

|NO.Z.00003|——————————|^^ 部署 ^^|——|Hadoop&Spark.V03|——|Spark.v03|sparkcore|Spark集群部署|
一、Spark官方地址
### --- Spark安装
~~~ 官网地址:http://spark.apache.org/
~~~ 文档地址:http://spark.apache.org/docs/latest/
~~~ 下载地址:http://spark.apache.org/downloads.html
~~~ 下载Spark安装包
~~~ 下载地址:https://archive.apache.org/dist/spark/
~~~ 备注:不用安装scala二、spark安装
### --- 下载软件解压缩,移动到指定位置
[root@hadoop02 ~]# ls /opt/yanqi/software/spark-2.4.5-bin-without-hadoop-scala-2.12.tgz
/opt/yanqi/software/spark-2.4.5-bin-without-hadoop-scala-2.12.tgz
[root@hadoop02 ~]# cd /opt/yanqi/software/
[root@hadoop02 software]# tar -zxvf spark-2.4.5-bin-without-hadoop-scala-2.12.tgz -C ../servers/
[root@hadoop02 software]# cd ../servers/
[root@hadoop02 servers]# mv spark-2.4.5-bin-without-hadoop-scala-2.12/ spark-2.4.5### --- 设置环境变量,并使之生效
[root@hadoop02 ~]# vim /etc/profile
##SPARK_HOME
export SPARK_HOME=/opt/yanqi/servers/spark-2.4.5
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@hadoop02 ~]# source /etc/profile三、spark配置文件修改
### --- 修改配置:准备配置文件
~~~ 文件位置:$SPARK_HOME/conf
~~~ 修改文件:slaves、spark-defaults.conf、spark-env.sh、log4j.properties more slaves~~~ # 准备配置文件
[root@hadoop02 ~]# cd $SPARK_HOME/conf
[root@hadoop02 conf]# cp slaves.template slaves
[root@hadoop02 conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@hadoop02 conf]# cp spark-env.sh.template spark-env.sh
[root@hadoop02 conf]# cp log4j.properties.template log4j.properties### --- 修改slaves配置文件
~~~ 放置所有从节点的主机地址
~~~ hadoop02作为主节点,可以不写入到里面
[root@hadoop02 ~]# vim $SPARK_HOME/conf/slaves
hadoop01
hadoop02
hadoop03### --- 修改spark-defaults.conf配置文件
[root@hadoop02 ~]# vim $SPARK_HOME/conf/spark-defaults.conf
Example:
spark.master spark://hadoop02:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:9000/spark-eventlog
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m~~~ # 创建 HDFS 目录:hdfs dfs -mkdir /spark-eventlog
[root@hadoop02 ~]# hdfs dfs -mkdir /spark-eventlog
~~~ # 备注:
spark.master # 定义master节点,缺省端口号 7077
spark.eventLog.enabled # 开启eventLog
spark.eventLog.dir # eventLog的存放位置
spark.serializer # 一个高效的序列化器
spark.driver.memory # 定义driver内存的大小(缺省1G)### --- 修改spark-eventlog配置文集spark-env.sh
~~~ 这里使用的是 spark-2.4.5-bin-without-hadoop,所以要将 Hadoop 相关jars 的位置告诉Spark
[root@hadoop02 ~]# vim $SPARK_HOME/conf/spark-env.sh
export JAVA_HOME=/opt/yanqi/servers/jdk1.8.0_231
export HADOOP_HOME=/opt/yanqi/servers/hadoop-2.9.2
export HADOOP_CONF_DIR=/opt/yanqi/servers/hadoop-2.9.2/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/yanqi/servers/hadoop-2.9.2/bin/hadoop classpath)
export SPARK_MASTER_HOST=hadoop02
export SPARK_MASTER_PORT=7077### --- 修改worker节点内存大小
~~~ 每个节点只剩下500MB内存了,由于我没有配置SPARK_EXECUTOR_MEMORY参数,
~~~ 默认会使用1G内存,所以会出现内存不足,
export SPARK_EXECUTOR_MEMORY=512m四、启动集群
### --- 将Spark软件分发到集群;修改其他节点上的环境变量
[root@hadoop02 ~]# rsync-script /opt/yanqi/servers/spark-2.4.5/### --- 启动集群
~~~ # 在主节点上启动spark服务
[root@hadoop02 ~]# cd $SPARK_HOME/sbin
[root@hadoop02 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/yanqi/servers/spark-2.4.5/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop02.out
hadoop03: starting org.apache.spark.deploy.worker.Worker, logging to /opt/yanqi/servers/spark-2.4.5/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop03.out
hadoop01: starting org.apache.spark.deploy.worker.Worker, logging to /opt/yanqi/servers/spark-2.4.5/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop01.out
hadoop02: starting org.apache.spark.deploy.worker.Worker, logging to /opt/yanqi/servers/spark-2.4.5/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop02.out### --- 验证spark集群是否启动
~~~ 此时 Spark 运行在 Standalone 模式下。
~~~ 分别在hadoop01、hadoop02、hadoop03上执行 jps,可以发现:
### --- 通过Chrome访问spark.ui地址:http://hadoop02:8080/:Spark 的 Web 界面:
[root@hadoop ~]# jps
~~~ 输出的进程
hadoop01 Worker
hadoop02 Master Worker
hadoop03 Worker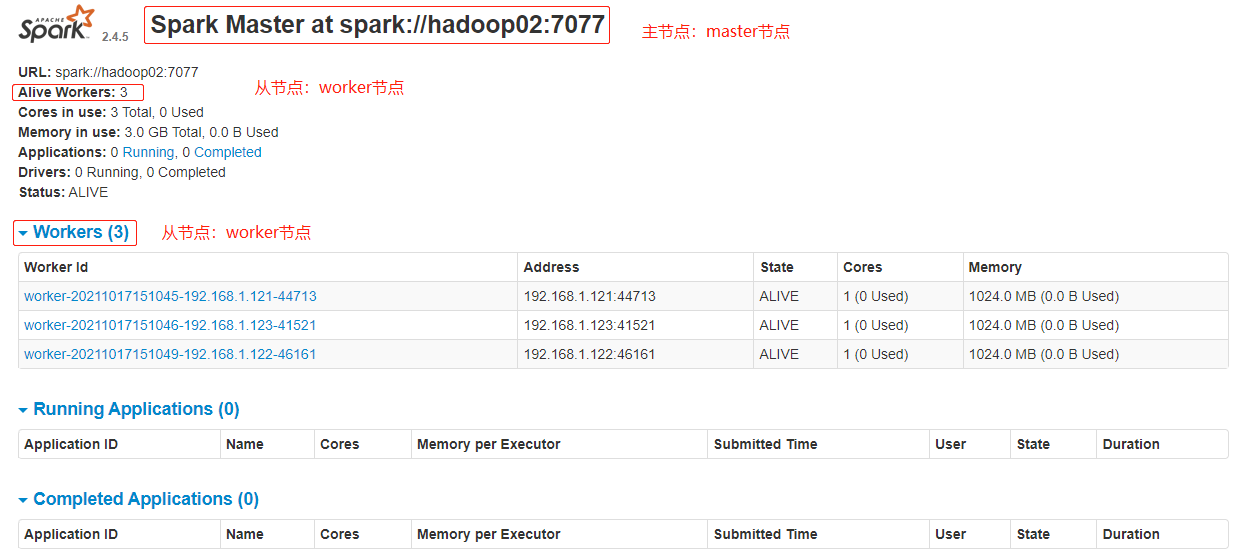
五、start-all.sh和stop-all.sh文件冲突解决方案
### --- 通过whereis搜索可以看到hadoop和spark下都有start-all.sh和stop-all.sh
~~~ 在$HADOOP_HOME/sbin 及 $SPARK_HOME/sbin 下都有 start-all.sh 和stop-all.sh 文件
~~~ 在输入 start-all.sh / stop-all.sh 命令时,谁的搜索路径在前面就先执行谁,此时会产生冲突。
[root@hadoop02 ~]# whereis start-all.sh
start-all:
/opt/yanqi/servers/hadoop-2.9.2/sbin/start-all.cmd
/opt/yanqi/servers/hadoop-2.9.2/sbin/start-all.sh
/opt/yanqi/servers/spark-2.4.5/sbin/start-all.sh
[root@hadoop02 ~]# whereis stop-all.sh
stop-all:
/opt/yanqi/servers/hadoop-2.9.2/sbin/stop-all.cmd
/opt/yanqi/servers/hadoop-2.9.2/sbin/stop-all.sh
/opt/yanqi/servers/spark-2.4.5/sbin/stop-all.sh### --- 解决方案:
~~~ 删除一组 start-all.sh / stop-all.sh 命令,让另外一组命令生效
~~~ 将其中一组命令重命名。如:将 $SPARK_HOME/sbin
~~~ 路径下的命令重命名为:start-all-spark.sh / stop-all-spark.sh
~~~ 将其中一个框架的 sbin 路径不放在 PATH 中~~~ # 修改文件名称
[root@hadoop02 sbin]# cd $SPARK_HOME/sbin
[root@hadoop02 sbin]# mv start-all.sh start-all-spark.sh
[root@hadoop02 sbin]# mv stop-all.sh stop-all-spark.sh
~~~ # 发送到其它节点
[root@hadoop02 ~]# rsync-script /opt/yanqi/servers/spark-2.4.5/
~~~ # 启动服务
[root@hadoop02 ~]# start-all-spark.sh六、集群测试
### --- 通过spark计算:run-example SparkPi 10
[root@hadoop02 ~]# run-example SparkPi 10
~~~ 输出参数
Pi is roughly 3.142947142947143[root@hadoop02 ~]# spark-shell
scala> val lines = sc.textFile("/wcinput/wc.txt")
scala> lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
~~~ 输出参数
(#在文件中输入如下内容,1)
(yanqi,3)
(mapreduce,3)
(yarn,2)
(hadoop,2)
(hdfs,1)七、spark集群说明
### --- Spark集群是否一定依赖hdfs?不是的,除非用到了hdfs。
~~~ Apache Spark支持多种部署模式。
~~~ 最简单的就是单机本地模式(Spark所有进程都运行在一台机器的JVM中)、
~~~ 伪分布式模式(在一台机器中模拟集群运行,相关的进程在同一台机器上)。
~~~ 分布式模式包括:Standalone、Yarn、Mesos。### --- Apache Spark支持多种部署模式:
~~~ # 本地模式:
~~~ 最简单的运行模式,Spark所有进程都运行在一台机器的 JVM 中~~~ # 伪分布式模式:
~~~ 在一台机器中模拟集群运行,相关的进程在同一台机器上(用的非常少)
~~~ # 分布式模式:
~~~ 包括:Standalone、Yarn、MesosStandalone。
~~~ 使用Spark自带的资源调度框架Yarn。
~~~ 使用 Yarn 资源调度框架Mesos。
~~~ 使用 Mesos 资源调度框架Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv016-spark.v01



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix