

|NO.Z.00046|——————————|BigDataEnd|——|Hadoop&MapReduce.V19|——|Hadoop.v19|MapReduce数据压缩机制|
一、shuffle阶段数据的压缩机制
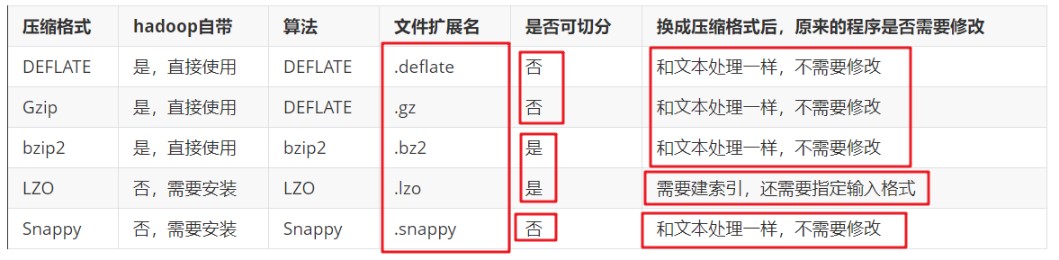
### --- Hadoop当中支持的额压缩算法
~~~ 数据压缩有两大好处,节约磁盘空间,加速数据在网络和磁盘上的传输!!
~~~ 我们可以使用bin/hadoop checknative 来查看我们编译之后的hadoop支持的各种压缩,
~~~ 如果出现openssl为false,那么就在线安装一下依赖包!!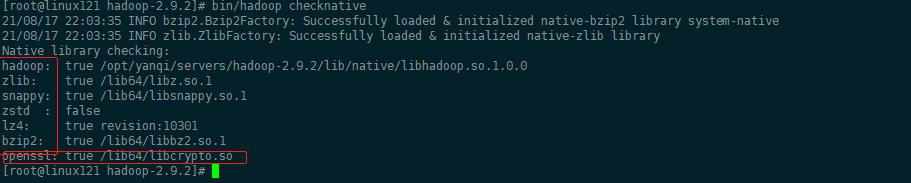
### --- 安装openssl
[root@linux121 hadoop-2.9.2]# bin/hadoop checknative| 压缩格式 |
hadoop自带
|
算法 |
文件扩展名
|
是否可切分
|
换成压缩格式后,原来的程序是否需要修改
|
| DEFLATE |
是,直接使用
|
DEFLATE | .deflate | 否 | 和文本处理一样,不需要修改 |
| Gzip |
是,直接使用
|
DEFLATE | .gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 |
是,直接使用
|
bzip2 | .bz2 | 是 | 和文本处理一样,不需要修改 |
| LZO |
否,需要安装
|
LZO | .lzo | 是 |
需要建索引,还需要指定输入格式
|
| Snappy |
否,需要安装
|
Snappy | .snappy | 否 | 和文本处理一样,不需要修改 |
二、为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器
| 压缩格式 | 对应的编码/解码器 |
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
三、常见压缩方式对比分析
| 压缩算法 | 原始文件大小 | 压缩后的文件大小 | 压缩速度 | 解压缩速度 |
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 9.5MB/s |
| bzip2 | 8.3GB | 1.1GB | 1.1GB | 2.4MB/s |
| LZO-bset | 8.3GB | 2GB | 4MB/s | 60.6MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/S | 74.6MB/s |
### --- 压缩位置
~~~ # Map输入端压缩
~~~ 此处使用压缩文件作为Map的输入数据,无需显示指定编解码方式,
~~~ Hadoop会自动检查文件扩展名,如果压缩方式能够匹配,
~~~ Hadoop就会选择合适的编解码方式对文件进行压缩和解压。
~~~ # Map输出端压缩
~~~ Shuffle是Hadoop MR过程中资源消耗最多的阶段,如果有数据量过大造成网络传输速度缓慢,
~~~ 可以考虑使用压缩
~~~ # Reduce端输出压缩
~~~ 输出的结果数据使用压缩能够减少存储的数据量,降低所需磁盘的空间,
~~~ 并且作为第二个MR的输入时可以复用压缩。四、压缩配置方式
### --- 在驱动代码中通过Configuration直接设置使用的压缩方式,可以开启Map输出和Reduce输出压缩
~~~ # 设置map阶段压缩
Configuration configuration = new Configuration();
configuration.set("mapreduce.map.output.compress","true");
configuration.set("mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");~~~ # 设置reduce阶段的压缩
configuration.set("mapreduce.output.fileoutputformat.compress","true");
configuration.set("mapreduce.output.fileoutputformat.compress.type","RECORD");
configuration.set("mapreduce.output.fileoutputformat.compress.codec","org.ap
ache.hadoop.io.compress.SnappyCodec");### --- 配置mapred-site.xml(修改后分发到集群其它节点,重启Hadoop集群),
~~~ 此种方式对运行在集群的所有MR任务都会执行压缩。
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>RECORD</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>五、压缩案例
### --- 需求
~~~ 使用snappy压缩方式压缩WordCount案例的输出结果数据六、代码实现
### --- 具体实现
~~~ 在驱动代码中添加压缩配置
configuration.set("mapreduce.output.fileoutputformat.compress","true");
configuration.set("mapreduce.output.fileoutputformat.compress.type","RECORD");
configuration.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");### --- 编程代码:创建项目snappy
~~~ countmapper
package com.yanqi.mr.snappy;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//需求:单词计数
//1 继承Mapper类
//2 Mapper类的泛型参数:共4个,2对kv
//2.1 第一对kv:map输入参数类型
//2.2 第二队kv:map输出参数类型
// LongWritable, Text-->文本偏移量(后面不会用到),一行文本内容
//Text, IntWritable-->单词,1
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//3 重写Mapper类的map方法
/*
1 接收到文本内容,转为String类型
2 按照空格进行切分
3 输出<单词,1>
*/
//提升为全局变量,避免每次执行map方法都执行此操作
final Text word = new Text();
final IntWritable one = new IntWritable(1);
// LongWritable, Text-->文本偏移量,一行文本内容,map方法的输入参数,一行文本就调用一次map方法
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 接收到文本内容,转为String类型
final String str = value.toString();
// 2 按照空格进行切分
final String[] words = str.split(" ");
// 3 输出<单词,1>
//遍历数据
for (String s : words) {
word.set(s);
context.write(word, one);
}
}
}### --- wordcountreducer
package com.yanqi.mr.snappy;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//继承的Reducer类有四个泛型参数,2对kv
//第一对kv:类型要与Mapper输出类型一致:Text, IntWritable
//第二队kv:自己设计决定输出的结果数据是什么类型:Text, IntWritable
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
//1 重写reduce方法
//Text key:map方法输出的key,本案例中就是单词,
// Iterable<IntWritable> values:一组key相同的kv的value组成的集合
IntWritable total = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//2 遍历key对应的values,然后累加结果
int sum = 0;
for (IntWritable value : values) {
int i = value.get();
sum += 1;
}
// 3 直接输出当前key对应的sum值,结果就是单词出现的总次数
total.set(sum);
context.write(key, total);
/*
假设map方法:hello 1;hello 1;hello 1
reduce的key和value是什么?
key:hello,
values:<1,1,1>
假设map方法输出:hello 1;hello 1;hello 1,hadoop 1, mapreduce 1,hadoop 1
reduce的key和value是什么?
reduce方法何时调用:一组key相同的kv中的value组成集合然后调用一次reduce方法
第一次:key:hello ,values:<1,1,1>
第二次:key:hadoop ,values<1,1>
第三次:key:mapreduce ,values<1>
*/
}
}### --- wordcountdriver
package com.yanqi.mr.snappy;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//封装任务并提交运行
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
/*
1. 获取配置文件对象,获取job对象实例
2. 指定程序jar的本地路径
3. 指定Mapper/Reducer类
4. 指定Mapper输出的kv数据类型
5. 指定最终输出的kv数据类型
6. 指定job处理的原始数据路径
7. 指定job输出结果路径
8. 提交作业
*/
// 1. 获取配置文件对象,获取job对象实例
final Configuration conf = new Configuration();
//针对reduce端输出使用snappy压缩
conf.set("mapreduce.output.fileoutputformat.compress", "true");
conf.set("mapreduce.output.fileoutputformat.compress.type", "RECORD");
conf.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
final Job job = Job.getInstance(conf, "WordCountDriver");
// 2. 指定程序jar的本地路径
job.setJarByClass( WordCountDriver.class);
// 3. 指定Mapper/Reducer类
job.setMapperClass( WordCountMapper.class);
job.setReducerClass( WordCountReducer.class);
// 4. 指定Mapper输出的kv数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5. 指定最终输出的kv数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6. 指定job读取数据路径
FileInputFormat.setInputPaths(job, new Path(args[0])); //指定读取数据的原始路径
// 7. 指定job输出结果路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); //指定结果数据输出路径
// 8. 提交作业
final boolean flag = job.waitForCompletion(true);
//jvm退出:正常退出0,非0值则是错误退出
System.exit(flag ? 0 : 1);
}
}### --- 使用maven打成jar包
~~~ 生成jar包:maven:package——>将jar包上传到Hadoop集群中——>END
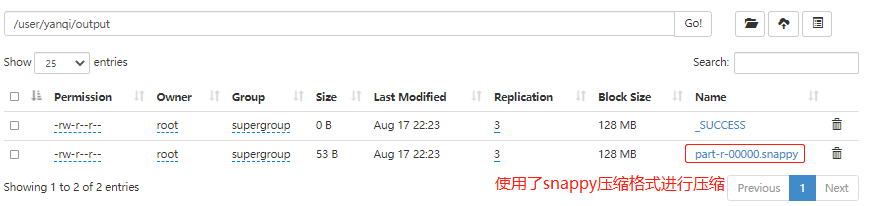
~~~ 重新打成jar包,提交集群运行,验证输出结果是否已进行了snappy压缩!!### --- 运行程序
[root@linux121 ~]# hadoop jar snappy.jar com.yanqi.mr.snappy.WordCountDriver /user/yanqi/input /user/yanqi/output七、查看输出结果
Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通