

|NO.Z.00015|——————————|BigDataEnd|——|Hadoop&Hive.V15|——|Hive.v15|Hive函数用法.v03|
一、窗口函数【重要】
### --- 窗口函数
~~~ 窗口函数又名开窗函数,属于分析函数的一种。
~~~ 用于解决复杂报表统计需求的功能强大的函数,很多场景都需要用到。
~~~ 窗口函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:
~~~ 对于每个组返回多行,而聚合函数对于每个组只返回一行。
~~~ 窗口函数指定了分析函数工作的数据窗口大小,
~~~ 这个数据窗口大小可能会随着行的变化而变化。### --- over 关键字
~~~ 使用窗口函数之前一般要要通过over()进行开窗
~~~ 查询emp表工资总和
hive (mydb)> select sum(sal) from emp;
29025~~~ # 不使用窗口函数,有语法错误
~~~ 注意:窗口函数是针对每一行数据的;如果over中没有参数,默认的是全部结果集;
hive (mydb)> select ename, sal, sum(sal) salsum from emp;
~~~ # 使用窗口函数,查询员工姓名、薪水、薪水总和
hive (mydb)> select ename, sal, sum(sal) over() salsum,
concat(round(sal / sum(sal) over()*100, 1) || '%')
ratiosal
from emp;
--输出参数二、partition by子句
### --- 在over窗口中进行分区,对某一列进行分区统计,窗口的大小就是分区的大小
~~~ # 查询员工姓名、薪水、部门薪水总和
hive (mydb)> select ename, sal, sum(sal) over(partition by deptno) salsum from emp;
--输出参数
ename sal salsum ratiosal
MILLER 1300 29025 4.5%
FORD 3000 29025 10.3%
JAMES 950 29025 3.3%
ADAMS 1100 29025 3.8%三、order by 子句
### --- order by 子句对输入的数据进行排序
~~~ # 增加了order by子句;sum:从分组的第一行到当前行求和
hive (mydb)> select ename, sal, deptno, sum(sal) over(partition by deptno
order by sal) salsum
from emp;
--输出参数
ename sal deptno salsum
JAMES 950 30 950
WARD 1250 30 3450
MARTIN 1250 30 3450四、Window子句
### --- 如果要对窗口的结果做更细粒度的划分,使用window子句,有如下的几个选项:
~~~ unbounded preceding。组内第一行数据
~~~ n preceding。组内当前行的前n行数据
~~~ current row。当前行数据
~~~ n following。组内当前行的后n行数据
~~~ unbounded following。组内最后一行数据
hive (mydb)> rows 1 between ... and ...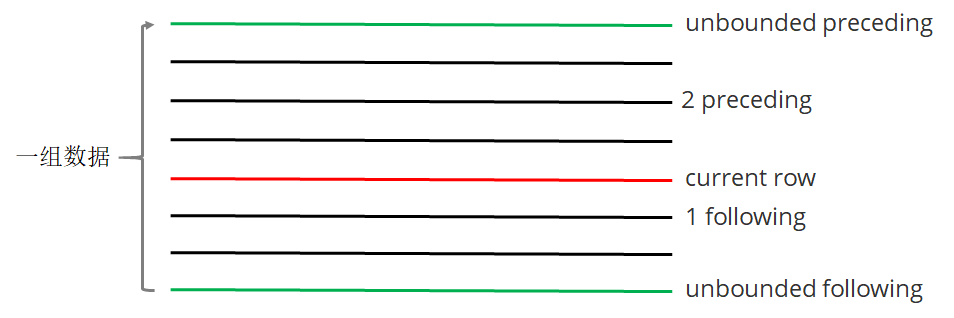
~~~ # rows between ... and ... 子句
~~~ # 等价。组内,第一行到当前行的和
hive (mydb)> select ename, sal, deptno,
sum(sal) over(partition by deptno order by ename) from
emp;
--输出参数
ename sal deptno sum_window_0
ALLEN 1600 30 1600
BLAKE 2850 30 4450
JAMES 950 30 5400hive (mydb)> select ename, sal, deptno,
sum(sal) over(partition by deptno order by ename
rows between unbounded preceding and
current row
)
from emp;
--输出参数
ename sal deptno sum_window_0
ALLEN 1600 30 1600
BLAKE 2850 30 4450
JAMES 950 30 5400~~~ # 组内,第一行到最后一行的和
hive (mydb)> select ename, sal, deptno,
sum(sal) over(partition by deptno order by ename
rows between unbounded preceding and
unbounded following
)
from emp;
--输出参数
ename sal deptno sum_window_0
ALLEN 1600 30 9400
BLAKE 2850 30 9400
JAMES 950 30 9400~~~ # 组内,前一行、当前行、后一行的和
hive (mydb)> select ename, sal, deptno,
sum(sal) over(partition by deptno order by ename
rows between 1 preceding and 1 following
)
from emp;
--输出参数
ename sal deptno sum_window_0
ALLEN 1600 30 4450
BLAKE 2850 30 5400
JAMES 950 30 5050
MARTIN 1250 30 3700五、排名函数
### --- 排名函数
~~~ 都是从1开始,生成数据项在分组中的排名。
~~~ row_number()。排名顺序增加不会重复;如1、2、3、4、... ...
~~~ RANK()。 排名相等会在名次中留下空位;如1、2、2、4、5、... ...
~~~ DENSE_RANK()。 排名相等会在名次中不会留下空位 ;如1、2、2、3、4、... ...### --- row_number / rank / dense_rank
100 1 1 1
100 2 1 1
100 3 1 1
99 4 4 2
98 5 5 3
98 6 5 3
97 7 7 4### --- 数据准备
[root@linux123 ~]# vim /home/hadoop/data/t2.dat
class1 s01 100
class1 s03 100
class1 s05 100
class1 s07 99
class1 s09 98
class1 s02 98
class1 s04 97
class2 s21 100
class2 s24 99
class2 s27 99
class2 s22 98
class2 s25 98
class2 s28 97
class2 s26 96~~~ # 创建表加载数据
hive (mydb)> create table t2(
cname string,
sname string,
score int
) row format delimited fields terminated by '\t';
hive (mydb)> load data local inpath '/home/hadoop/data/t2.dat' into table t2;~~~ # 按照班级,使用3种方式对成绩进行排名
hive (mydb)> select cname, sname, score,
row_number() over (partition by cname order by score desc) rank1,
rank() over (partition by cname order by score desc) rank2,
dense_rank() over (partition by cname order by score desc) rank3
from t2;
--参数输出
cname sname score rank1 rank2 rank3
class2 s21 100 1 1 1
class2 s27 99 2 2 2
class2 s24 99 3 2 2
class2 s25 98 4 4 3
class2 s22 98 5 4 3~~~ # 求每个班级前3名的学员--前3名的定义是什么--假设使用dense_rank
hive (mydb)> select cname, sname, score, rank
from (select cname, sname, score,
dense_rank() over (partition by cname order by
score desc) rank
from t2) tmp
where rank <= 3;
--参数输出
cname sname score rank
class2 s21 100 1
class2 s24 99 2
class2 s27 99 2
class2 s25 98 3六、序列函数
### --- 序列函数
~~~ lag。返回当前数据行的上一行数据
~~~ lead。返回当前数据行的下一行数据
~~~ first_value。取分组内排序后,截止到当前行,第一个值
~~~ last_value。分组内排序后,截止到当前行,最后一个值
~~~ ntile。将分组的数据按照顺序切分成n片,返回当前切片值~~~ # 测试数据 userpv.dat。cid ctime pv
[root@linux123 ~]# vim /home/hadoop/data/userpv.dat
cookie1,2019-04-10,1
cookie1,2019-04-11,5
cookie1,2019-04-12,7
cookie1,2019-04-13,3
cookie1,2019-04-14,2
cookie1,2019-04-15,4
cookie1,2019-04-16,4
cookie2,2019-04-10,2
cookie2,2019-04-11,3
cookie2,2019-04-12,5
cookie2,2019-04-13,6
cookie2,2019-04-14,3
cookie2,2019-04-15,9
cookie2,2019-04-16,7~~~ # 建表语句
hive (mydb)> create table userpv(
cid string,
ctime date,
pv int
)
row format delimited fields terminated by ",";~~~ # 加载数据
hive (mydb)> Load data local inpath '/home/hadoop/data/userpv.dat' into
table userpv;~~~ # lag。返回当前数据行的上一行数据
~~~ # lead。功能上与lag类似
hive (mydb)> select cid, ctime, pv,
lag(pv) over(partition by cid order by ctime) lagpv,
lead(pv) over(partition by cid order by ctime) leadpv
from userpv;
--参数输出
cid ctime pv lagpv leadpv
cookie2 2019-04-10 2 NULL 3
cookie2 2019-04-11 3 2 5
cookie2 2019-04-12 5 3 6
cookie2 2019-04-13 6 5 3
cookie2 2019-04-14 3 6 9~~~ # first_value / last_value
hive (mydb)> select cid, ctime, pv,
first_value(pv) over (partition by cid order by ctime
rows between unbounded preceding and unbounded following) as
firstpv,
last_value(pv) over (partition by cid order by ctime
rows between unbounded preceding and unbounded following) as
lastpv
from userpv;
--参数输出
cid ctime pv firstpv lastpv
cookie2 2019-04-10 2 2 7
cookie2 2019-04-11 3 2 7
cookie2 2019-04-12 5 2 7
cookie2 2019-04-13 6 2 7~~~ # ntile。按照cid进行分组,每组数据分成2份
hive (mydb)> select cid, ctime, pv,
ntile(2) over(partition by cid order by ctime) ntile
from userpv;
--参数输出
cid ctime pv ntile
cookie2 2019-04-10 2 1
cookie2 2019-04-11 3 1
cookie2 2019-04-12 5 1
cookie2 2019-04-13 6 1Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通