

|NO.Z.00017|——————————|BigDataEnd|——|Hadoop&Spark.V05|——|Spark.v05|sparkcore|RDD编程&Action算子|
一、Action
### --- Action 用来触发RDD的计算,得到相关计算结果;
~~~ Action触发Job。一个Spark程序(Driver程序)包含了多少 Action 算子,那么就有多少Job;
~~~ 典型的Action算子: collect / count
~~~ collect() => sc.runJob() => ... => dagScheduler.runJob() => 触发了Job
~~~ 要求:能快速准确的区分:Transformation、Action### --- 源码提取说明
~~~ # 源码提取说明:RDD.scala
~~~ # 983行
/**
* Return an array that contains all of the elements in this RDD.
*
* @note This method should only be used if the resulting array is expected to be small, as
* all the data is loaded into the driver's memory.
*/
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}~~~ # 源码提取说明:sparkcontext.scala
~~~ # 2047行
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}~~~ # 源码提取说明:RDD.scala
~~~ # 方法说明
collect() / collectAsMap()
stats / count / mean / stdev / max / min
reduce(func) / fold(func) / aggregate(func)
~~~ first(): Return the first element in this RDD
~~~ take(n): Take the first num elements of the RDD
~~~ top(n): 按照默认(降序)或者指定的排序规则,返回前num个元素。
~~~ takeSample(withReplacement, num, [seed]): 返回采样的数据
~~~ foreach(func) / foreachPartition(func): 与map、mapPartitions类似,区别是foreach 是 Action### --- 实验专题:saveAsTextFile(path) / saveAsSequenceFile(path) / saveAsObjectFile(path)
~~~ # 返回统计信息。仅能作用 RDD[Double] 类型上调用
scala> val rdd1 = sc.range(1, 101)
rdd1: org.apache.spark.rdd.RDD[Long] = MapPartitionsRDD[158] at range at <console>:24
scala> rdd1.stats
res69: org.apache.spark.util.StatCounter = (count: 100, mean: 50.500000, stdev: 28.866070, max: 100.000000, min: 1.000000)
scala> val rdd2 = sc.range(1, 101)
rdd2: org.apache.spark.rdd.RDD[Long] = MapPartitionsRDD[162] at range at <console>:24~~~ # 不能调用
scala> rdd1.zip(rdd2).stats
<console>:28: error: value stats is not a member of org.apache.spark.rdd.RDD[(Long, Long)]
rdd1.zip(rdd2).stats
^
~~~ # count在各种类型的RDD上,均能调用
scala> rdd1.zip(rdd2).count
res71: Long = 100### --- 聚合操作
scala> rdd.reduce(_+_)
res72: Int = 55
scala> rdd.fold(0)(_+_)
res73: Int = 55
scala> rdd.fold(1)(_+_)
res74: Int = 58
scala> rdd.fold(1)((x, y) => {
| println(s"x=$x, y=$y")
| x+y
| })
~~~ 输出参数
x=1, y=16
x=17, y=41
res75: Int = 58
scala> rdd.aggregate(0)(_+_, _+_)
res76: Int = 55
scala> rdd.aggregate(1)(_+_, _+_)
res77: Int = 58
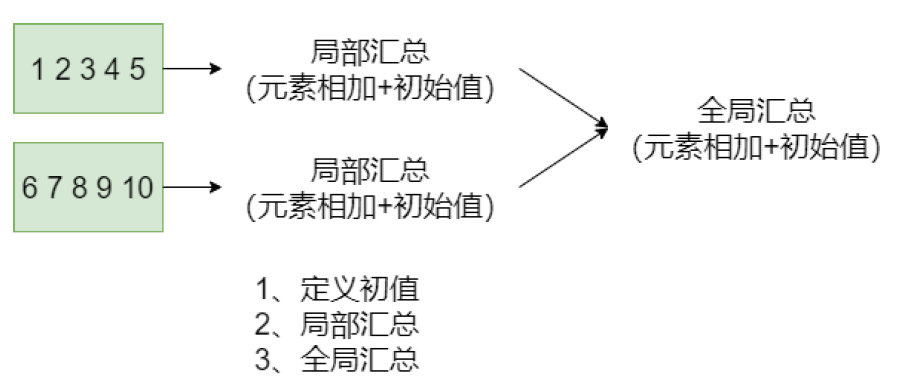
scala> rdd.aggregate(1)(
| (a, b) => {
| println(s"a=$a, b=$b")
| a+b
| },
| (x, y) => {
| println(s"x=$x, y=$y")
| x+y
| })
~~~输出参数
x=1, y=41
x=42, y=16
res78: Int = 58~~~ # first / take(n) / top(n) :获取RDD中的元素。多用于测试
scala> rdd.first
res79: Int = 1
scala> rdd.take(10)
res80: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> rdd.top(10)
res81: Array[Int] = Array(10, 9, 8, 7, 6, 5, 4, 3, 2, 1)~~~ # 采样并返回结果
scala> rdd.takeSample(false, 5)
res82: Array[Int] = Array(3, 6, 9, 10, 8)~~~ # 保存文件到指定路径(rdd有多少分区,就保存为多少文件,保存文件时注意小文件问题)
scala> rdd.saveAsTextFile("data/t1")二、实验结果说明
Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv016-spark.v01



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通