

|NO.Z.00069|——————————|BigDataEnd|——|Hadoop&kafka.V54|——|kafka.v54|稳定性|事务相关配置.v01|
一、稳定性:事务相关配置
### --- 事务场景
~~~ 如producer发的多条消息组成一个事务这些消息需要对consumer同时可见或者同时不可见。
~~~ producer可能会给多个topic,多个partition发消息,这些消息也需要能放在一个事务里面,
~~~ 这就形成了一个典型的分布式事务。
~~~ kafka的应用场景经常是应用先消费一个topic,然后做处理再发到另一个topic,
~~~ 这个consume-transform-produce过程需要放到一个事务里面,
~~~ 比如在消息处理或者发送的过程中如果失败了,消费偏移量也不能提交。
~~~ producer或者producer所在的应用可能会挂掉,
~~~ 新的producer启动以后需要知道怎么处理之前未完成的事务 。
~~~ 在一个原子操作中,根据包含的操作类型,### --- 可以分为三种情况,前两种情况是事务引入的场景,最后一种没用。
~~~ 只有Producer生产消息;
~~~ 消费消息和生产消息并存,这个是事务场景中最常用的情况,
~~~ 就是我们常说的consume-transform-produce 模式
~~~ 只有consumer消费消息,这种操作其实没有什么意义,跟使用手动提交效果一样,
~~~ 而且也不是事务属性引入的目的,所以一般不会使用这种情况二、几个关键概念和推导
### --- 几个关键概念和推导
~~~ 因为producer发送消息可能是分布式事务,
~~~ 所以引入了常用的2PC,所以有事务协调者(Transaction Coordinator)。
~~~ # Transaction Coordinator和之前为了解决脑裂和惊群问题引入的Group Coordinator在选举上类似。
~~~ 事务管理中事务日志是必不可少的,kafka使用一个内部topic来保存事务日志,
~~~ 这个设计和之前使用内部topic保存偏移量的设计保持一致。~~~ # 事务日志是Transaction Coordinator管理的状态的持久化,因为不需要回溯事务的历史状态,
~~~ 所以事务日志只用保存最近的事务状态。
~~~ # 因为事务存在commit和abort两种操作,
~~~ 而客户端又有read committed和read uncommitted两种隔离级别,
~~~ 所以消息队列必须能标识事务状态,这个被称作Control Message。~~~ # producer挂掉重启或者漂移到其它机器需要能关联的之前的未完成事务
~~~ 所以需要有一个唯一标识符来进行关联,这个就是TransactionalId,一个producer挂了,
~~~ 另一个有相同TransactionalId的producer能够接着处理这个事务未完成的状态。
~~~ # kafka目前没有引入全局序,所以也没有transaction id,这个TransactionalId是用户提前配置的。
~~~ TransactionalId能关联producer,也需要避免两个使用相同TransactionalId的producer同时存在,
~~~ 所以引入了producer epoch来保证对应一个TransactionalId只有一个活跃的producer三、事务语义
### --- 多分区原子写入
~~~ 事务能够保证Kafka topic下每个分区的原子写入。事务中所有的消息都将被成功写入或者丢弃。
~~~ 首先,我们来考虑一下原子读取-处理-写入周期是什么意思。简而言之,
~~~ 这意味着如果某个应用程序在某个topic tp0的偏移量X处读取到了消息A,
~~~ 并且在对消息A进行了一些处理(如B = F(A))之后将消息B写入topic tp1,
~~~ 则只有当消息A和B被认为被成功地消费并一起发布,或者完全不发布时,
~~~ 整个读取过程写入操作是原子的。~~~ # 现在,只有当消息A的偏移量X被标记为已消费,消息A才从topic tp0消费,
~~~ 消费到的数据偏移量(record offset)将被标记为提交偏移量(Committing offset)。
~~~ 在Kafka中,我们通过写入一个名为offsets topic的内部Kafka topic来记录offset commit。
~~~ 消息仅在其offset被提交给offsets topic时才被认为成功消费。
~~~ # 由于offset commit只是对Kafkatopic的另一次写入,
~~~ 并且由于消息仅在提交偏移量时被视为成功消费,
~~~ 所以跨多个主题和分区的原子写入也启用原子读取-处理-写入循环:
~~~ 提交偏移量X到offset topic和消息B到tp1的写入将是单个事务的一部分,所以整个步骤都是原子的。### --- 粉碎“僵尸实例”
~~~ 我们通过为每个事务Producer分配一个称为transactional.id的唯一标识符来解决僵尸实例的问题。
~~~ 在进程重新启动时能够识别相同的Producer实例。
~~~ API要求事务性Producer的第一个操作应该是在Kafka集群中显示注册transactional.id。
~~~ 当注册的时候,Kafka broker用给定的transactional.id检查打开的事务并且完成处理。~~~ # Kafka也增加了一个与transactional.id相关的epoch。Epoch存储每个transactional.id内部元数据。
~~~ 一旦epoch被触发,任何具有相同的transactional.id和旧的epoch的生产者被视为僵尸,
~~~ Kafka拒绝来自这些生产者的后续事务性写入。
~~~ 简而言之:Kafka可以保证Consumer最终只能消费非事务性消息或已提交事务性消息。
~~~ 它将保留来自未完成事务的消息,并过滤掉已中止事务的消息。### --- 事务消息定义
~~~ # 生产者可以显式地发起事务会话,在这些会话中发送(事务)消息,并提交或中止事务。有如下要求:
~~~ 原子性:消费者的应用程序不应暴露于==未提交事务==的消息中。
~~~ 持久性:Broker不能丢失任何已提交的事务。
~~~ 排序:事务消费者应在每个分区中以原始顺序查看事务消息。
~~~ 交织:每个分区都应该能够接收来自事务性生产者和非事务生产者的消息
~~~ 事务中不应有重复的消息。### --- 如果允许事务性和非事务性消息的交织,
~~~ 则非事务性和事务性消息的相对顺序将
~~~ 基于附加(对于非事务性消息)和最终提交(对于事务性消息)的相对顺序。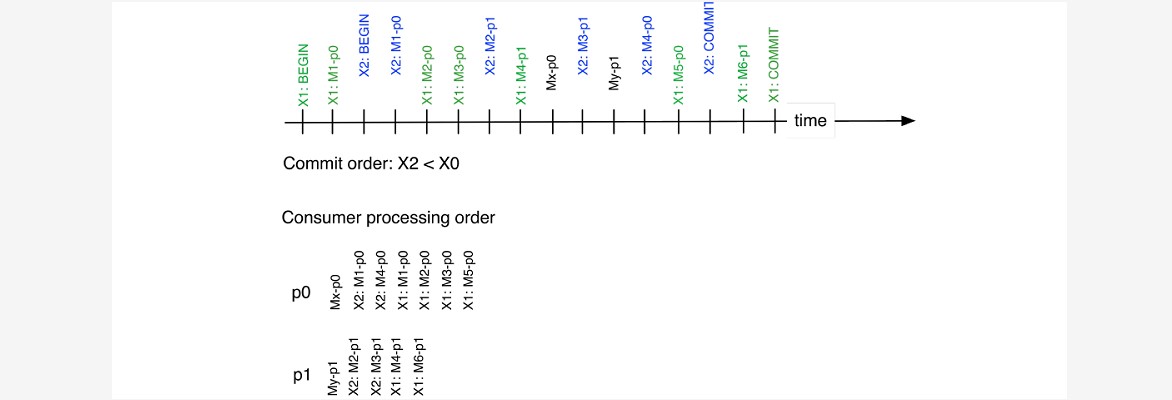
~~~ # 在上图中,分区p0和p1接收事务X1和X2的消息,以及非事务性消息。
~~~ 时间线是消息到达Broker的时间。
~~~ 由于首先提交了X2,所以每个分区都将在X1之前公开来自X2的消息。
~~~ 由于非事务性消息在X1和X2的提交之前到达,因此这些消息将在来自任一事务的消息之前公开。四、事务配置
### --- 创建消费者代码,需要:
~~~ 将配置中的自动提交属性(auto.commit)进行关闭
~~~ 而且在代码里面也不能使用手动提交commitSync( )或者commitAsync( )
~~~ 设置isolation.level:READ_COMMITTED或READ_UNCOMMITTED### --- 创建生成者,代码如下,需要:
~~~ 配置transactional.id属性
~~~ 配置enable.idempotence属性Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv013-kafka



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY