

|NO.Z.00009|——————————|^^ 配置 ^^|——|Hadoop&Spark.V09|——|Spark.v09|sparkcore|Spark-Standalone集群模式&高可用配置&zookeeper|
一、高可用配置
### --- spark standalone集群配置说明
~~~ Spark Standalone集群是 Master-Slaves架构的集群模式,
~~~ 和大部分的Master-Slaves结构集群一样,存着Master单点故障的问题。### --- 如何解决这个问题,Spark提供了两种方案:
~~~ # 基于zookeeper的standby master:
~~~ 基于zookeeper的Standby Master,适用于生产模式。
~~~ 将 Spark 集群连接到Zookeeper,利用 Zookeeper 提供的选举和状态保存的功能,
~~~ 一个 Master 处于Active 状态,其他 Master 处于Standby状态;
~~~ 保证在ZK中的元数据主要是集群的信息,
~~~ 包括:Worker,Driver和Application以及Executors的信息;
~~~ 如果Active的Master挂掉了,
~~~ 通过选举产生新的 Active 的 Master,然后执行状态恢复,整个恢复过程可能需要1~2分钟;~~~ # 基于文件系统的单点故障
~~~ 基于文件系统的单点恢复(Single-Node Rcovery with Local File System),
~~~ 主要用于开发或者测试环境。
~~~ 将 Spark Application 和 Worker 的注册信息保存在文件中,
~~~ 一旦Master发生故障,就可以重新启动Master进程,将系统恢复到之前的状态二、准备环境:zookeeper集群
### --- Zookeeper环境搭建:下载并解版本包:修改配置文件
[root@hadoop02 ~]# ls /opt/yanqi/software/zookeeper-3.4.14.tar.gz
/opt/yanqi/software/zookeeper-3.4.14.tar.gz
[root@hadoop02 ~]# cd /opt/yanqi/software/
[root@hadoop02 software]# tar -zxvf zookeeper-3.4.14.tar.gz -C ../servers/~~~ # 配置zk环境变量
[root@hadoop02 ~]# vim /etc/profile
##ZK_HOME
export ZK_HOME=/opt/yanqi/servers/zookeeper-3.4.14
export PATH=$PATH:$ZK_HOME/bin:$ZK_HOME/sbin
[root@hadoop02 ~]# source /etc/profile~~~ # 准备data与log目录
~~~ # 创建zk存储数据目录
[root@hadoop02 ~]# mkdir -p /opt/yanqi/servers/zookeeper-3.4.14/data
~~~ # 创建zk日志文件目录
[root@hadoop02 ~]# mkdir -p /opt/yanqi/servers/zookeeper-3.4.14/data/logs~~~ # 修改zookeeper配置文件
~~~ # 修改zk配置文件
[root@hadoop02 ~]# cd /opt/yanqi/servers/zookeeper-3.4.14/conf
~~~ # 修改文件名称
[root@hadoop02 conf]# mv zoo_sample.cfg zoo.cfg ~~~ # 修改配置文件参数
[root@hadoop02 ~]# vim /opt/yanqi/servers/zookeeper-3.4.14/conf/zoo.cfg
dataDir=/opt/yanqi/servers/zookeeper-3.4.14/data # 第12行,更新datadir
dataLogDir=/opt/yanqi/servers/zookeeper-3.4.14/data/logs # 第13行,添加logdir
autopurge.purgeInterval=1 # 打开注释:ZK提供了自动清理事务日志和快照文件的功能,这个参数指定了清理频率,单位是小时
server.1=hadoop01:2888:3888 # 增加集群配置:server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888### --- 添加myid配置并分发到其它节点
~~~ # 在zookeeper的 data 目录下创建一个 myid 文件,内容为1,这个文件就是记录每个服务器的ID
[root@hadoop02 ~]# echo 2 >/opt/yanqi/servers/zookeeper-3.4.14/data/myid~~~ # 安装包分发并修改myid的值
~~~ # 发送到其它主机上
[root@hadoop02 ~]# rsync-script /opt/yanqi/servers/zookeeper-3.4.14
~~~ # 修改对应主机的myid
[root@hadoop01 ~]# echo 1 >/opt/yanqi/servers/zookeeper-3.4.14/data/myid
[root@hadoop03 ~]# echo 3 >/opt/yanqi/servers/zookeeper-3.4.14/data/myid### --- 依次启动三个zk实例启动命令(三个节点都要执行)
[root@hadoop01 ~]# /opt/yanqi/servers/zookeeper-3.4.14/bin/zkServer.sh start
[root@hadoop02 ~]# /opt/yanqi/servers/zookeeper-3.4.14/bin/zkServer.sh start
[root@hadoop03 ~]# /opt/yanqi/servers/zookeeper-3.4.14/bin/zkServer.sh start~~~ # 查看zookeeper的启动状态
[root@hadoop01 ~]# /opt/yanqi/servers/zookeeper-3.4.14/bin/zkServer.sh status
Mode: follower
[root@hadoop02 ~]# /opt/yanqi/servers/zookeeper-3.4.14/bin/zkServer.sh status
Mode: follower
[root@hadoop03 ~]# /opt/yanqi/servers/zookeeper-3.4.14/bin/zkServer.sh status
Mode: leader### --- 创建zookeeper的启动脚本:
~~~ # 创建zookeeper集群启动脚本
[root@hadoop02 ~]# vim /opt/yanqi/servers/zookeeper-3.4.14/bin/zk-all.sh
#!/bin/sh
echo "start zookeeper server..."
if(($#==0));then
echo "no params";
exit;
fi
hosts="hadoop01 hadoop02 hadoop03"
for host in $hosts
do
ssh $host "source /etc/profile; /opt/yanqi/servers/zookeeper-3.4.14/bin/zkServer.sh $1"
done~~~ # 使用脚本启动停止脚本zookeeper集群
[root@hadoop02 ~]# chmod +x /opt/yanqi/servers/zookeeper-3.4.14/bin/zk-all.sh
[root@hadoop02 ~]# ./zk-all.sh stop
[root@hadoop02 ~]# ./zk-all.sh start
[root@hadoop02 ~]# ./zk-all.sh status
Using config: /opt/yanqi/servers/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
Using config: /opt/yanqi/servers/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: leader
Using config: /opt/yanqi/servers/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower三、spark standalone集群配置
### --- 修改 spark-env.sh 文件,并分发到集群中
[root@hadoop02 ~]# vim $SPARK_HOME/conf/spark-env.sh
# export SPARK_MASTER_HOST=hadoop02 # 注释掉这2行内容
# export SPARK_MASTER_PORT=7077 # 注释掉这2行内容
~~~ # 最后一行添加如下内容
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01,hadoop02,hadoop03 -Dspark.deploy.zookeeper.dir=/spark"~~~ # 发送到其它节点
~~~ spark.deploy.recoveryMode:可选值 Zookeeper、FileSystem、None
~~~ deploy.zookeeper.url:Zookeeper的URL,主机名:端口号(缺省2181)
~~~ deploy.zookeeper.dir:保存集群元数据信息的地址,在ZooKeeper中保存该信息
[root@hadoop02 ~]# rsync-script $SPARK_HOME/conf/spark-env.sh ### --- 启动 Spark 集群hadoop02
[root@hadoop02 ~]# stop-all-spark.sh
[root@hadoop02 ~]# start-all-spark.sh~~~ # 查看服务进程
[root@hadoop00 ~]# jps
Hadoop01 Worker
Hadoop02 Master Worker # 此时master节点在Hadoop02上
Hadoop03 Worker### --- 浏览器输入:http://hadoop02:8080/
~~~ 刚开始 Master 的状态是STANDBY,稍等一会变为:RECOVERING,最终是:ALIVE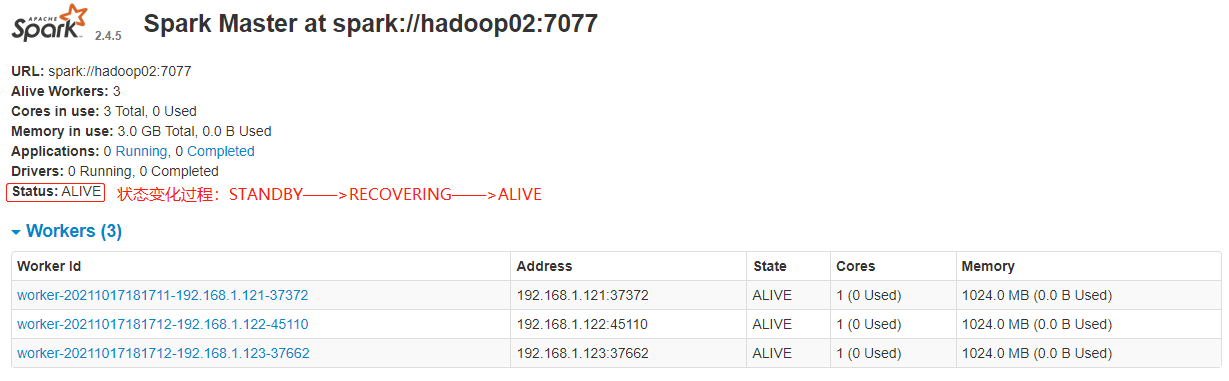
### --- 在Hadoop01上启动master服务
~~~ 进入浏览器输入:http://hadoop01:8080/,此时 Master 的状态为:STANDBY
[root@hadoop01 ~]# start-master.sh~~~ # 查看服务进程
[root@hadoop00 ~]# jps
Hadoop01 Master Worker # 备用master节点在Hadoop01上
Hadoop02 Master Worker # 此时master节点在Hadoop02上
Hadoop03 Worker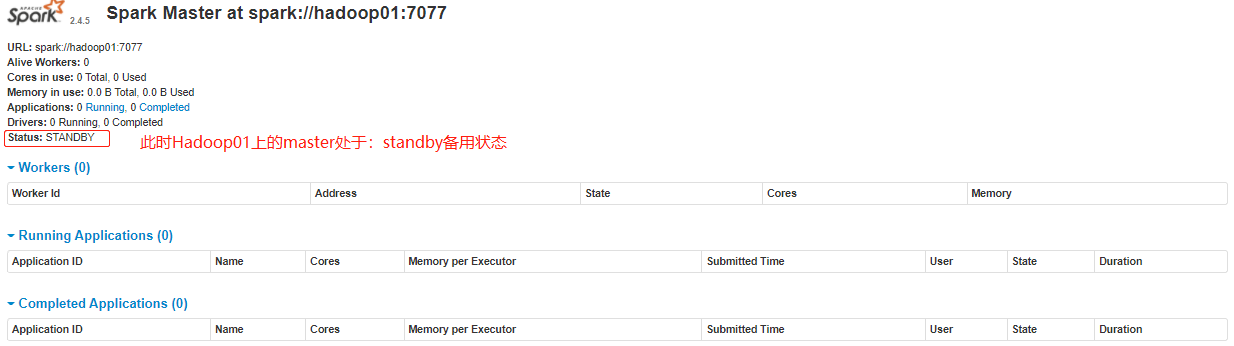
~~~ # 杀到Hadoop02上 Master 进程,再观察Hadoop01上 Master 状态,
~~~ 由 STANDBY=> RECOVERING => ALIVE
~~~ 进入浏览器输入:http://hadoop01:8080/,此时 Master 的状态为:STANDBY
[root@hadoop02 ~]# jps
15622 Master
15726 Worker
[root@hadoop02 ~]# kill -9 15622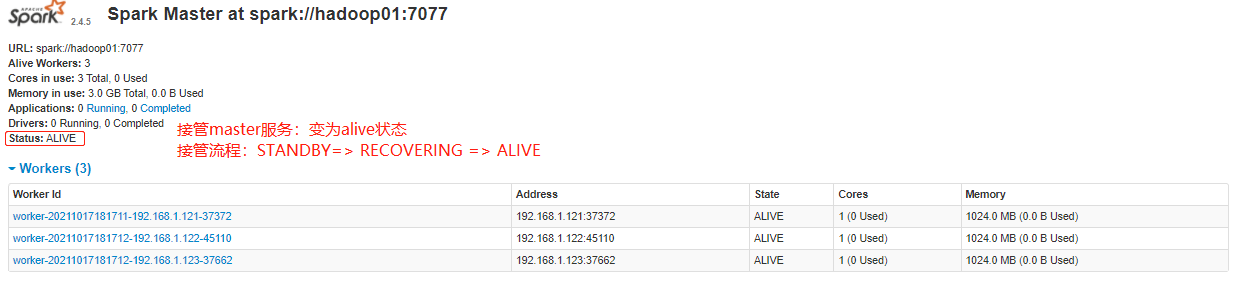
### --- 停止集群状态
~~~ # 停止spark集群
[root@hadoop02 ~]# stop-all-spark.sh
~~~ # 停止zk服务
[root@hadoop02 ~]# ./zk-all.sh stop四、小结:
### --- 小结:
~~~ 配置每个worker的core、memory
~~~ 运行模式:cluster、client;client缺省模式,有返回结果,适合调试;cluster与此相反
~~~ History server
~~~ 高可用(ZK、Local Flile;在ZK中记录集群的状态)[root@hadoop02 ~]# zkCli.sh
[zk: localhost:2181(CONNECTED) 1] ls / # 记录的位置
[zookeeper, spark]
[zk: localhost:2181(CONNECTED) 2] ls /spark # 选举的信息
[leader_election, master_status]附录一:定版配置文件
### --- $HADOOP_HOME/etc/hadoop/yarn-site.xml
[root@hadoop02 ~]# vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<!-- spark-core集群配置参数
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
-->### --- /opt/yanqi/servers/spark-2.4.5/conf/spark-env.sh
[root@hadoop02 ~]# vim /opt/yanqi/servers/spark-2.4.5/conf/spark-env.sh
export JAVA_HOME=/opt/yanqi/servers/jdk1.8.0_231
export HADOOP_HOME=/opt/yanqi/servers/hadoop-2.9.2
export HADOOP_CONF_DIR=/opt/yanqi/servers/hadoop-2.9.2/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/yanqi/servers/hadoop-2.9.2/bin/hadoop classpath)
#export SPARK_MASTER_HOST=hadoop02
#export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1g
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=50 -Dspark.history.fs.logDirectory=hdfs://Hadoop01:9000/spark-eventlog"
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01,hadoop02,hadoop03 -Dspark.deploy.zookeeper.dir=/spark"### --- /opt/yanqi/servers/spark-2.4.5/conf/spark-defaults.conf
[root@hadoop02 ~]# vim /opt/yanqi/servers/spark-2.4.5/conf/spark-defaults.conf
Example:
spark.master spark://hadoop02:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:9000/spark-eventlog
spark.eventLog.compress true
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512mWalter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv016-spark.v01



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通