

|NO.Z.00025|——————————|BigDataEnd|——|Hadoop&Hive.V25|——|Hive.v25|Hive优化策略|实战.v01|
一、Hive调优策略
~~~ [Hive优化策略之架构优化]
~~~ [Hive优化策略之本地模式,严格模式JVM重用]
~~~ [Hive优化策略之并行执行/推测执行/合并小文件及fetch模式]
~~~ [Hive优化策略之列分区裁剪/sortBy及groupBy]
~~~ [Hive优化策略之join的三重方式]
~~~ [Hive优化策略之调整Map及Reduce个数]
~~~ [Hive优化策略之优化策略小结]
~~~ [Hive优化实战之数据说明及SQL案例]
~~~ [Hive优化实战之后执行计划分析]
~~~ [Hive优化实战之问题解答]
~~~ [Hive优化实战之SQL优化]
~~~ [Hive优化实战之文件格式]### --- Hive调优策略
~~~ Hive作为大数据领域常用的数据仓库组件,在设计和开发阶段需要注意效率。
~~~ 影响Hive效率的不仅仅是数据量过大;
~~~ 数据倾斜、数据冗余、job或I/O过多、MapReduce分配不合理等因素都对Hive的效率有影响。### --- 对Hive的调优既包含对HiveQL语句本身的优化,也包含Hive配置项和MR方面的调整。
~~~ # 从以下三个方面展开:
~~~ 架构优化
~~~ 参数优化
~~~ SQL优化二、架构优化
### --- 执行引擎
~~~ Hive支持多种执行引擎,分别是 MapReduce、Tez、Spark、Flink。
~~~ 可以通过hivesite.xml文件中的hive.execution.engine属性控制。
~~~ Tez是一个构建于YARN之上的支持复杂的DAG(有向无环图)任务的数据处理框架。
~~~ 由Hontonworks开源,将MapReduce的过程拆分成若干个子过程,
~~~ 同时可以把多个mapreduce任务组合成一个较大的DAG任务,减少了MapReduce之间的文件存储,
~~~ 同时合理组合其子过程从而大幅提升MR作业的性能。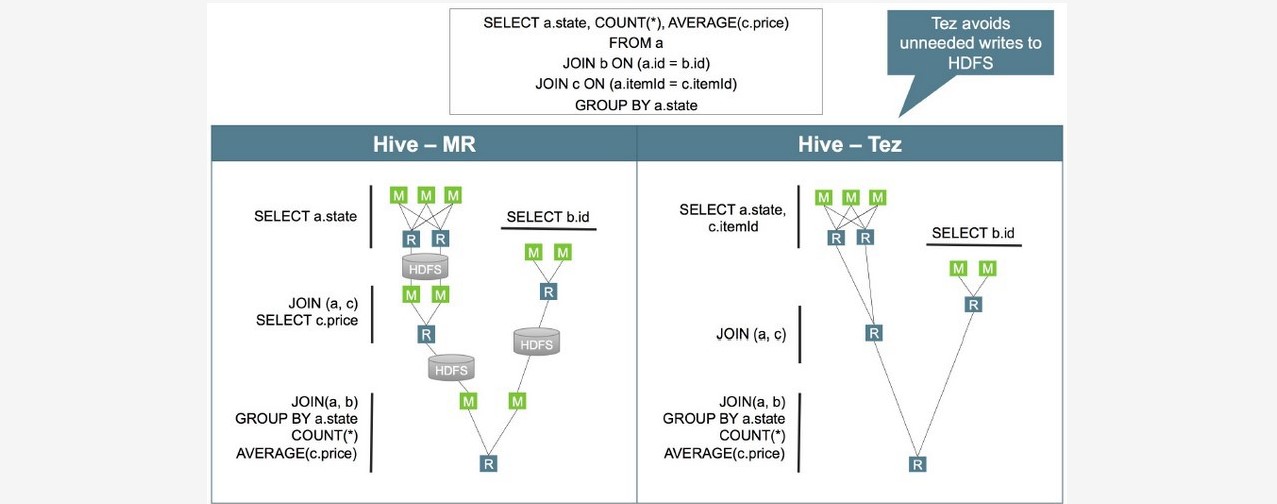
### --- 优化器
~~~ 与关系型数据库类似,Hive会在真正执行计算之前,生成和优化逻辑执行计划与物理执行计划。
~~~ Hive有两种优化器:Vectorize(向量化优化器) 与 Cost-Based Optimization (CBO 成本优化器)。
### --- 矢量化查询执行
~~~ 矢量化查询(要求执行引擎为Tez)执行通过一次批量执行1024行而不是每行一行来提高扫描,
~~~ 聚合,过滤器和连接等操作的性能,这个功能一显着缩短查询执行时间。### --- 备注:要使用矢量化查询执行,必须用ORC格式存储数据
set hive.vectorized.execution.enabled = true; -- 默认 false
set hive.vectorized.execution.reduce.enabled = true; -- 默认 false### --- 成本优化器
~~~ Hive的CBO是基于apache Calcite的,
~~~ Hive的CBO通过查询成本(有analyze收集的统计信息)会生成有效率的执行计划,
~~~ 最终会减少执行的时间和资源的利用,使用CBO的配置如下:SET hive.cbo.enable=true; --从 v0.14.0默认
true
SET hive.compute.query.using.stats=true; -- 默认false
SET hive.stats.fetch.column.stats=true; -- 默认false
SET hive.stats.fetch.partition.stats=true; -- 默认true### --- 定期执行表(analyze)的分析,分析后的数据放在元数据库中。
~~~ # 分区表
~~~ 对于一张比较大的表,将其设计成分区表可以提升查询的性能,对于一个特定分区的查询,
~~~ 只会加载对应分区路径的文件数据,所以执行速度会比较快。
~~~ 分区字段的选择是影响查询性能的重要因素,尽量避免层级较深的分区,
~~~ # 这样会造成太多的子文件夹。一些常见的分区字段可以是:
~~~ 日期或时间。如year、month、day或者hour,当表中存在时间或者日期字段时
~~~ 地理位置。如国家、省份、城市等
~~~ 业务逻辑。如部门、销售区域、客户等等### --- 分桶表
~~~ 与分区表类似,分桶表的组织方式是将HDFS上的文件分割成多个文件。
~~~ 分桶可以加快数据采样,也可以提升join的性能(join的字段是分桶字段),
~~~ 因为分桶可以确保某个key对应的数据在一个特定的桶内(文件),
~~~ 巧妙地选择分桶字段可以大幅度提升join的性能。
~~~ 通常情况下,分桶字段可以选择经常用在过滤操作或者join操作的字段。### --- 文件格式
~~~ 在HiveQL的create table语句中,可以使用stored as ... 指定表的存储格式。
~~~ Hive表支持的存储格式有TextFile、SequenceFile、RCFile、ORC、Parquet等。
~~~ 存储格式一般需要根据业务进行选择,生产环境中绝大多数表都采用TextFile、ORC、Parquet存储格式之一。
~~~ TextFile是最简单的存储格式,它是纯文本记录,也是Hive的默认格式。
~~~ 其磁盘开销大,查询效率低,更多的是作为跳板来使用。
~~~ RCFile、ORC、Parquet等格式的表都不能由文件直接导入数据,必须由TextFile来做中转。
~~~ Parquet和ORC都是Apache旗下的开源列式存储格式。
~~~ 列式存储比起传统的行式存储更适合批量OLAP查询,并且也支持更好的压缩和编码。
~~~ 选择Parquet的原因主要是它支持Impala查询引擎,并且对update、delete和事务性操作需求很低。### --- 数据压缩
~~~ 压缩技术可以减少map与reduce之间的数据传输,从而可以提升查询性能,
~~~ 关于压缩的配置可以在hive的命令行中或者hive-site.xml文件中进行配置。
SET hive.exec.compress.1 intermediate=true二、开启压缩之后,可以选择下面的压缩格式:
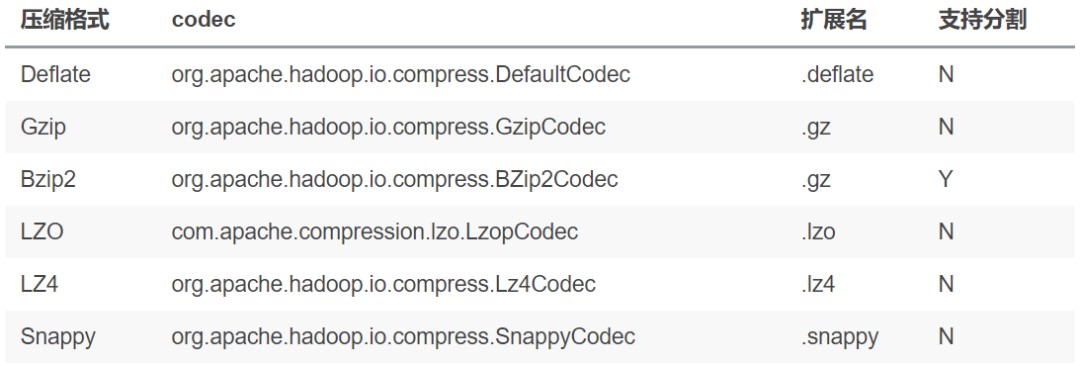
三、关于压缩的编码器可以通过mapred-site.xml, hive-site.xml进行配置也可以通过命令行进行配置如:
### --- 中间结果压缩
SET hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec ;
### --- 输出结果压缩
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodc### --- 设计阶段:
~~~ 执行引擎
~~~ 优化器
~~~ 分区、分桶
~~~ 文件格式
~~~ 数据压缩Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通