

|NO.Z.00039|——————————|BigDataEnd|——|Hadoop&Redis.V07|——|Redis.v07|普通Hash|一致性Hash|
一、普通Hash
### --- 普通Hash的优势
~~~ 实现简单,热点数据分布均匀
### --- 普通Hash的缺陷
~~~ 节点数固定,扩展的话需要重新计。
~~~ 查询时必须用分片的key来查,一旦key改变,数据就查不出了,所以要使用不易改变的key进行分片二、一致性hash
### --- 基本概念
~~~ # 普通hash是对主机数量取模,
~~~ 而一致性hash是对2^32(4 294 967 296)取模。我们把2^32想象成一个圆,
~~~ 就像钟表一样,钟表的圆可以理解成由60个点组成的圆,
~~~ 而此处我们把这个圆想象成由2^32个点组成的圆,示意图如下:
~~~ # 圆环的正上方的点代表0,
~~~ 0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1,
~~~ 也就是说0点左侧的第一个点代表2^32-1 。我们把这个由2的32次方个点组成的圆环称为hash环。
~~~ # 假设我们有3台缓存服务器,
~~~ 服务器A、服务器B、服务器C,那么,在生产环境中,这三台服务器肯定有自己的IP地址,
~~~ 我们使用它们各自的IP地址进行哈希计算,使用哈希后的结果对2^32取模,可以使用如下公式: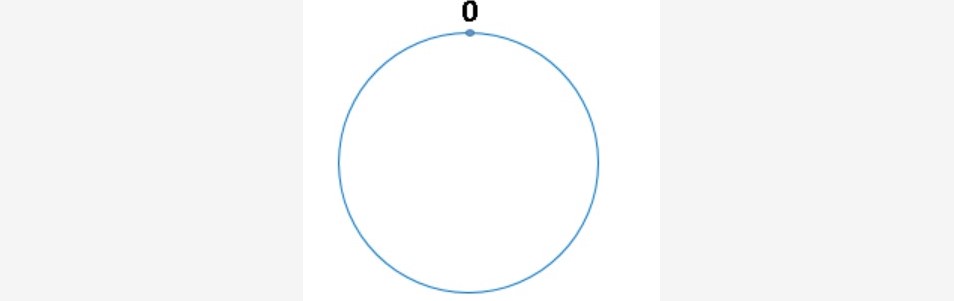
### --- hash(服务器的IP地址) % 2^32
~~~ # 通过上述公式算出的结果一定是一个0到2^32-1之间的一个整数,
~~~ 我们就用算出的这个整数,代表服务器A、服务器B、服务器C,
~~~ 既然这个整数肯定处于0到2^32-1之间,那么,
~~~ 上图中的hash环上必定有一个点与这个整数对应,
~~~ 也就是服务器A、服务器B、服务C就可以映射到这个环上,如下图:
~~~ # 假设,我们需要使用Redis缓存数据,
~~~ 那么我们使用如下公式可以将数据映射到上图中的hash环上。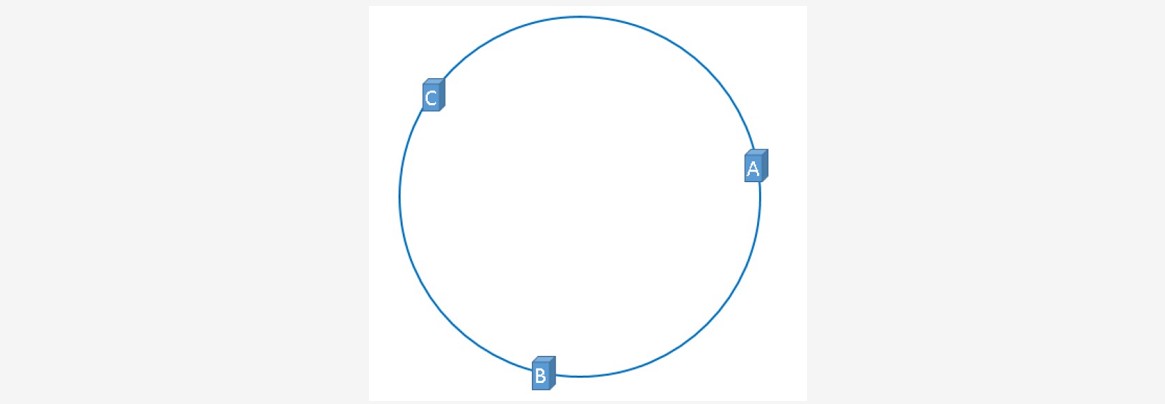
### --- hash(key) % 2^32
~~~ 映射后的示意图如下,下图中的橘黄色圆形表示数据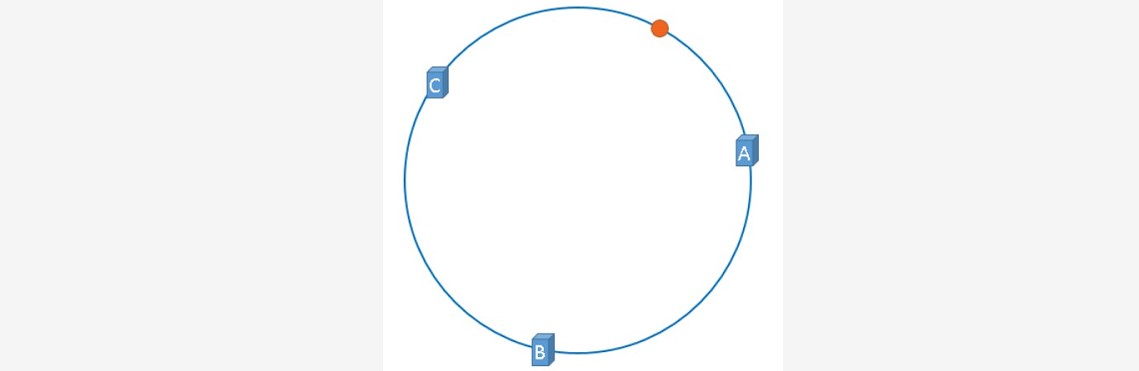
~~~ # 现在服务器与数据都被映射到了hash环上,
~~~ 上图中的数据将会被缓存到服务器A上,因为从数据的位置开始,
~~~ 沿顺时针方向遇到的第一个服务器就是A服务器,所以,上图中的数据将会被缓存到服务器A上。
~~~ 如图: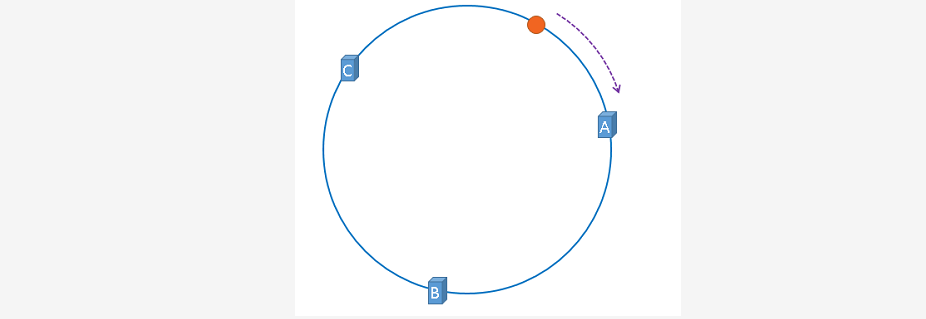
~~~ # 将缓存服务器与被缓存对象都映射到hash环上以后,
~~~ 从被缓存对象的位置出发,沿顺时针方向遇到的第一个服务器,
~~~ 就是当前对象将要缓存于的服务器,由于被缓存对象与服务器hash后的值是固定的,
~~~ 所以,在服务器不变的情况下,数据必定会被缓存到固定的服务器上,
~~~ 那么,当下次想要访问这个数据时,只要再次使用相同的算法进行计算,
~~~ 即可算出这个数据被缓存在哪个服务器上,直接去对应的服务器查找对应的数据即可。
~~~ 多条数据存储如下: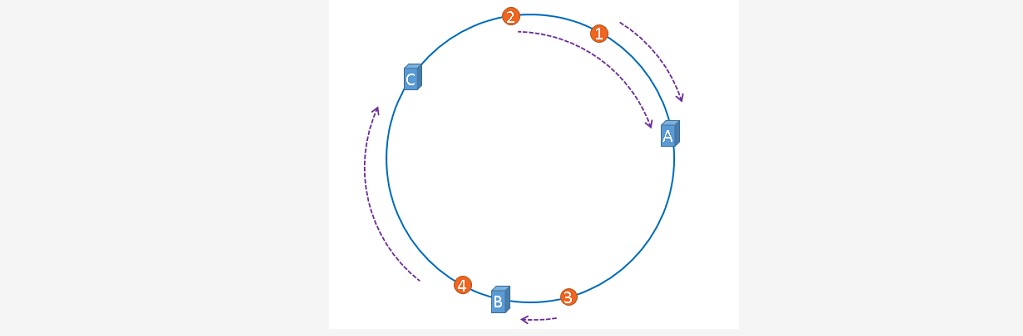
### --- 优点
~~~ 添加或移除节点时,数据只需要做部分的迁移,比如上图中把C服务器移除,
~~~ 则数据4迁移到服务器A中,而其他的数据保持不变。添加效果是一样的。### --- hash环偏移
~~~ 在介绍一致性哈希的概念时,我们理想化的将3台服务器均匀的映射到了hash环上。
~~~ 也就是说数据的范围是2^32/N。但实际情况往往不是这样的。
~~~ 有可能某个服务器的数据会很多,某个服务器的数据会很少,造成服务器性能不平均。
~~~ 这种现象称为hash环偏移。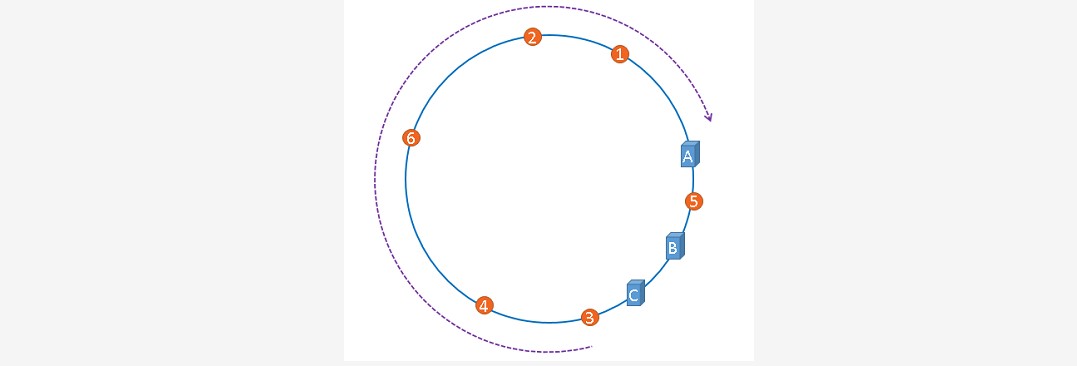
~~~ # 理论上我们可以通过增加服务器的方式来减少偏移,
~~~ 但这样成本较高,所以我们可以采用虚拟节点的方式,也就是虚拟服务器,如图:
~~~ # "虚拟节点"是"实际节点"(实际的物理服务器)在hash环上的复制品,
~~~ 一个实际节点可以对应多个虚拟节点。
~~~ # 从上图可以看出,A、B、C三台服务器分别虚拟出了一个虚拟节点,
~~~ 当然,如果你需要,也可以虚拟出更多的虚拟节点。引入虚拟节点的概念后,
~~~ 缓存的分布就均衡多了,上图中,1号、3号数据被缓存在服务器A中,5号、4号
~~~ 数据被缓存在服务器B中,6号、2号数据被缓存在服务器C中,如果你还不放心,
~~~ 可以虚拟出更多的虚拟节点,以便减小hash环偏斜所带来的影响,虚拟节点越多,
~~~ hash环上的节点就越多,缓存被均匀分布的概率就越大。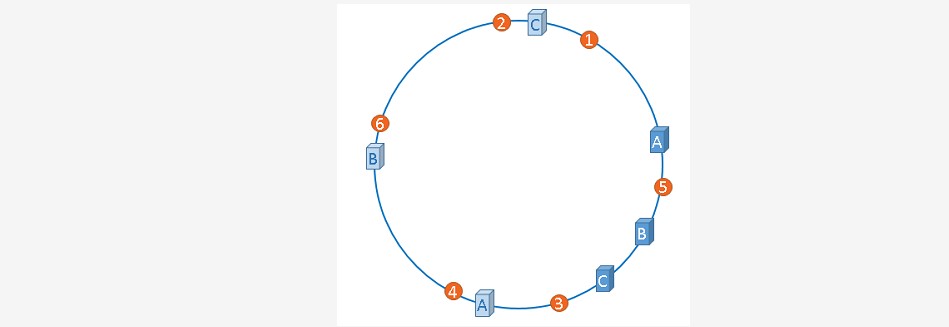
### --- 缺点
~~~ 复杂度高
~~~ 客户端需要自己处理数据路由、高可用、故障转移等问题
~~~ 使用分区,数据的处理会变得复杂,不得不对付多个redis数据库和AOF文件,
~~~ 不得在多个实例和主机之间持久化你的数据。### --- 不易扩展
~~~ 一旦节点的增或者删操作,都会导致key无法在redis中命中,
~~~ 必须重新根据节点计算,并手动迁移全部或部分数据。Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv012-redis



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通