

|NO.Z.00024|——————————|BigDataEnd|——|Hadoop&kafka.V09|——|kafka.v09|生产者原理剖析.v01|
一、原理剖析
### --- [kafka高级特性解析]
~~~ [生产者原理剖析]
~~~ [生产者参数配置] 二、原理剖析
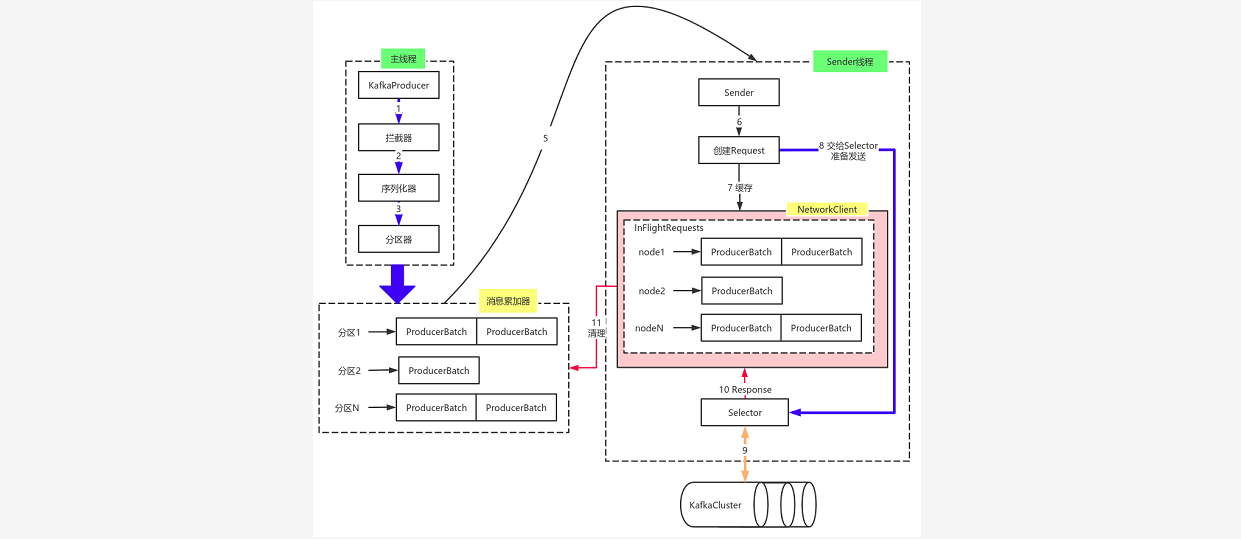
### --- 由上图可以看出:KafkaProducer有两个基本线程:
~~~ # 主线程:
~~~ 负责消息创建,拦截器,序列化器,分区器等操作,并将消息追加到消息收集器RecoderAccumulator中;
~~~ 消息收集器RecoderAccumulator为每个分区都维护了一个Deque<ProducerBatch> 类型的双端队列。
~~~ ProducerBatch 可以理解为是 ProducerRecord 的集合,批量发送有利于提升吞吐量,降低网络影响;
~~~ 由于生产者客户端使用 java.io.ByteBuffer 在发送消息之前进行消息保存,~~~ # 并维护了一个 BufferPool 实现 ByteBuffer 的复用;
~~~ 该缓存池只针对特定大小batch.size 指定ByteBuffer进行管理对于消息过大的缓存,不能做到重复利用。
~~~ 每次追加一条ProducerRecord消息,会寻找/新建对应的双端队列,从其尾部获取一个ProducerBatch,
~~~ 判断当前消息的大小是否可以写入该批次中。
~~~ # 若可以写入则写入;若不可以写入,则新建一个ProducerBatch,
~~~ 判断该消息大小是否超过客户端参数配置 batch.size 的值,不超过,
~~~ 则以 batch.size建立新的ProducerBatch,这样方便进行缓存重复利用;
~~~ 若超过,则以计算的消息大小建立对应的ProducerBatch ,缺点就是该内存不能被复用了。### --- Sender线程:
~~~ 该线程从消息收集器获取缓存的消息,将其处理为 <Node, List<ProducerBatch>的形式,
~~~ Node 表示集群的broker节点。
~~~ 进一步将<Node, List<ProducerBatch>转化为<Node, Request>形式,
~~~ 此时才可以向服务端发送数据。在发送之前,
~~~ Sender线程将消息以 Map<NodeId, Deque<Request>> 的形式保存到 InFlightRequests 中进行缓存,
~~~ 可以通过其获取 leastLoadedNode ,即当前Node中负载压力最小的一个,以实现消息的尽快发出。Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv013-kafka



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通