<UK, UV>)### --- 给 keyed state 设置过期时间
~~~ flink-1.6.0 以后,我们还可以给 Keyed state 设置 TTL(Time-To-Live),
~~~ 当某一个 key 的 state 数据过期时,会被 statebackend 尽力删除。
~~~ 官方给出了使用示例:~~~ # 简单来说就是在创建状态描述符时,添加 StateTtlConfig 配置,
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1)) # 状态存活时间
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) # TTL 何时被更新,这里配置的 state 创建和写入时
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build(); # 设置过期的 state 不被读取
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);### --- state 的 TTL 何时被更新?
~~~ # 可以进行以下配置,默认只在 key 的 state 被 modify(创建或更新) 的时候才更新 TTL:
~~~ StateTtlConfig.UpdateType.OnCreateAndWrite: 只在一个 key 的 state 创建和写入时更新TTL(默认)
~~~ StateTtlConfig.UpdateType.OnReadAndWrite: 读取 state 时仍然更新 TTL
~~~ 当 state 过期但是还未删除时,这个状态是否还可见?~~~ # 可以进行以下配置,默认是不可见的:
~~~ StateTtlConfig.StateVisibility.NeverReturnExpired: 不可见(默认)
~~~ StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp: 可见~~~ # 注意:
~~~ 状态的最新访问时间会和状态数据保存在一起,所以开启 TTL 特性会增大 state 的大小。
~~~ Heapstate backend 会额外存储一个包括用户状态以及时间戳的 Java 对象,
~~~ RocksDB state backend会在每个状态值(list 或者 map 的每个元素)序列化后增加 8 个字节。
~~~ 暂时只支持基于 processing time 的 TTL。
~~~ 尝试从 checkpoint/savepoint 进行恢复时,TTL 的状态(是否开启)必须和之前保持一致,
~~~ 否则会遇到 “StateMigrationException”。
~~~ TTL 的配置并不会保存在 checkpoint/savepoint 中,仅对当前 Job 有效。
~~~ 当前开启 TTL 的 map state 仅在用户值序列化器支持 null 的情况下,才支持用户值为 null。
~~~ 如果用户值序列化器不支持 null, 可以用 NullableSerializer 包装一层。~~~ # 过期的 state 何时被删除?
~~~ 默认情况下,过期的 state 数据只有被显示读取的时候才会被删除,
~~~ 例如,调用 ValueState.value()时。
~~~ 注意:如果过期的数据如果之后不被读取,那么这个过期数据就不会被删除,
~~~ 可能导致状态不断增大。### --- 目前有两种方式解决这个问题:
~~~ # 从全量快照恢复时删除:可以配置从全量快照恢复时删除过期数据:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1)) # state 存活时间,这里设置的 1 秒过期
.cleanupFullSnapshot()
.build();~~~ 局限是正常运行的程序的过期状态还是无法删除,
~~~ 全量快照时,过期状态还是被备份了,只是在从上一个快照恢复时会过滤掉过期数据。
~~~ 注意:使用 RocksDB 增量快照时,该配置无效。
~~~ 这种清理方式可以在任何时候通过 StateTtlConfig 启用或者关闭,比如在从 savepoint 恢复时。### --- 后台程序删除(flink-1.8 之后的版本支持)
~~~ flink-1.8 引入了后台清理过期 state 的特性,通过 StateTtlConfig 开启,
~~~ 显式调用cleanupInBackground(),使用示例如下:import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1)) # state 存活时间,这里设置的 1 秒过期
.cleanupInBackground()
.build();~~~ # 官方介绍,
~~~ 使用 cleanupInBackground() 时,
~~~ 可以让不同 statebackend 自动选择cleanupIncrementally(heap state backend)
~~~ 或者 cleanupInRocksdbCompactFilter(rocksdb state backend) 策略进行后台清理。
~~~ 也就是说,不同的 statebackend 的具体清理过期 state 原理也是不一样的。
~~~ 而且,配置为 cleanupInBackground() 时,只能使用默认配置的参数。
~~~ 想要更改参数时,需要显式配置上面提到的两种清理方式,并且要和 statebackend 对应:~~~ # heap state backend 支持的增量清理
~~~ 在状态访问或处理时进行。
~~~ 如果某个状态开启了该清理策略,则会在存储后端保留一个所有状态的惰性全局迭代器。
~~~ 每次触发增量清理时,从迭代器中选择已经过期的进行清理。
~~~ 通过StateTtlConfig 配置,显式调用 cleanupIncrementally():import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupIncrementally(10, true)
.build();~~~ # 使用 cleanupIncrementally() 策略时,当 state 被访问时会触发清理逻辑。
~~~ cleanupIncrementally() 包含两个参数:
~~~ 第一个参数表示每次清理被触发时,要检查的 state 条目个数;
~~~ 第二个参数表示是否在每条数据被处理时都触发清理逻辑。
~~~ 如果使用 cleanupInBackground() 的话,这里的默认值是(5, false)。### --- 还有以下几点需要注意:
~~~ 如果没有 state 访问,也没有处理数据,则不会清理过期数据。
~~~ 增量清理会增加数据处理的耗时。
~~~ 现在仅 Heap state backend 支持增量清除机制。在 RocksDB state backend 上启用该特性无效。
~~~ 如果 Heap state backend 使用同步快照方式,则会保存一份所有 key 的拷贝,
~~~ 从而防止并发修改问题,因此会增加内存的使用。但异步快照则没有这个问题。
~~~ 对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,
~~~ 比如从savepoint 重启后。
~~~ RocksDB 进行 compaction(压缩合并) 时清理
~~~ 如果使用 RocksDB state backend,可以使用 Flink 为 RocksDB 定制的 compaction filter。
~~~ RocksDB 会周期性的对数据进行异步合并压缩从而减少存储空间。
~~~ Flink 压缩过滤器会在压缩时过滤掉已经过期的状态数据。
~~~ 该特性默认是关闭的,可以通过 Flink 的配置项
~~~ state.backend.rocksdb.ttl.compaction.filter.enabled 或者调用
~~~ RocksDBStateBackend::enableTtlCompactionFilter 启用该特性。
~~~ 然后通过如下方式让任何具有TTL 配置的状态使用过滤器:import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build();### --- 使用这种策略需要注意:
~~~ 压缩时调用 TTL 过滤器会降低速度。
~~~ TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查。
~~~ 对于集合型状态类型(比如 list 和 map),会对集合中每个元素进行检查。
~~~ 对于元素序列化后长度不固定的列表状态,TTL 过滤器需要在每次 JNI 调用过程中,
~~~ 额外调用 Flink的 java 序列化器, 从而确定下一个未过期数据的位置。
~~~ 对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,
~~~ 比如从savepoint 重启后。三、使用 managed operator state
### --- 使用managed operator state
~~~ 我们可以通过实现 CheckpointedFunction 或 ListCheckpointed<T extends Serializable>
~~~ 接口来使用 managed operator state。
~~~ CheckpointedFunction
~~~ CheckpointedFunction 接口提供了访问 non-keyed state 的方法,需要实现如下两个方法:
void snapshotState(FunctionSnapshotContext context) throws Exception;
void initializeState(FunctionInitializationContext context) throws Exception;~~~ # 进行 checkpoint 时会调用 snapshotState()。
~~~ 用户自定义函数初始化时会调用 initializeState(),
~~~ 初始化包括第一次自定义函数初始化和从之前的 checkpoint 恢复。
~~~ 因此 initializeState() 不仅是定义不同状态类型初始化的地方,也需要包括状态恢复的逻辑。
~~~ 当前,managed operator state 以 list 的形式存在。
~~~ 这些状态是一个 可序列化 对象的集合 List,彼此独立,方便在改变并发后进行状态的重新分派。
~~~ 换句话说,这些对象是重新分配 non-keyed state 的最细粒度。
~~~ 根据状态的不同访问方式,有如下几种重新分配的模式:~~~ # Even-split redistribution:
~~~ 每个算子都保存一个列表形式的状态集合,整个状态由所有的列表拼接而成。
~~~ 当作业恢复或重新分配的时候,整个状态会按照算子的并发度进行均匀分配。
~~~ 比如说,算子 A 的并发读为 1,包含两个元素 element1 和 element2,当并发读增加为 2 时,
~~~ element1 会被分到并发 0 上,element2 则会被分到并发 1 上。~~~ # Union redistribution:
~~~ 每个算子保存一个列表形式的状态集合。整个状态由所有的列表拼接而成。
~~~ 当作业恢复或重新分配时,每个算子都将获得所有的状态数据。~~~ # ListCheckpointed
~~~ ListCheckpointed 接口是 CheckpointedFunction 的精简版,
~~~ 仅支持 even-split redistributuion 的 liststate。同样需要实现两个方法:
~~~ List<T> snapshotState(long checkpointId, long timestamp) throws Exception;
~~~ void restoreState(List<T> state) throws Exception;
~~~ snapshotState() 需要返回一个将写入到 checkpoint 的对象列表,
~~~ restoreState 则需要处理恢复回来的对象列表。如果状态不可切分,
~~~ 则可以在 snapshotState() 中返回Collections.singletonList(MY_STATE)。~~~ # OperatorState 示例:实现带状态的 Sink Function
~~~ 下面的例子中的 SinkFunction 在 CheckpointedFunction 中进行数据缓存,
~~~ 然后统一发送到下游,这个例子演示了列表状态数据的 event-split redistribution。
~~~ 希望订阅 checkpoint 成功消息的算子,
~~~ 可以参考 org.apache.flink.runtime.state.CheckpointListener接口。四、statebackend 如何保存 managed keyed/operator state
~~~ statebackend 如何保存 managed keyed/operator state
~~~ 上面我们详细介绍了三种 statebackend,
~~~ 那么这三种 statebackend 是如何托管 keyed state 和Operator state 的呢?
~~~ 参考很多资料并查阅源码后,感觉下面的图能简单明了的表示当前 flink state 的存储方式。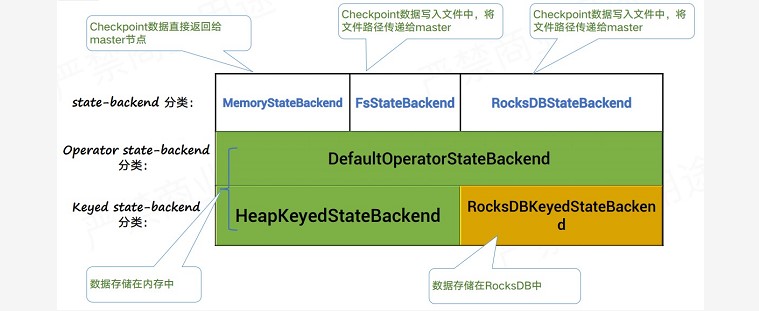
~~~ 在 flink 的实际实现中,对于同一种 statebackend,
~~~ 不同的 state 在运行时会有细分的 statebackend托管,
~~~ 例如 MemeoryStateBackend,就有 DefaultOperatorStateBackend 管理 Operator state,
~~~ HeapKeydStateBackend 管理 Keyed state。
~~~ 我们看到 MemoryStateBackend 和 FsStateBackend 对于 keyed state 和 Operator state 的
~~~ 存储都符合我们之前的理解,运行时 state 数据保存于内存,
~~~ checkpoint 时分别将数据备份在 jobmanager 内存和磁盘;
~~~ RocksDBStateBackend 运行时 Operator state 的保存位置需要注意下,并不是保存在 RocksDB 中,
~~~ 而是通过DefaultOperatorStateBackend 保存在 taskmanager 内存,创建源码如下:### --- RocksDBStateBackend.java
~~~ # 创建 keyed statebackend
public <K> AbstractKeyedStateBackend<K> createKeyedStateBackend(...){
...
return new RocksDBKeyedStateBackend<>(
...);
}
// 创建 Operator statebackend
public OperatorStateBackend createOperatorStateBackend(
Environment env,
String operatorIdentifier) throws Exception {
//the default for RocksDB; eventually there can be a operator state
backend based on RocksDB, too.
final boolean asyncSnapshots = true;
return new DefaultOperatorStateBackend(
...);
}~~~ 源码中也标注了,未来会提供基于 RocksDB 存储的 Operator state。
~~~ 所以当前即使使用RocksDBStateBackend, Operator state 也不能超过内存限制。
~~~ Operator State 在内存中对应两种数据结构:
~~~ ListState: 对应的实际实现类为 PartitionableListState,创建并注册的代码如下~~~ # DefaultOperatorStateBackend.java
private <S> ListState<S> getListState(...){
partitionableListState = new PartitionableListState<>(
new RegisteredOperatorStateBackendMetaInfo<>(
name,
partitionStateSerializer,
mode));
registeredOperatorStates.put(name, partitionableListState);
}~~~ # PartitionableListState 中通过 ArrayList 来保存 state 数据:
// PartitionableListState.java
/**
* The internal list the holds the elements of the state
*/
private final ArrayList<S> internalList;~~~ # BroadcastState: 对应的实际实现类为 HeapBroadcastState,创建并注册的代码如下
public <K, V> BroadcastState<K, V> getBroadcastState(...) {
broadcastState = new HeapBroadcastState<>(
new RegisteredBroadcastStateBackendMetaInfo<>(
name,
OperatorStateHandle.Mode.BROADCAST,
broadcastStateKeySerializer,
broadcastStateValueSerializer));
registeredBroadcastStates.put(name, broadcastState);
}~~~ # HeapBroadcastState 中通过 HashMap 来保存 state 数据:
/**
* The internal map the holds the elements of the state.
*/
private final Map<K, V> backingMap;
HeapBroadcastState(RegisteredBroadcastStateBackendMetaInfo<K, V>
stateMetaInfo) {
this(stateMetaInfo, new HashMap<>());
}### --- 我们对比下 HeapKeydStateBackend 和 RocksDBKeyedStateBackend 是如何保存 keyed state 的:
~~~ 对于 HeapKeydStateBackend , state 数据被保存在一个由多层 java Map 嵌套而成的数据结构中。
~~~ 这个图表示的是 window 中的 keyed state 保存方式,
~~~ 而 window-contents 是 flink 中 window 数据的state 描述符的名称,
~~~ 当然描述符类型是根据实际情况变化的。
~~~ 比如我们经常在 window 后执行聚合操作 (aggregate),
~~~ flink 就有可能创建一个名字为 window-contents 的 AggregatingStateDescriptor:| State | KeyGroup | Namespace | Key:Value |
| window-contents | 1 | Window(10,20) | K1:V11 |
| K2:V12 | |||
| Windows(15,25) | K1:V21 | ||
| K3:{V23:V24,...} | |||
| ... | |||
| ... | ... | ... |
~~~ # WindowedStream.java
AggregatingStateDescriptor<T, ACC, V> stateDesc = new
AggregatingStateDescriptor<>("window-contents", aggregateFunction,
accumulatorType.createSerializer(getExecutionEnvironment().getConfig()));~~~ # HeadKeyedStateBackend 会通过一个叫 StateTable 的数据结构,查找 key 对应的 StateMap:
// StateTable.java
/**
* Map for holding the actual state objects. The outer array represents the keygroups.
* All array positions will be initialized with an empty state map.
*/
protected final StateMap<K, N, S>[] keyGroupedStateMaps;~~~ # 根据是否开启异步 checkpoint,StateMap 会分别对应两个实现类:
~~~ CopyOnWriteStateMap<K, N, S>和 NestedStateMap<K, N, S>。
~~~ 对于 NestedStateMap,实际存储数据如下:
~~~ # NestedStateMap.java
private final Map<N, Map<K, S>> namespaceMap;~~~ # CopyOnWriteStateMap 是一个支持 Copy-On-Write 的 StateMap 子类,
~~~ 实际上参考了 HashMap 的实现,它支持渐进式哈希(incremental rehashing) 和异步快照特性。
~~~ 对于 RocksDBKeyedStateBackend,每个 state 存储在一个单独的 column family 内,
~~~ KeyGroup、key、namespace 进行序列化存储在 DB 作为 key,状态数据作为 value。Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv020-flink



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通