

|NO.Z.00078|——————————|BigDataEnd|——|Hadoop&kafka.V63|——|kafka.v63|稳定性|一致性保证.v03|
一、HW和LEO异常案例
### --- HW和LEO异常案例
~~~ Kafka使用HW值来决定副本备份的进度,而HW值的更新通常需要额外一轮FETCH RPC才能完成。
~~~ 但这种设计是有问题的,可能引起的问题包括:
~~~ 备份数据丢失
~~~ 备份数据不一致### --- 数据丢失
~~~ 使用HW值来确定备份进度时其值的更新是在下一轮RPC中完成的。
~~~ 如果Follower副本在标记上方的的第一步与第二步之间发生崩溃,那么就有可能造成数据的丢失。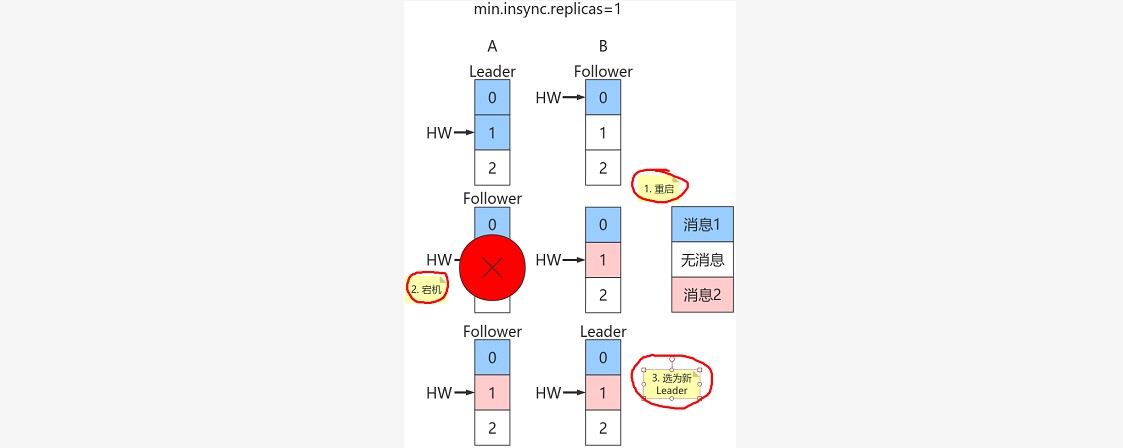
~~~ # 上图中有两个副本:A和B。开始状态是A是Leader。
~~~ 假设生产者min.insync.replicas 为1,那么当生产者发送两条消息给A后,A写入Log,
~~~ 此时Kafka会通知生产者这两条消息写入成功。| 编号 | 属性 | 阶段 | 旧值 | 新值 | 备注 |
| 1 | LeaderLEO | PRODUCE和Follower FETCH 处理完成 | 0 | 1 | 写入了一条数据 |
| 1 | RemoteLEO | PRODUCE和Follower FETCH 处理完成 | 0 | 0 | 第一次fetch中offset为0 |
| 1 | LeaderHW | PRODUCE和Follower FETCH 处理完成 | 0 | 0 | min(LeaderLEO=1,FollowerLEO=0)=0 |
| 1 | FollowerLEO | PRODUCE和Follower FETCH 处理完成 | 0 | 1 | 同步了一条数据 |
| 1 | FollowerHW | PRODUCE和Follower FETCH 处理完成 | 0 | 0 |
min(LeaderHW=0,
FollowerLEO=1)=0 |
| 2 | LeaderLEO | 第二次FollowerFETCH处理完成 | 1 | 2 | 写入了第二条数据 |
| 2 | RemoteLEO | 第二次FollowerFETCH处理完成 | 0 | 1 | 第2次fetch中offset为1 |
| 2 | LeaderHW | 第二次FollowerFETCH处理完成 | 0 | 1 | min(RemoteLEO=1,LeaderLEO=2)=1 |
| 2 | FollowerLEO | 第二次FollowerFETCH处理完成 | 1 | 2 | 写入了第二条数据 |
| 2 | FollowerHW | 第二次FollowerFETCH处理完成 | 0 | 1 | min(LeaderHW=1,FollowerLEO=2)=1 |
| 3 | LeaderLEO | 第三次FollowerFETCH处理完成 | 2 | 2 | 未写入新数据 |
| 3 | RemoteLEO | 第三次FollowerFETCH处理完成 | 1 | 2 | 第3次fetch中offset为2 |
| 3 | LeaderHW | 第三次FollowerFETCH处理完成 | 1 | 2 | min(RemoteLEO=2,LeaderLEO)=2 |
| 3 | FollowerLEO | 第三次FollowerFETCH处理完成 | 2 | 2 | 未写入新数据 |
| 3 | FollowerHW | 第三次FollowerFETCH处理完成 | 1 | 2 |
第3次fetch resp中的LeaderHW和本
地FollowerLEO都是2 |
### --- 但是在broker端,Leader和Follower的Log虽都写入了2条消息且分区HW已经被更新到2,
~~~ 但Follower HW尚未被更新还是1,也就是上面标记的第二步尚未执行,表中最后一条未执行。
~~~ 倘若此时副本B所在的broker宕机,那么重启后B会自动把LEO调整到之前的HW值1,
~~~ 故副本B会做日志截断(log truncation),将offset = 1的那条消息从log中删除,并调整LEO = 1。
~~~ # 此时follower副本底层log中就只有一条消息,即offset = 0的消息!
~~~ B重启之后需要给A发FETCH请求,但若A所在broker机器在此时宕机,
~~~ 那么Kafka会令B成为新的Leader,而当A重启回来后也会执行日志截断,将HW调整回1。~~~ # 这样,offset=1的消息就从两个副本的log中被删除,
~~~ 也就是说这条已经被生产者认为发送成功的数据丢失。
~~~ 丢失数据的前提是min.insync.replicas=1 时,一旦消息被写入Leader端Log即被认为是committed 。
~~~ # 延迟一轮FETCH RPC 更新HW值的设计使follower HW值是异步延迟更新,
~~~ 若在这个过程中Leader发生变更,那么成为新Leader的Follower的HW值就有可能是过期的,
~~~ 导致生产者本是成功提交的消息被删除。### --- Leader和Follower数据离散
~~~ 除了可能造成的数据丢失以外,该设计还会造成Leader的Log和Follower的Log数据不一致。
~~~ 如Leader端记录序列:m1,m2,m3,m4,m5,…;Follower端序列可能是m1,m3,m4,m5,…。
~~~ 看图: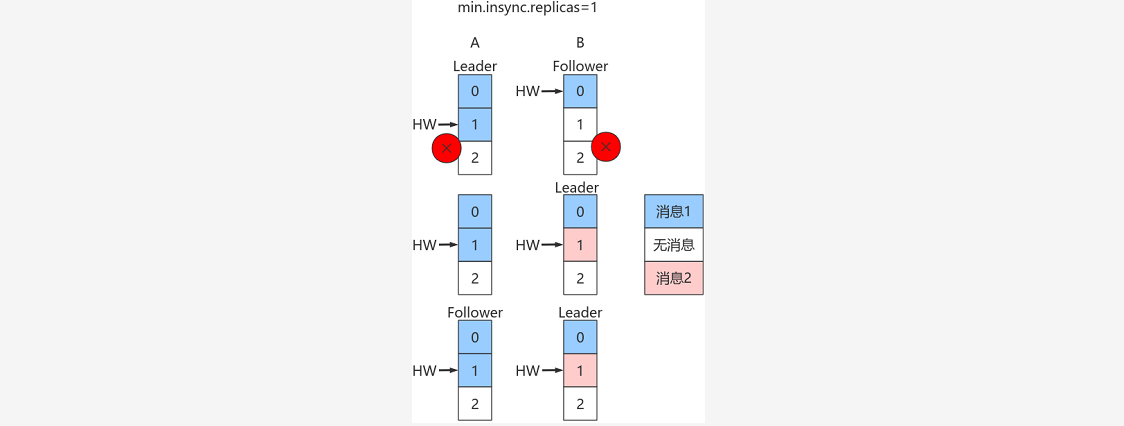
### --- 假设:A是Leader,A的Log写入了2条消息,但B的Log只写了1条消息。
~~~ 分区HW更新到2,但B的HW还是1,同时生产者min.insync.replicas 仍然为1。
~~~ 假设A和B所在Broker同时宕机,B先重启回来,因此B成为Leader,分区HW = 1。
~~~ 假设此时生产者发送了第3条消息(红色表示)给B,于是B的log中offset = 1的消息变成了红框表示的消息,
~~~ 同时分区HW更新到2(A还没有回来,就B一个副本,故可以直接更新HW而不用理会A)
~~~ 之后A重启回来,需要执行日志截断,但发现此时分区HW=2而A之前的HW值也是2,故不做任何调整。
~~~ 此后A和B将以这种状态继续正常工作。
~~~ 显然,这种场景下,A和B的Log中保存在offset = 1的消息是不同的记录,从而引发不一致的情形出现。Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv013-kafka



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通