

|NO.Z.00082|——————————|BigDataEnd|——|Hadoop&Spark.V08|——|Spark.v08|Spark 原理 源码|Spark Context&Spark Context启动流程|
一、SparkContext启动流程
### --- sparkContext启动流程
~~~ SparkContext 涉及到的组件多,源码比较庞大。
~~~ 有些边缘性的模块主要起到辅助的功能,暂时省略。
~~~ 本文主要关心 SparkContext整体启动流程、三大组件的启动。
~~~ 初始化部分的代码主要集中在 363 - 592 行(Spark版本2.4.5)### --- 初始化步骤:
~~~ 1. 初始设置
~~~ 2. 创建 SparkEnv
~~~ 3. 创建 SparkUI
~~~ 4. Hadoop 相关配置
~~~ 5. Executor 环境变量
~~~ 6. 注册 HeartbeatReceiver 心跳接收器
~~~ 7. 创建 TaskScheduler、SchedulerBackend
~~~ 8. 创建和启动 DAGScheduler
~~~ 9. 启动TaskScheduler、SchedulerBackend
~~~ 10. 启动测量系统 MetricsSystem
~~~ 11. 创建事件日志监听器
~~~ 12. 创建和启动 ExecutorAllocationManager
~~~ 13. ContextCleaner 的创建与启动
~~~ 14. 自定义 SparkListener 与启动事件
~~~ 15. Spark 环境更新
~~~ 16. 投递应用程序启动事件
~~~ 17. 测量系统添加Source
~~~ 18. 将 SparkContext 标记为激活二、SparkContext启动流程
### --- 初始设置
~~~ SparkContext默认只有一个实例。要在 SparkConf 中设置 allowMultipleContexts 为 true;
~~~ 当存在多个active级别的SparkContext实例时Spark会发生警告,而不是抛出异常,要特别注意。~~~ # 源码提取说明:SparkContext.scala
~~~ # 82行~85行
// In order to prevent multiple SparkContexts from being active at the same time, mark this
// context as having started construction.
// NOTE: this must be placed at the beginning of the SparkContext constructor.
SparkContext.markPartiallyConstructed(this, allowMultipleContexts)~~~ 对SparkConf进行复制,然后对各种配置信息进行校验,
~~~ 最主要的就是SparkConf必须指定 spark.master(用于设置部署模式)
~~~ 和 spark.app.name(应用程序名称)属性,否则会抛出异常。~~~ # 源码提取说明:SparkContext.scala
~~~ # 363行~372行
try {
_conf = config.clone()
_conf.validateSettings()
if (!_conf.contains("spark.master")) {
throw new SparkException("A master URL must be set in your configuration")
}
if (!_conf.contains("spark.app.name")) {
throw new SparkException("An application name must be set in your configuration")
}### --- 创建 SparkEnv
~~~ SparkEnv是Spark的执行环境对象,
~~~ SparkEnv存在于Driver或者CoarseGrainedExecutorBackend进程中。~~~ # 源码提取说明:SparkContext.scala
~~~ # 423行~425行
// Create the Spark execution environment (cache, map output tracker, etc)
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)### --- 创建 SparkUI
~~~ SparkUI 提供了用浏览器访问具有样式及布局并且提供丰富监控数据的页面。
~~~ 其采用的是时间监听机制。发送的事件会存入缓存,
~~~ 由定时调度器取出后分配给监听此事件的监听器对监控数据进行更新。
~~~ 如果不需要SparkUI,则可以将spark.ui.enabled置为false。~~~ # 源码提取说明:SparkContext.scala
~~~ # 442行~452行
_ui =
if (conf.getBoolean("spark.ui.enabled", true)) {
Some(SparkUI.create(Some(this), _statusStore, _conf, _env.securityManager, appName, "",
startTime))
} else {
// For tests, do not enable the UI
None
}
// Bind the UI before starting the task scheduler to communicate
// the bound port to the cluster manager properly
_ui.foreach(_.bind())### --- Hadoop相关配置
~~~ 获取的配置信息包括:
~~~ 将Amazon S3文件系统的AWS_ACCESS_KEY_ID和 AWS_SECRET_ACCESS_KEY
~~~ 加载到Hadoop的Configuration;
~~~ 将SparkConf中所有的以 spark.hadoop 开头的属性都赋值到Hadoop的Configuration;
~~~ 将SparkConf的属性 spark.buffer.size 复制到Hadoop的Configuration的配置io.file.buffer.size;~~~ # 源码提取说明:SparkContext.scala
~~~ # 454行
_hadoopConfiguration = SparkHadoopUtil.get.newConfiguration(_conf)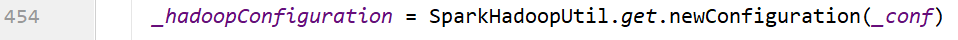
### --- Executor 环境变量
~~~ ExecutorEnvs包含的环境变量将会注册应用程序的过程中发送给Master,
~~~ Master给Worker发送调度后,Worker最终使用ExecutorEnvs提供的信息启动Executor。
~~~ 通过配置 spark.executor.memory 指定 Executor 占用的内存的大小,
~~~ 也可以配置系统变量SPARK_EXECUTOR_MEMORY或者SPARK_MEM设置其大小。~~~ # 源码提取说明:SparkContext.scala
~~~ # 465行~485行
_executorMemory = _conf.getOption("spark.executor.memory")
.orElse(Option(System.getenv("SPARK_EXECUTOR_MEMORY")))
.orElse(Option(System.getenv("SPARK_MEM"))
.map(warnSparkMem))
.map(Utils.memoryStringToMb)
.getOrElse(1024)
// Convert java options to env vars as a work around
// since we can't set env vars directly in sbt.
for { (envKey, propKey) <- Seq(("SPARK_TESTING", "spark.testing"))
value <- Option(System.getenv(envKey)).orElse(Option(System.getProperty(propKey)))} {
executorEnvs(envKey) = value
}
Option(System.getenv("SPARK_PREPEND_CLASSES")).foreach { v =>
executorEnvs("SPARK_PREPEND_CLASSES") = v
}
// The Mesos scheduler backend relies on this environment variable to set executor memory.
// TODO: Set this only in the Mesos scheduler.
executorEnvs("SPARK_EXECUTOR_MEMORY") = executorMemory + "m"
executorEnvs ++= _conf.getExecutorEnv
executorEnvs("SPARK_USER") = sparkUser### --- 注册 HeartbeatReceiver 心跳接收器
~~~ 在 Spark 的实际生产环境中,Executor 是运行在不同的节点上的。
~~~ 在 Local 模式 Driver 与 Executor 属于同一个进程,
~~~ 所以 Dirver 与 Executor 可以直接使用本地调用交互,
~~~ 当Executor 运行出现问题时,Driver 可以很方便地知道。
~~~ 在生产环境中,Driver 与 Executor 通常不在同一个进程内,运行在不同的节点上,
~~~ 甚至不同的机房里,为了能够掌控 Executor,在 Driver 中创建了这个心跳接收器。~~~ # 源码提取说明:SparkContext.scala
~~~ # 487行~490行
// We need to register "HeartbeatReceiver" before "createTaskScheduler" because Executor will
// retrieve "HeartbeatReceiver" in the constructor. (SPARK-6640)
_heartbeatReceiver = env.rpcEnv.setupEndpoint(
HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))### --- 创建和启动TaskScheduler、SchedulerBackend
~~~ TaskScheduler,负责任务的提交,并且负责发送任务到集群并运行它们,
~~~ 任务失败的重试,以及慢任务的在其他节点上重试。
~~~ 其中给应用程序分配并运行 Executor为一级调度,而给任务分配 Executor 并运行任务则为二级调度。
~~~ 另外 TaskScheduler 也可以看做任务调度的客户端。
~~~ 为 TaskSet创建和维护一个TaskSetManager并追踪任务的本地性以及错误信息;
~~~ 遇到Straggle 任务会方到其他的节点进行重试;
~~~ 向DAGScheduler汇报执行情况, 包括在Shuffle输出lost的时候报告fetch failed 错误等信息;
~~~ SchedulerBackend负责与Master、Worker通信收集Worker上分配给该应用使用的资源情况。~~~ # 源码提取说明:SparkContext.scala
~~~ # 492行~501行
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
_taskScheduler.start()### --- 创建和启动 DAGScheduler
~~~ DAGScheduler主要用于在任务正式交给TaskScheduler提交之前做一些准备工作,
~~~ 包括:创建Job,将DAG中的RDD划分到不同的Stage,提交Stage等。
~~~ DAGScheduler的数据结构主要维护 jobId 和 stageId 的关系、Stage、ActiveJob,
~~~ 以及缓存的RDD的Partition的位置信息。### --- 启动TaskScheduler、SchedulerBackend
~~~ # 源码提取说明:TaskSchedulerImpl.scala
~~~ # 180行~193行
def newTaskId(): Long = nextTaskId.getAndIncrement()
override def start() {
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
speculationScheduler.scheduleWithFixedDelay(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}### --- 启动测量系统 MetricsSystem
~~~ # MetricsSystem中三个概念:
~~~ Instance: 指定了谁在使用测量系统;
~~~ # Spark按照Instance的不同,分为Master、Worker、Application、Driver和Executor
~~~ Source: 指定了从哪里收集测量数据;~~~ # Source的有两种来源:Spark internal source: MasterSource / Worker Source等;
~~~ # Common source:JvmSource
~~~ Sink:指定了往哪里输出测量数据;
~~~ Spark目前提供的Sink有ConsoleSink、CsvSink、JmxSink、MetricsServlet、GraphiteSink等;
~~~ Spark使用MetricsServlet作为默认的Sink~~~ # MetricsSystem的启动过程包括:
~~~ 注册Sources
~~~ 注册Sinks
~~~ 将Sinks增加 Jetty 的ServletContextHandler
~~~ MetricsSystem启动完毕后,会遍历与Sinks有关的 ServletContextHandler,
~~~ 并调用 attachHandler将它们绑定到Spark UI上### --- 创建事件日志监听器
~~~ EventLoggingListener 是将事件持久化到存储的监听器,是 SparkContext 中可选组件。
~~~ 当spark.eventLog.enabled属性为 true 时启动,默认为 false。~~~ # 源码提取说明:sparkcontext.scala
~~~ # 518行~528行
_eventLogger =
if (isEventLogEnabled) {
val logger =
new EventLoggingListener(_applicationId, _applicationAttemptId, _eventLogDir.get,
_conf, _hadoopConfiguration)
logger.start()
listenerBus.addToEventLogQueue(logger)
Some(logger)
} else {
None
}### --- 创建和启动 ExecutorAllocationManager
~~~ 可选的组件,用于对以分配的Executor进行管理。
~~~ 默认情况下不会创建ExecutorAllocationManager,
~~~ 可以修改属性spark.dynamicAllocation.enabled为true来创建。
~~~ ExecutorAllocationManager可以动态的分配最小Executor的数量、
~~~ 动态分配最大Executor的数量、每个Executor可以运行的Task数量等配置信息,
~~~ 并对配置信息进行校验。
~~~ start方法将ExecutorAllocationListener加入listenerBus中,
~~~ ExecutorAllocationListener通过监听listenerBus里的事件,动态的添加、删除Executor。
~~~ 并且通过不断添加Executor,遍历Executor,将超时的Executor杀死并移除。~~~ # 源码提取说明:sparkcontext.scala
~~~ # 530行~545行
// Optionally scale number of executors dynamically based on workload. Exposed for testing.
val dynamicAllocationEnabled = Utils.isDynamicAllocationEnabled(_conf)
_executorAllocationManager =
if (dynamicAllocationEnabled) {
schedulerBackend match {
case b: ExecutorAllocationClient =>
Some(new ExecutorAllocationManager(
schedulerBackend.asInstanceOf[ExecutorAllocationClient], listenerBus, _conf,
_env.blockManager.master))
case _ =>
None
}
} else {
None
}
_executorAllocationManager.foreach(_.start())### --- ContextCleaner 的创建与启动
~~~ ContextCleaner用于清理超出应用范围的RDD、ShuffleDependency和Broadcast对象
~~~ referenceQueue: 缓存顶级的AnyRef引用
~~~ referenceBuff:缓存AnyRef的虚引用
~~~ listeners:缓存清理工作的监听器数组
~~~ cleaningThread:用于具体清理工作的线程~~~ # 源码提取说明:sparkcontext.scala
~~~ # 547行~553行
_cleaner =
if (_conf.getBoolean("spark.cleaner.referenceTracking", true)) {
Some(new ContextCleaner(this))
} else {
None
}
_cleaner.foreach(_.start())### --- 自定义 SparkListener 与启动
~~~ 添加用于自定义 SparkListener~~~ # 注册config的spark.extraListeners属性中指定的监听器,并启动监听器总线
setupAndStartListenerBus()
~~~ # 环境更新
postEnvironmentUpdate()
~~~ # 投递应用程序启动事件
postApplicationStart()~~~ # 源码提取说明:sparkcontext.scala
~~~ # 555行~557行
setupAndStartListenerBus()
postEnvironmentUpdate()
postApplicationStart()### --- Spark 环境更新
~~~ 在SparkContext的初始化过程中,可能对其环境造成影响,处理步骤,所以需要更新环境。
~~~ 通过调用 SparkEnv 的方法 environmentDetails,
~~~ 将环境的 JVM 参数、Spark 属性、系统属性、classPath 等信息设置为环境明细信息
~~~ 生成事件 SparkListenerEnvironmentUpdate(此事件携带环境明细信息),
~~~ 并投递到事件总线 listenerBus,此事件最终被 EnvironmentListener 监听,
~~~ 并影响 EnvironmentPage 页面中的输出内容。### --- 投递应用程序启动事件
~~~ 向listenerBus发送了SparkListenerApplicationStart事件### --- 测量系统添加Source
~~~ 先调用 taskScheduler.postStartHook 方法,等待backend就绪;
~~~ 创建 DAGSchedulerSource、BlockManagerSource和 ExecutorAllocationManagerSource;~~~ # 源码提取说明:sparkcontext.scala
~~~ # 559行~565行
// Post init
_taskScheduler.postStartHook()
_env.metricsSystem.registerSource(_dagScheduler.metricsSource)
_env.metricsSystem.registerSource(new BlockManagerSource(_env.blockManager))
_executorAllocationManager.foreach { e =>
_env.metricsSystem.registerSource(e.executorAllocationManagerSource)
}### --- 将 SparkContext 标记为激活
~~~ SparkContext初始化的最后将当前SparkContext的状态从contextBeingConstructed(正在构建中)
~~~ 改为activeContext(已激活)。~~~ # 源码提取说明:sparkcontext.scala
~~~ # 559行~565行
// In order to prevent multiple SparkContexts from being active at the same time, mark this
// context as having finished construction.
// NOTE: this must be placed at the end of the SparkContext constructor.
SparkContext.setActiveContext(this, allowMultipleContexts)Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv018-spark.v03



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通