

|NO.Z.00018|——————————|BigDataEnd|——|Hadoop&Spark.V06|——|Spark.v06|sparkcore|RDD编程&Key-Value RDD操作|
一、Key-Value RDD操作
### --- Key_Value RDD操作
~~~ RDD整体上分为 Value 类型和 Key-Value 类型。
~~~ 前面介绍的是 Value 类型的RDD的操作,
~~~ 实际使用更多的是 key-value 类型的RDD,也称为 PairRDD。
~~~ Value 类型RDD的操作基本集中在 RDD.scala 中;
~~~ key-value 类型的RDD操作集中在 PairRDDFunctions.scala 中;### --- 源码提取说明:
~~~ # 源码提取说明:RDD.scala
~~~ # 2004行
object RDD {
private[spark] val CHECKPOINT_ALL_MARKED_ANCESTORS =
"spark.checkpoint.checkpointAllMarkedAncestors"
// The following implicit functions were in SparkContext before 1.3 and users had to
// `import SparkContext._` to enable them. Now we move them here to make the compiler find
// them automatically. However, we still keep the old functions in SparkContext for backward
// compatibility and forward to the following functions directly.
implicit def rddToPairRDDFunctions[K, V](rdd: RDD[(K, V)])
(implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null): PairRDDFunctions[K, V] = {
new PairRDDFunctions(rdd)### --- 前面介绍的大多数算子对 Pair RDD 都是有效的。
~~~ Pair RDD还有属于自己的Transformation、Action 算子;二、创建Pair RDD
### --- 创建Pair RDD
scala> val arr = (1 to 10).toArray
arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> val arr1 = arr.map(x => (x, x*10, x*100))
arr1: Array[(Int, Int, Int)] = Array((1,10,100), (2,20,200), (3,30,300), (4,40,400), (5,50,500), (6,60,600), (7,70,700), (8,80,800), (9,90,900), (10,100,1000))~~~ # rdd1 不是 Pair RDD
scala> val rdd1 = sc.makeRDD(arr1)
rdd1: org.apache.spark.rdd.RDD[(Int, Int, Int)] = ParallelCollectionRDD[168] at makeRDD at <console>:26~~~ # rdd2 是 Pair RDD
scala> val arr2 = arr.map(x => (x, (x*10, x*100)))
arr2: Array[(Int, (Int, Int))] = Array((1,(10,100)), (2,(20,200)), (3,(30,300)), (4,(40,400)), (5,(50,500)), (6,(60,600)), (7,(70,700)), (8,(80,800)), (9,(90,900)), (10,(100,1000)))
scala> val rdd2 = sc.makeRDD(arr2)
rdd2: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = ParallelCollectionRDD[169] at makeRDD at <console>:26三、Transformation操作:类map操作
### --- 类似 map 操作
~~~ mapValues / flatMapValues / keys / values,
~~~ 这些操作都可以使用 map 操作实现,是简化操作。scala> val a = sc.parallelize(List((1,2),(3,4),(5,6)))
a: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[170] at parallelize at <console>:24~~~ # 使用 mapValues 更简洁
scala> val b = a.mapValues(x=>1 to x)
b: org.apache.spark.rdd.RDD[(Int, scala.collection.immutable.Range.Inclusive)] = MapPartitionsRDD[171] at mapValues at <console>:25
scala> b.collect
res84: Array[(Int, scala.collection.immutable.Range.Inclusive)] = Array((1,Range 1 to 2), (3,Range 1 to 4), (5,Range 1 to 6))~~~ # 可使用map实现同样的操作
scala> val b = a.map(x => (x._1, 1 to x._2))
b: org.apache.spark.rdd.RDD[(Int, scala.collection.immutable.Range.Inclusive)] = MapPartitionsRDD[172] at map at <console>:25
scala> b.collect
res85: Array[(Int, scala.collection.immutable.Range.Inclusive)] = Array((1,Range 1 to 2), (3,Range 1 to 4), (5,Range 1 to 6))
scala> val b = a.map{case (k, v) => (k, 1 to v)}
b: org.apache.spark.rdd.RDD[(Int, scala.collection.immutable.Range.Inclusive)] = MapPartitionsRDD[173] at map at <console>:25
scala> b.collect
res86: Array[(Int, scala.collection.immutable.Range.Inclusive)] = Array((1,Range 1 to 2), (3,Range 1 to 4), (5,Range 1 to 6))~~~ # flatMapValues 将 value 的值压平
scala> val c = a.flatMapValues(x=>1 to x)
c: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[174] at flatMapValues at <console>:25
scala> c.collect
res87: Array[(Int, Int)] = Array((1,1), (1,2), (3,1), (3,2), (3,3), (3,4), (5,1), (5,2), (5,3), (5,4), (5,5), (5,6))
scala> val c = a.mapValues(x=>1 to x).flatMap{case (k, v) => v.map(x
| => (k, x))}
~~~ 输出参数
c: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[176] at flatMap at <console>:25
scala> c.collect
res88: Array[(Int, Int)] = Array((1,1), (1,2), (3,1), (3,2), (3,3), (3,4), (5,1), (5,2), (5,3), (5,4), (5,5), (5,6))
scala> c.keys
res89: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[177] at keys at <console>:26
scala> c.values
res90: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[178] at values at <console>:26
scala> c.map{case (k, v) => k}.collect
res91: Array[Int] = Array(1, 1, 3, 3, 3, 3, 5, 5, 5, 5, 5, 5)
scala> c.map{case (k, _) => k}.collect
res92: Array[Int] = Array(1, 1, 3, 3, 3, 3, 5, 5, 5, 5, 5, 5)
scala> c.map{case (_, v) => v}.collect
res93: Array[Int] = Array(1, 2, 1, 2, 3, 4, 1, 2, 3, 4, 5, 6)四、聚合操作【重要、难点】
### --- 聚合操作
~~~ PariRDD(k, v)使用范围广,聚合
~~~ groupByKey / reduceByKey / foldByKey / aggregateByKey
~~~ combineByKey(OLD) / combineByKeyWithClassTag (NEW) => 底层实现
~~~ subtractByKey:类似于subtract,删掉 RDD 中键与 other RDD 中的键相同的元素
~~~ 小案例:给定一组数据:("spark", 12), ("hadoop", 26), ("hadoop", 23), ("spark",15), ("scala", 26),
~~~ ("spark", 25), ("spark", 23), ("hadoop", 16), ("scala", 24), ("spark",16), 键值对的key表示图书名称,value表示某天图书销量。计算每个键对应的平均值,也就是计算每种图书的每天平均销量。### --- 实验专题
scala> val rdd = sc.makeRDD(Array(("spark", 12), ("hadoop", 26),
| ("hadoop", 23), ("spark", 15), ("scala", 26), ("spark", 25),
| ("spark", 23), ("hadoop", 16), ("scala", 24), ("spark", 16)))
~~~ 输出参数
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[182] at makeRDD at <console>:24~~~ # groupByKey
scala> rdd.groupByKey().map(x=>(x._1,
| x._2.sum.toDouble/x._2.size)).collect
~~~ 输出参数
res94: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))
scala> rdd.groupByKey().map{case (k, v) => (k,
| v.sum.toDouble/v.size)}.collect
~~~ 输出参数
res95: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))
scala> rdd.groupByKey.mapValues(v => v.sum.toDouble/v.size).collect
res96: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))~~~ # reduceByKey
scala> rdd.mapValues((_, 1)).
| reduceByKey((x, y)=> (x._1+y._1, x._2+y._2)).
| mapValues(x => (x._1.toDouble / x._2)).
| collect()
~~~ 输出参数
res97: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))~~~ # foldByKey
scala> rdd.mapValues((_, 1)).foldByKey((0, 0))((x, y) => {
| (x._1+y._1, x._2+y._2)
| }).mapValues(x=>x._1.toDouble/x._2).collect
~~~ 输出参数
res98: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))~~~ # aggregateByKey
~~~ # aggregateByKey => 定义初值 + 分区内的聚合函数 + 分区间的聚合函数
scala> rdd.mapValues((_, 1)).
| aggregateByKey((0,0))(
| (x, y) => (x._1 + y._1, x._2 + y._2),
| (a, b) => (a._1 + b._1, a._2 + b._2)
| ).mapValues(x=>x._1.toDouble / x._2).
| collect
~~~ 输出参数
res99: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))~~~ # 初值(元祖)与RDD元素类型(Int)可以不一致
scala> rdd.aggregateByKey((0, 0))(
| (x, y) => {println(s"x=$x, y=$y"); (x._1 + y, x._2 + 1)},
| (a, b) => {println(s"a=$a, b=$b"); (a._1 + b._1, a._2 +
| b._2)}
| ).mapValues(x=>x._1.toDouble/x._2).collect
~~~ 输出参数
res100: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))~~~ # 分区内的合并与分区间的合并,可以采用不同的方式;这种方式是低效的!
scala> rdd.aggregateByKey(scala.collection.mutable.ArrayBuffer[Int]
| ())(
| (x, y) => {x.append(y); x},
| (a, b) => {a++b}
| ).mapValues(v => v.sum.toDouble/v.size).collect
~~~ 输出参数
res101: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))~~~ # combineByKey(理解就行)
scala> rdd.combineByKey(
| (x: Int) => {println(s"x=$x"); (x,1)},
| (x: (Int, Int), y: Int) => {println(s"x=$x, y=$y");(x._1+y,
| x._2+1)},
| (a: (Int, Int), b: (Int, Int)) => {println(s"a=$a, b=$b");
| (a._1+b._1, a._2+b._2)}
| ).mapValues(x=>x._1.toDouble/x._2).collect
~~~ 输出参数
res102: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))~~~ # subtractByKey
scala> val rdd1 = sc.makeRDD(Array(("spark", 12), ("hadoop", 26),
| ("hadoop", 23), ("spark", 15)))
~~~ 输出参数
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[204] at makeRDD at <console>:24
scala> val rdd2 = sc.makeRDD(Array(("spark", 100), ("hadoop", 300)))
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[205] at makeRDD at <console>:24
scala> rdd1.subtractByKey(rdd2).collect()
res103: Array[(String, Int)] = Array()~~~ # subtractByKey
scala> val rdd = sc.makeRDD(Array(("a",1), ("b",2), ("c",3), ("a",5),
| ("d",5)))
~~~ 输出参数
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[207] at makeRDD at <console>:24
scala> val other = sc.makeRDD(Array(("a",10), ("b",20), ("c",30)))
other: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[208] at makeRDD at <console>:24
scala> rdd.subtractByKey(other).collect()
res104: Array[(String, Int)] = Array((d,5))### --- 结论:效率相等用最熟悉的方法;groupByKey在一般情况下效率低,尽量少用初学:
~~~ 最重要的是实现;如果使用了groupByKey,寻找替换的算子实现;五、transformation操作说明
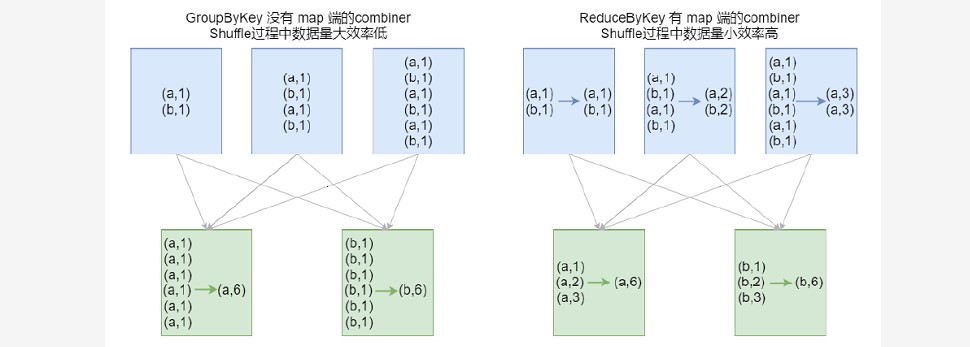
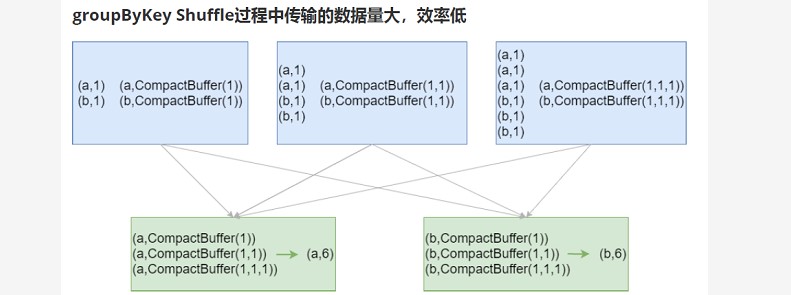
六、排序操作
### --- 排序操作
~~~ sortByKey:sortByKey函数作用于PairRDD,对Key进行排序。
~~~ 在org.apache.spark.rdd.OrderedRDDFunctions 中实现:~~~ # 源码提取说明:RDD.scala
~~~ # 2034行
implicit def rddToOrderedRDDFunctions[K : Ordering : ClassTag, V: ClassTag](rdd: RDD[(K, V)])
: OrderedRDDFunctions[K, V, (K, V)] = {
new OrderedRDDFunctions[K, V, (K, V)](rdd)
}~~~ # 源码提取说明:PairRDDFFunction.scala
~~~ # 59行
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)] = self.withScope
{
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}### --- 实验操作
scala> val a = sc.parallelize(List("wyp", "iteblog", "com", "397090770", "test"))
a: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[210] at parallelize at <console>:24
scala> val b = sc.parallelize (1 to a.count.toInt)
b: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[211] at parallelize at <console>:26
scala> val c = a.zip(b)
c: org.apache.spark.rdd.RDD[(String, Int)] = ZippedPartitionsRDD2[212] at zip at <console>:27
scala> c.sortByKey().collect
res105: Array[(String, Int)] = Array((397090770,4), (com,3), (iteblog,2), (test,5), (wyp,1))
scala> c.sortByKey(false).collect
res106: Array[(String, Int)] = Array((wyp,1), (test,5), (iteblog,2), (com,3), (397090770,4))六、join操作
### --- job操作
cogroup / join / leftOuterJoin / rightOuterJoin / fullOuterJoin### --- 源码提取说明
~~~ # 源码提取说明:PairRDDFunctions.scala
~~~ # 545行
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] = self.withScope {
this.cogroup(other, partitioner).flatMapValues( pair =>
for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w)
)
}### --- 实验操作
scala> val rdd1 = sc.makeRDD(Array((1,"Spark"), (2,"Hadoop"), (3,"Kylin"), (4,"Flink")))
rdd1: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[219] at makeRDD at <console>:24
scala> val rdd2 = sc.makeRDD(Array((3,"李四"), (4,"王五"), (5,"赵六"), (6,"冯七")))
rdd2: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[220] at makeRDD at <console>:24
scala> val rdd3 = rdd1.cogroup(rdd2)
rdd3: org.apache.spark.rdd.RDD[(Int, (Iterable[String], Iterable[String]))] = MapPartitionsRDD[222] at cogroup at <console>:27
scala> rdd3.collect.foreach(println)
~~~ 输出参数
(6,(CompactBuffer(),CompactBuffer(冯七)))
(3,(CompactBuffer(Kylin),CompactBuffer(李四)))
(4,(CompactBuffer(Flink),CompactBuffer(王五)))
(1,(CompactBuffer(Spark),CompactBuffer()))
(5,(CompactBuffer(),CompactBuffer(赵六)))
(2,(CompactBuffer(Hadoop),CompactBuffer()))
scala> rdd3.filter{case (_, (v1, v2)) => v1.nonEmpty &
| v2.nonEmpty}.collect
~~~ 输出参数
res108: Array[(Int, (Iterable[String], Iterable[String]))] = Array((3,(CompactBuffer(Kylin),CompactBuffer(李四))), (4,(CompactBuffer(Flink),CompactBuffer(王五))))~~~ # 仿照源码实现join操作
scala> rdd3.flatMapValues( pair =>
| for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w))
~~~ 输出参数
res109: org.apache.spark.rdd.RDD[(Int, (String, String))] = MapPartitionsRDD[224] at flatMapValues at <console>:26
scala> val rdd1 = sc.makeRDD(Array(("1","Spark"),("2","Hadoop"), ("3","Scala"),("4","Java")))
rdd1: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[225] at makeRDD at <console>:24
scala> val rdd2 = sc.makeRDD(Array(("3","20K"),("4","18K"), ("5","25K"),("6","10K")))
rdd2: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[226] at makeRDD at <console>:24
scala> rdd1.join(rdd2).collect
res110: Array[(String, (String, String))] = Array((3,(Scala,20K)), (4,(Java,18K)))
scala> rdd1.leftOuterJoin(rdd2).collect
res111: Array[(String, (String, Option[String]))] = Array((3,(Scala,Some(20K))), (4,(Java,Some(18K))), (1,(Spark,None)), (2,(Hadoop,None)))
scala> rdd1.rightOuterJoin(rdd2).collect
res112: Array[(String, (Option[String], String))] = Array((6,(None,10K)), (3,(Some(Scala),20K)), (4,(Some(Java),18K)), (5,(None,25K)))
scala> rdd1.fullOuterJoin(rdd2).collect
res113: Array[(String, (Option[String], Option[String]))] = Array((6,(None,Some(10K))), (3,(Some(Scala),Some(20K))), (4,(Some(Java),Some(18K))), (1,(Some(Spark),None)), (5,(None,Some(25K))), (2,(Some(Hadoop),None)))七、Action操作
### --- Action操作
collectAsMap / countByKey / lookup(key)### --- 源码提取说明
countByKey源码:~~~ # 源码提取说明:PairRDDFunctions.scala
~~~ # 361行
/**
* Count the number of elements for each key, collecting the results to a local Map.
*
* @note This method should only be used if the resulting map is expected to be small, as
* the whole thing is loaded into the driver's memory.
* To handle very large results, consider using rdd.mapValues(_ => 1L).reduceByKey(_ + _), which
* returns an RDD[T, Long] instead of a map.
*/
def countByKey(): Map[K, Long] = self.withScope {
self.mapValues(_ => 1L).reduceByKey(_ + _).collect().toMap
}~~~ # 源码提取说明:PairRDDFunctions.scala
~~~ # 930行
/**
* Return the list of values in the RDD for key `key`. This operation is done efficiently if the
* RDD has a known partitioner by only searching the partition that the key maps to.
*/
def lookup(key: K): Seq[V] = self.withScope {
self.partitioner match {
case Some(p) =>
val index = p.getPartition(key)
val process = (it: Iterator[(K, V)]) => {
val buf = new ArrayBuffer[V]
for (pair <- it if pair._1 == key) {
buf += pair._2
}
buf
} : Seq[V]
val res = self.context.runJob(self, process, Array(index))
res(0)
case None =>
self.filter(_._1 == key).map(_._2).collect()
}
}### --- 实验操作
scala> val rdd1 = sc.makeRDD(Array(("1","Spark"),("2","Hadoop"), ("3","Scala"),("1","Java")))
rdd1: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[239] at makeRDD at <console>:24
scala> val rdd2 = sc.makeRDD(Array(("3","20K"),("4","18K"), ("5","25K"),("6","10K")))
rdd2: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[240] at makeRDD at <console>:24
scala> rdd1.lookup("1")
res114: Seq[String] = WrappedArray(Spark, Java)
scala> rdd2.lookup("3")
res115: Seq[String] = WrappedArray(20K)Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv016-spark.v01



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通