

|NO.Z.00007|——————————|BigDataEnd|——|Hadoop&PB级数仓.V07|——|PB数仓.v07|数仓设计|技术|逻辑|开发|数仓命名规范|
一、总体架构设计:技术方案选型
### --- 技术方案选型
~~~ 框架选型
~~~ 软件选型
~~~ 服务器选型
~~~ 集群规模的估算### --- 框架选型
~~~ Apache / 第三方发行版(CDH / HDP / Fusion Insight)
~~~ # Apache社区版本优点:
~~~ 完全开源免费
~~~ 社区活跃
~~~ 文档、资料详实~~~ # 缺点:
~~~ 复杂的版本管理
~~~ 复杂的集群安装
~~~ 复杂的集群运维
~~~ 复杂的生态环境~~~ # 第三方发行版本(CDH / HDP / Fusion Insight)
~~~ Hadoop遵从Apache开源协议,用户可以免费地任意使用和修改Hadoop。
~~~ 正因如此,市面上有很多厂家在Apache Hadoop的基础上开发自己的产品。
~~~ 如Cloudera的CDH,Hortonworks的HDP,华为的Fusion Insight等。~~~ # 这些产品的优点是:
~~~ 主要功能与社区版一致
~~~ 版本管理清晰。比如Cloudera,CDH1,CDH2,CDH3,CDH4等,后面加上补丁版本,
~~~ 如CDH4.1.0 patch level 923.142
~~~ 比 Apache Hadoop 在兼容性、安全性、稳定性上有增强。
~~~ 第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运用到各种生产环境
~~~ 版本更新快。如CDH每个季度会有一个update,每一年会有一个release
~~~ 基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch
~~~ 提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在几个小时内部署好集群
~~~ 运维简单。提供了管理、监控、诊断、配置修改的工具,
~~~ 管理配置方便,定位问题快速、准确,使运维工作简单,有效~~~ # CDH:
~~~ 最成型的发行版本,拥有最多的部署案例。提供强大的部署、管理和监控工具。
~~~ 国内使用最多的版本;拥有强大的社区支持,当遇到问题时,能够通过社区、
~~~ 论坛等网络资源快速获取解决方法;
~~~ # HDP:
~~~ 100%开源,可以进行二次开发,但没有CDH稳定。国内使用相对较少;
~~~ Fusion Insight:华为基于hadoop2.7.2版开发的,坚持分层,解耦,开放的原则,得益于高可靠性,
~~~ 在全国各地政府、运营商、金融系统有较多案例。### --- 软件选型
~~~ 数据采集:DataX、Flume、Sqoop、Logstash、Kafka
~~~ 数据存储:HDFS、HBase
~~~ 数据计算:Hive、MapReduce、Tez、Spark、Flink
~~~ 调度系统:Airflow、azkaban、Oozie
~~~ 元数据管理:Atlas
~~~ 数据质量管理:Griffin
~~~ 即席查询:Impala、Kylin、ClickHouse、Presto、Druid
~~~ 其他:MySQL二、框架、软件尽量不要选择最新的版本,选择半年前左右稳定的版本。
| 产品 | 版本 |
| Hadoop | 2.9.2 |
| Hive | 2.3.7 |
| Flume | 1.9 |
| DataX | 3.0 |
| Airflow | 1.2.0 |
| Griffin | 0.4.0 |
| Impala | impala-2.3.0-cdh5.5.0 |
| MySQL | 5.7 |
### --- 服务器选型
~~~ 选择物理机还是云主机
~~~ 机器成本考虑:物理机的价格 > 云主机的价格
~~~ 运维成本考虑:物理机需要有专业的运维人员;云主机的运维工作由供应商完成,运
~~~ 维相对容易,成本相对较低;### --- 集群规模规划
~~~ 如何确认集群规模(假设:每台服务器20T硬盘,128G内存)
~~~ 可以从计算能力(CPU、 内存)、存储量等方面着手考虑集群规模。~~~ # 假设:
~~~ 每天的日活用户500万,平均每人每天有100条日志信息
~~~ 每条日志大小1K左右
~~~ 不考虑历史数据,半年集群不扩容
~~~ 数据3个副本
~~~ 离线数据仓库应用~~~ # 需要多大集群规模?
~~~ 要分析的数据有两部分:日志数据+业务数据
~~~ 每天日志数据量:500W * 100 * 1K / 1024 / 1024 = 500G
~~~ 半年需要的存储量:500G * 3 * 180 / 1024 = 260T
~~~ 通常要给磁盘预留20-30%的空间(这里取25%): 260 * 1.25 = 325T
~~~ 数据仓库应用有1-2倍的数据膨胀(这里取1.5):500T
~~~ 需要大约25个节点~~~ # 其他未考虑因素:数据压缩、业务数据
~~~ 以上估算的生产环境。实际上除了生产环境以外,还需要开发测试环境,这也需要一定数据的机器。三、系统逻辑架构
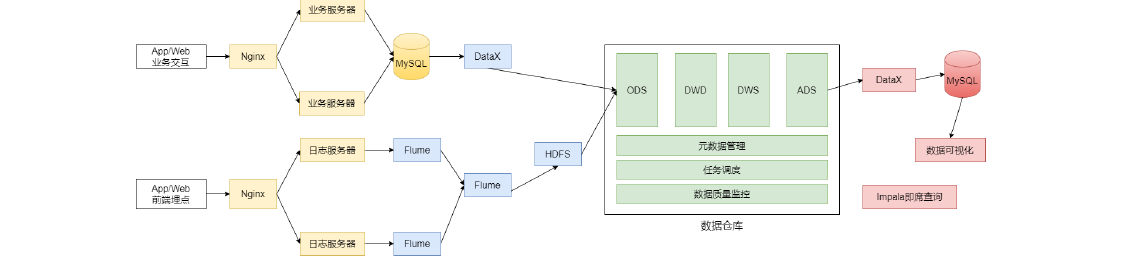
四、开发物理环境
### --- 5台物理机;500G数据盘;32G内存;8个core
[root@hadoop01 ~] df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 20G 14G 6.5G 68% / # 系统盘20G
/dev/vdb 500G 96G 405G 20% /data # 数据盘500G
[root@hadoop01 ~] grep MemTotal /proc/meminfo
MemTotal: 32740424KB # 内存32G[root@hadoop01 ~] lscpu
Architecture: X86_64
CPU op-mode(s): 32-bit,64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(S) list: 0-7
Thread(s) per core: 1
Core(s) per socket: 1 # 1个物理CPU,8个内核
Socket(s): 8
NUMA node(s) 1| hadoop1 | hadoop2 | hadoop3 | hadoop4 | hadoop5 | |
| NameNode | √ | ||||
| SecondaryNameNode | √ | ||||
| DataNode | √ | √ | √ | √ | √ |
| ResourceManager | √ | ||||
| DataManager | √ | √ | √ | √ | √ |
| Hive | √ | √ | √ | ||
| HiveServer2 | √ | ||||
| Flume | √ | ||||
| DataX | √ | ||||
| Airflow | √ | ||||
| Atlas | √ | ||||
| Griffin | √ | ||||
| Impala | √ | √ | √ | √ | √ |
| MySQL | √ |
### --- 关于数据集的说明:
~~~ 在开发过程中使用小规模数据集
~~~ 模块测试使用真实的数据集(数据量大)
~~~ 在做项目期间根据自己实际情况使用不同的数据量(建议使用小规模的数据集)五、数据仓库命名规范
### --- 数据库命名
~~~ 命名规则:数仓对应分层
~~~ 命名示例:ods / dwd / dws/ dim / temp / ads### --- 数仓各层对应数据库
~~~ ods层 -> ods_{业务线|业务项目}
~~~ dw层 -> dwd_{业务线|业务项目} + dws_{业务线|业务项目}
~~~ dim层 -> dim_维表
~~~ ads层 -> ads_{业务线|业务项目} (统计指标等)
~~~ 临时数据 -> temp_{业务线|业务项目}
~~~ 备注:本项目未采用### --- 表命名(数据库表命名规则)
~~~ # * ODS层:
~~~ 命名规则:ods_{业务线|业务项目}_[数据来源类型]_{业务}
~~~ # * DWD层:
~~~ 命名规则:dwd_{业务线|业务项目}_{主题域}_{子业务}
~~~ # * DWS层:
~~~ 命名规则:dws_{业务线|业务项目}_{主题域}_{汇总相关粒度}_{汇总时间周期}
~~~ # * ADS层:
~~~ 命名规则:ads_{业务线|业务项目}_{统计业务}_{报表form|热门排序topN}
~~~ # * DIM层:
~~~ 命名规则:dim_{业务线|业务项目|pub公共}_{维度}六、创建数据库:
### --- 在Hive下创建数据库
[root@hadoop02 ~]# hive
create database if not exists ods;
create database if not exists dwd;
create database if not exists dws;
create database if not exists ads;
create database if not exists dim;
create database if not exists tmp;### --- 查看创建的数据库
hive (default)> show databases;
ads
dim
dwd
dws
ods
tmpWalter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv014-PB离线数仓



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通