

|NO.Z.00010|——————————|^^ 配置 ^^|——|Hadoop&Spark.V10|——|Spark.v10|sparkcore|集群模式&yarn模式&整合hdfsspark的historyserver服务|
一、集群模式--Yarn模式
### --- 集群模式-Yarn模式
~~~ 参考:http://spark.apache.org/docs/latest/running-on-yarn.html
~~~ 需要启动的服务:hdfs服务、yarn服务
~~~ 需要关闭 Standalone 对应的服务(即集群中的Master、Worker进程),一山不容二虎!### --- 在Yarn模式中,Spark应用程序有两种运行模式:
~~~ yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
~~~ yarn-cluster:Driver程序运行在由RM启动的 AppMaster中,适用于生产环境### --- 二者的主要区别:Driver在哪里
~~~ 关闭 Standalon 模式下对应的服务;开启 hdfs、yarn、historyserver 服务### --- 学习建议
~~~ 在课程学习的过程中,大多数情况使用Standalone模式 或者 local模式
~~~ 建议不使用HA;更多关注的Spark开发二、集群模式:yarn模式集群配置
### --- 修改 yarn-site.xml 配置
~~~ # 在 $HADOOP_HOME/etc/hadoop/yarn-site.xml 中增加,分发到集群,重启 yarn服务
[root@hadoop01 ~]# vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<!-- spark-core集群配置参数 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>~~~ # 备注:
~~~ yarn.nodemanager.pmem-check-enabled。是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true
~~~ yarn.nodemanager.vmem-check-enabled。是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true~~~ # 分发到其它节点
[root@hadoop01 ~]# rsync-script $HADOOP_HOME/etc/hadoop/yarn-site.xml
[root@hadoop01 ~]# start-yarn.sh ### --- 修改spark配置参数,分发到集群
~~~ # spark-env.sh 中这一项必须要有
[root@hadoop02 ~]# vim /opt/yanqi/servers/spark-2.4.5/conf/spark-env.sh
export HADOOP_CONF_DIR=/opt/yanqi/servers/hadoop-2.9.2/etc/hadoop
~~~ # 发送到其它节点
[root@hadoop02 ~]# rsync-script /opt/yanqi/servers/spark-2.4.5/conf/spark-env.sh~~~ # 将 $SPARK_HOME/jars 下的jar包上传到hdfs
[root@hadoop02 ~]# hdfs dfs -mkdir -p /spark-yarn/jars/
[root@hadoop02 ~]# hdfs dfs -put $SPARK_HOME/jars/* /spark-yarn/jars/~~~ # spark-default.conf(以下是优化) 与 hadoop historyserver集成
[root@hadoop02 ~]# vim /opt/yanqi/servers/spark-2.4.5/conf/spark-defaults.conf
spark.yarn.historyServer.address hadoop01:18080 # 添加Hadoop历史服务器地址:与spark的historyserver集成;
spark.yarn.jars hdfs:///spark-yarn/jars/*.jar # 优化:把spark的jar上传到hdfs服务上。可以起到不用启动spark服务,可以直接调用spark服务
~~~ # 发送到其它节点
[root@hadoop02 ~]# rsync-script /opt/yanqi/servers/spark-2.4.5/conf/spark-defaults.conf ### --- 启动hdfs和yarn服务
[root@hadoop01 ~]# start-dfs.sh
[root@hadoop01 ~]# start-yarn.sh 三、yarn模式集群验证测试
### --- spark测试client模式
~~~ # client
[root@hadoop02 ~]# spark-submit --master yarn \
--deploy-mode client \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 2000
~~~ 输出参数
Pi is roughly 3.1416825357084126 [root@hadoop02 ~]# jps
ExecutorLauncher # 先拉起服务
[root@hadoop00 ~]# jps
hadoop01 CoarseGrainedExecutorBackend # sprksubmit:是我们的driver
hadoop02 SparkSubmit
hadoop03 CoarseGrainedExecutorBackend~~~ 在提取App节点上可以看见:SparkSubmit、CoarseGrainedExecutorBackend
~~~ 在集群的其他节点上可以看见:CoarseGrainedExecutorBackend
~~~ 在提取App节点上可以看见:程序计算的结果(即可以看见计算返回的结果)### --- spark测试cluster模式
~~~ # cluster
[root@hadoop02 ~]# spark-submit --master yarn \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 2000[root@hadoop00 ~]# jps
hadoop01 ApplicationMaster CoarseGrainedExecutorBackend //sprksubmit:是我们的driver
hadoop02 SparkSubmit
hadoop03 CoarseGrainedExecutorBackend~~~ 在提取App节点上可以看见:SparkSubmit
~~~ 在集群的其他节点上可以看见:CoarseGrainedExecutorBackend、ApplicationMaster(Driver运行在此)
~~~ 在提取App节点上看不见最终的结果四、整合HistoryServer服务
### --- 整合Hadoop和spark的historyserver
~~~ 前提:Hadoop的 HDFS、Yarn、HistoryServer 正常;Spark historyserver服务正常;
~~~ Hadoop:JobHistoryServer
~~~ Spark:HistoryServer### --- 修改 spark-defaults.conf,并分发到集群
~~~ # 修改 spark-defaults.conf
[root@hadoop02 ~]# vim $SPARK_HOME/conf/spark-defaults.conf
Example:
spark.master spark://hadoop02:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:9000/spark-eventlog
spark.eventLog.compress true
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m
spark.yarn.historyServer.address hadoop01:18080 # --添加下面2行参数,默认端口号是18080,是jobhistoryserver所在主机地址hadoop01
spark.history.ui.port 18080
spark.yarn.jars hdfs:///spark-yarn/jars/*.jar # --此行是优化
~~~ # 发送到其它节点
[root@hadoop02 ~]# rsync-script $SPARK_HOME/conf/spark-defaults.conf### --- 重启/启动Hadoop和spark 历史服务
~~~ # 启动Hadoop历史服务器
[root@hadoop01 ~]# /opt/yanqi/servers/hadoop-2.9.2/sbin/mr-jobhistory-daemon.sh start historyserver
[root@hadoop01 ~]# jps
JobHistoryServer~~~ # 启动spark-history-server服务
[root@hadoop01 ~]# stop-history-server.sh
[root@hadoop01 ~]# start-history-server.sh
[root@hadoop01 ~]# jps
HistoryServer### --- 提交任务
~~~ # 计算圆周率
[root@hadoop02 ~]# spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
$SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 100
~~~输出参数:日志地址
tracking URL:http://hadoop01:8088/proxy/application_1634468914391_0005/### --- 通过Chrome访问jobhistoryserver:http://hadoop01:8088/cluster
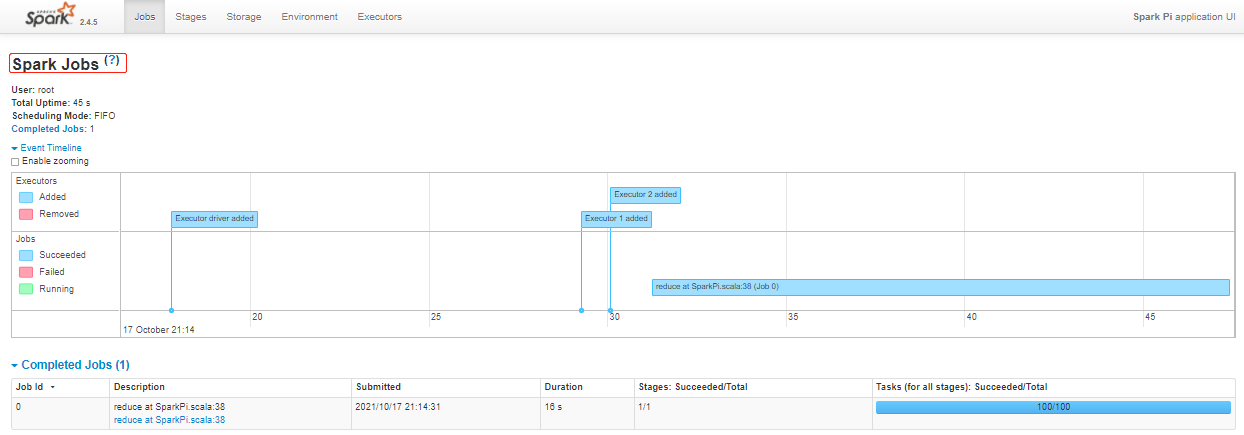
~~~ http://hadoop01:18080/history/application_1634475012831_0005/jobs/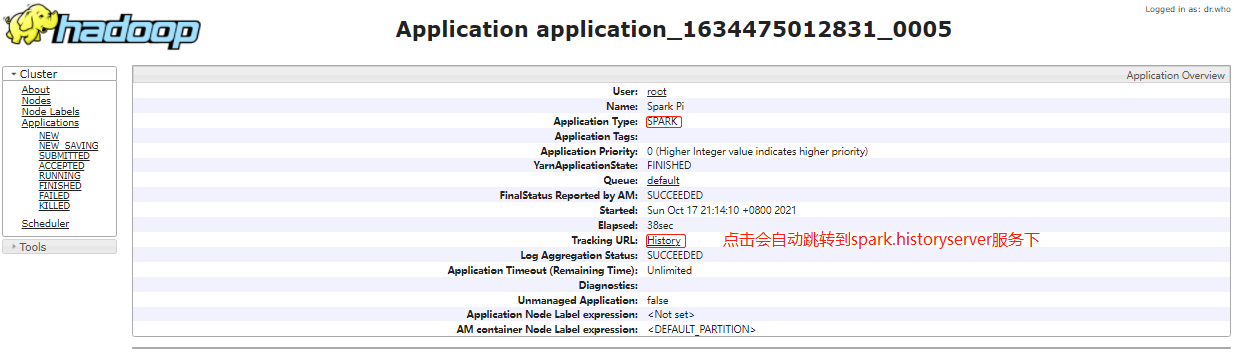
附录一:定版配置文件
### --- $HADOOP_HOME/etc/hadoop/yarn-site.xml
[root@hadoop02 ~]# vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<!-- spark-core集群配置参数 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>### --- /opt/yanqi/servers/spark-2.4.5/conf/spark-env.sh
[root@hadoop02 ~]# vim /opt/yanqi/servers/spark-2.4.5/conf/spark-env.sh
export JAVA_HOME=/opt/yanqi/servers/jdk1.8.0_231
export HADOOP_HOME=/opt/yanqi/servers/hadoop-2.9.2
export HADOOP_CONF_DIR=/opt/yanqi/servers/hadoop-2.9.2/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/yanqi/servers/hadoop-2.9.2/bin/hadoop classpath)
#export SPARK_MASTER_HOST=hadoop02
#export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1g
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=50 -Dspark.history.fs.logDirectory=hdfs://Hadoop01:9000/spark-eventlog"
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01,hadoop02,hadoop03 -Dspark.deploy.zookeeper.dir=/spark"### --- /opt/yanqi/servers/spark-2.4.5/conf/spark-defaults.conf
[root@hadoop02 ~]# vim /opt/yanqi/servers/spark-2.4.5/conf/spark-defaults.conf
Example:
spark.master spark://hadoop02:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:9000/spark-eventlog
spark.eventLog.compress true
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m
spark.yarn.historyServer.address hadoop01:18080
spark.history.ui.port 18080
spark.yarn.jars hdfs:///spark-yarn/jars/*.jar Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv016-spark.v01



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通