

|NO.Z.00029|——————————|BigDataEnd|——|Hadoop&Hive.V29|——|Hive.v29|Hive优化策略|实战.v05|
一、问题解答:问题1:
### --- 问题1:SQL执行过程中有多少个job(Stage)
~~~ 借助SQL的执行计划可以解答这个问题
hive (tuning)> explain
insert overwrite table student_stat partition(tp)
select s_age, max(s_birth) stat, 'max' tp
from student_txt
group by s_age
union all
select s_age, min(s_birth) stat, 'min' tp
from student_txt
group by s_age;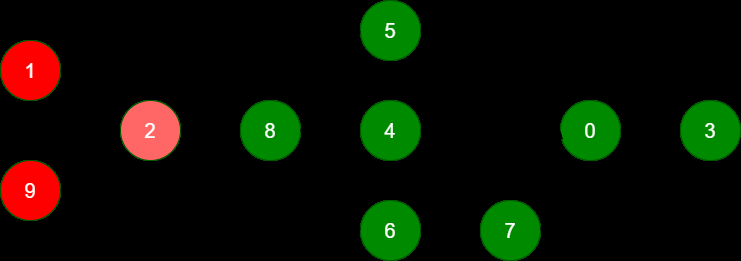
### --- 整个SQL语句分为 10 个Stage
~~~ 其中Stage-1、Stage-9包含 Map Task、Reduce Task
~~~ Stage-2 完成数据合并
~~~ Stage 8、5、4、6、7、0 组合完成数据的插入(动态分区插入)
~~~ Stage-3 收集SQL语句执行过程中的统计信息
~~~ Stage-1、Stage-9、Stage-2 最为关键,占用了整个SQL绝大部分资源二、问题2:
### --- 问题2:为什么在 Stage-1、Stage-9 中都有 9个 Map task、9个 Reduce task
~~~ 决定map task、reduce task的因素比较多,
~~~ 包括文件格式、文件大小(关键因素)、文件数量、参数设置等。下面是两个重要参数:
mapred.max.split.size=256000000
hive.exec.reducers.bytes.per.reducer=256000000
在Map Task中输入数据大小:2193190840 / 256000000 = 9~~~ 如何调整Map task、Reduce task的个数?
~~~ 将这两个参数放大一倍设置,观察是否生效:
~~~ 此时 Map Task、Reduce Task的个数均为5个,执行时间 80S 左右。
hive (tuning)> set mapred.max.split.size=512000000;
hive (tuning)> set hive.exec.reducers.bytes.per.reducer=512000000;
hive (tuning)> insert overwrite table student_stat partition(tp)
select s_age, max(s_birth) stat, 'max' tp
from student_txt
group by s_age
union all
select s_age, min(s_birth) stat, 'min' tp
from student_txt
group by s_age;三、问题3
### --- 问题3:SQL语句是否能优化,如何优化SQL优化
~~~ 参数从 256M => 512M ,有效果
~~~ 参数从 512M => 1024M,效果不明显
~~~ 有效果,说明了一个问题:设置合理的Map、Reduce个数~~~ # 方法一:减少Map、Reduce Task 数
hive (tuning)> set mapred.max.split.size=1024000000;
hive (tuning)> set hive.exec.reducers.bytes.per.reducer=1024000000;
hive (tuning)> insert overwrite table student_stat partition(tp)
select s_age, max(s_birth) stat, 'max' tp
from student_txt
group by s_age
union all
select s_age, min(s_birth) stat, 'min' tp
from student_txt
group by s_age;~~~ # 方法二:减少Stage
~~~ 使用Hive多表插入语句。可以在同一个查询中使用多个 insert 子句,
~~~ 这样的好处是只需要扫描一次源表就可以生成多个不相交的输出。
~~~ 如:insert overwrite table tab2 partition (age)
from tab1
insert overwrite table tab2 partition (age)
select name,address,school,age
insert overwrite table tab3
select name,address
where age>24;~~~ # 多表插入的关键点:
~~~ 从同一张表选取数据,可以将选取的数据插入其他不同的表中(也可以是相同的表)
~~~ 将 "from 表名",放在SQL语句的头部~~~ # 按照这个思路改写以上的SQL语句:
~~~ 开启动态分区插入
hive (tuning)> set hive.exec.dynamic.partition=true;
hive (tuning)> set hive.exec.dynamic.partition.mode=nonstrict;~~~ # 优化后的SQL
hive (tuning)> from student_txt
insert overwrite table student_stat partition(tp)
select s_age, max(s_birth) stat, 'max' tp
group by s_age
insert overwrite table student_stat partition(tp)
select s_age, min(s_birth) stat, 'min' tp
group by s_age;~~~ # 执行计划
~~~ 减少 stage,最关键的是减少了一次数据源的扫描,性能得到了提升。
hive (tuning)> explain
from student_txt
insert overwrite table student_stat partition(tp)
select s_age, max(s_birth) stat, 'max' tp
group by s_age
insert overwrite table student_stat partition(tp)
select s_age, min(s_birth) stat, 'min' tp
group by s_age;四、文件格式
### --- 创建表插入数据,改变表的存储格式
hive (tuning)> create table student_parquet
stored as parquet
as
select * from student_txt;
hive (tuning)> select count(1) from student_parquet;### --- 仅创建表结构,改变表的存储格式,但是分区的信息丢掉了
hive (tuning)> create table student_stat_parquet
stored as parquet
as
select * from student_stat where 1>2;### --- 重新创建表
hive (tuning)> drop table student_stat_parquet;
hive (tuning)> create table student_stat_parquet
(age int,
b string)
partitioned by (tp string)
stored as parquet;### --- CTAS建表语句(CREATE TABLE AS SELECT)
~~~ 使用查询创建并填充表,select中选取的列名会作为新表的列名会改变表的属性、结构,只能是内部表、分区分桶也没有了
~~~ CTAS创建表存储格式变成默认格式TEXTFILE,可以在CTAS语句中指定表的存储格式,行和列的分隔符等
~~~ 字段的注释comment也会丢掉### --- 更改表的存储格式后,数据文件大小在50M左右。
hive (tuning)> explain select count(1) from student_parquet;
OK
Explain
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Fetch Operator
limit: 1
Processor Tree:
ListSink### --- parquet 文件保存了很多的元数据信息,
~~~ 所以这里没有Map、Reduce Task,直接从文件中的元数据就可以获取记录行数。
~~~ 使用parquet文件格式再执行SQL语句,此时符合本地模式的使用条件,执行速度非常快,
~~~ 仅 20S 左右;禁用本地模式后,执行时间也在 40S 左右。
hive (tuning)> from student_parquet
insert into table student_stat_parquet partition(tp)
select s_age, min(s_birth) stat, 'min' tp
group by s_age
insert into table student_stat_parquet partition(tp)
select s_age, max(s_birth) stat, 'max' tp
group by s_age;
~~~ # 禁用本地模式
set hive.exec.mode.local.auto=false;### --- 小结:
~~~ 减少了对数据源的扫描
~~~ 使用了列式存储格式Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通