|NO.Z.00007|——————————|^^ 配置 ^^|——|Hadoop&Spark.V07|——|Spark.v07|sparkcore|Spark-Standalone集群模式&运行模式cluster&client|
一、运行模式(cluster / client)
### --- 运行模式(cluster / client)
~~~ 最大的区别:Driver运行在哪里;client是缺省的模式,能看见返回结果,适合调试;cluster与此相反;
~~~ Client模式:(缺省)Driver运行在提交任务的Client此时在Client模式下看见应用的返回结果适合交互调试
~~~ Cluster模式:Driver运行在Spark集群中,看不见程序的返回结果,合适生产环境[root@hadoop02 ~]# spark-submit
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local[*]).
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).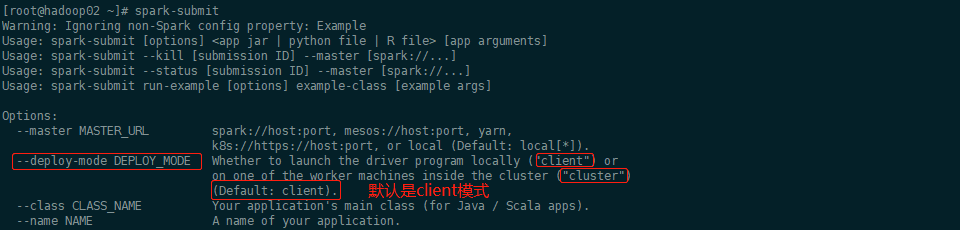
二、实验验证一:(Client 模式):
### --- 模式是client模式,不用添加参数
[root@hadoop02 ~]# spark-submit --class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 1000
~~~ 输出参数
Pi is roughly 3.141553231415532[root@hadoop02 ~]# jps
SparkSubmit
Master
Worker
CoarseGrainedExecutorBackend
[root@hadoop03 servers]# jps
CoarseGrainedExecutorBackend
Worker
[root@hadoop01 ~]# jps
CoarseGrainedExecutorBackend
Worker~~~ # 再次使用 jps 检查集群中的进程:
~~~ Master进程做为cluster manager,管理集群资源
~~~ Worker 管理节点资源
~~~ SparkSubmit 做为Client端,运行 Driver 程序。Spark Application执行完成,进程终止
~~~ CoarseGrainedExecutorBackend,运行在Worker上,用来并发执行应用程序三、实验验证二:(Cluster 模式):
### --- 它只会把任务提交,不会输出参数
[root@hadoop02 ~]# spark-submit --class org.apache.spark.examples.SparkPi \
--deploy-mode cluster \
$SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 1000[root@hadoop02 ~]# jps
Master
CoarseGrainedExecutorBackend
Worker
[root@hadoop01 ~]# jps
DriverWrapper
Worker
[root@hadoop03 ~]# jps
Worker
CoarseGrainedExecutorBackend### --- SparkSubmit 进程会在应用程序提交给集群之后就退出
~~~ Master会在集群中选择一个 Worker 进程生成一个子进程 DriverWrapper 来启动 Driver 程序
~~~ Worker节点上会启动 CoarseGrainedExecutorBackend
~~~ DriverWrapper 进程会占用 Worker 进程的一个core(缺省分配1个core,1G内存)
~~~ 应用程序的结果,会在执行 Driver 程序的节点的 stdout 中输出,而不是打印在屏幕上### --- 查看输出结果
~~~ 在启动 DriverWrapper 的节点上,进入 $SPARK_HOME/work/,
~~~ 可以看见类似driver-20200810233021-0000 的目录,
~~~ 这个就是 driver 运行时的日志文件,进入该目录,会发现:
~~~ jar 文件,这就是移动的计算
~~~ stderr 运行日志
~~~ stdout 输出结果### --- 查看输出结果
[root@hadoop01 ~]# ll $SPARK_HOME/work/driver-20211017165146-0000
spark-examples_2.12-2.4.5.jar
stderr
stdout
[root@hadoop01 ~]# cat $SPARK_HOME/work/driver-20211017165146-0000/stdout
Pi is roughly 3.1416253178540634 Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor

 浙公网安备 33010602011771号
浙公网安备 33010602011771号