

|NO.Z.00032|——————————|BigDataEnd|——|Hadoop&MapReduce.V05|——|Hadoop.v05|MapRedice之writable序列化接口|
一、序列化Writable接口
~~~ [MapRedice之writable序列化接口]
~~~ [MapRedice之writable序列化接口案例part01]
~~~ [MapRedice之writable序列化接口案例part02]
~~~ [MapRedice之writable序列化接口案例part03]
~~~ [MapRedice之writable序列化接口案例本地运行] ### --- 序列化writable序列化接口
~~~ 基本序列化类型往往不能满足所有需求,比如在Hadoop框架内部传递一个自定义bean对象,
~~~ 那么该对象就需要实现Writable序列化接口。二、实现Writable序列化步骤如下
### --- 必须实现Writable接口
### --- 反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public CustomBean() {
super();
}### --- 重写序列化方法
@Override
public void write(DataOutput out) throws IOException {
....
}### --- 重写反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
....
}~~~ 反序列化的字段顺序和序列化字段的顺序必须完全一致
~~~ 方便展示结果数据,需要重写bean对象的toString()方法,可以自定义分隔符
~~~ 如果自定义Bean对象需要放在Mapper输出KV中的K,则该对象还需实现Comparable接口,
~~~ 因为因为MapReduce框中的Shuffle过程要求对key必须能排序!!### --- 排序内容专门案例讲解!!
@Override
public int compareTo(CustomBean o) {
// 自定义排序规则
return this.num > o.getNum() ? -1 : 1;
}三、Writable接口案例
### --- 需求
~~~ 统计每台智能音箱设备内容播放时长
~~~ 原始日志格式
001 001577c3 kar_890809 120.196.100.99 1116 954 200
日志id 设备id appkey(合作硬件厂商) 网络ip 自有内容时长(秒) 第三方内容时长(秒) 网络状态码~~~ # 输出结果
001577c3 11160 9540 20700
设备id 自有内容时长(秒) 第三方内容时长(秒) 总时长四、编写MapReduce程序
### --- 创建项目:speak
### --- 创建SpeakBean对象
package com.yanqi.mr.speak;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//这个类型是map输出kv中value的类型,需要实现writable序列化接口
public class SpeakBean implements Writable {
//定义属性
private Long selfDuration;//自有内容时长
private Long thirdPartDuration;//第三方内容时长
private String deviceId;//设备id
private Long sumDuration;//总时长
//准备一个空参构造
public SpeakBean() {
}
//序列化方法:就是把内容输出到网络或者文本中
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(selfDuration);
out.writeLong(thirdPartDuration);
out.writeUTF(deviceId);
out.writeLong(sumDuration);
}
//有参构造
public SpeakBean(Long selfDuration, Long thirdPartDuration, String deviceId) {
this.selfDuration = selfDuration;
this.thirdPartDuration = thirdPartDuration;
this.deviceId = deviceId;
this.sumDuration = this.selfDuration + this.thirdPartDuration;
}
//反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
this.selfDuration = in.readLong();//自由时长
this.thirdPartDuration = in.readLong();//第三方时长
this.deviceId = in.readUTF();//设备id
this.sumDuration = in.readLong();//总时长
}
public Long getSelfDuration() {
return selfDuration;
}
public void setSelfDuration(Long selfDuration) {
this.selfDuration = selfDuration;
}
public Long getThirdPartDuration() {
return thirdPartDuration;
}
public void setThirdPartDuration(Long thirdPartDuration) {
this.thirdPartDuration = thirdPartDuration;
}
public String getDeviceId() {
return deviceId;
}
public void setDeviceId(String deviceId) {
this.deviceId = deviceId;
}
public Long getSumDuration() {
return sumDuration;
}
public void setSumDuration(Long sumDuration) {
this.sumDuration = sumDuration;
}
//为了方便观察数据,重写toString()方法
@Override
public String toString() {
return
selfDuration +
"\t" + thirdPartDuration +
"\t" + deviceId + "\t" + sumDuration;
}
}### --- 编写Mapper类
package com.yanqi.mr.speak;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//四个参数:分为两对kv
//第一对kv:map输入参数的kv类型;k-->一行文本偏移量,v-->一行文本内容
//第二对kv:map输出参数kv类型;k-->map输出的key类型,v:map输出的value类型
public class SpeakMapper extends Mapper<LongWritable, Text, Text, SpeakBean> {
/*
1 转换接收到的text数据为String
2 按照制表符进行切分;得到自有内容时长,第三方内容时长,设备id,封装为SpeakBean
3 直接输出:k-->设备id,value-->speakbean
*/
Text device_id = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 转换接收到的text数据为String
final String line = value.toString();
// 2 按照制表符进行切分;得到自有内容时长,第三方内容时长,设备id,封装为SpeakBean
final String[] fields = line.split("\t");
//自有内容时长
String selfDuration = fields[fields.length - 3];
//第三方内容时长
String thirdPartDuration = fields[fields.length - 2];
//设备id
String deviceId = fields[1];
final SpeakBean bean = new SpeakBean(Long.parseLong(selfDuration), Long.parseLong(thirdPartDuration), deviceId);
// 3 直接输出:k-->设备id,value-->speakbean
device_id.set(deviceId);
context.write(device_id, bean);
}
}### --- 编写Reducer
package com.yanqi.mr.speak;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SpeakReducer extends Reducer<Text, SpeakBean, Text, SpeakBean> {
@Override
protected void reduce(Text key, Iterable<SpeakBean> values, Context context) throws IOException, InterruptedException {
//定义时长累加的初始值
Long self_duration = 0L;
Long third_part_duration = 0L;
//reduce方法的key:map输出的某一个key
//reduce方法的value:map输出的kv对中相同key的value组成的一个集合
//reduce 逻辑:遍历迭代器累加时长即可
for (SpeakBean bean : values) {
final Long selfDuration = bean.getSelfDuration();
final Long thirdPartDuration = bean.getThirdPartDuration();
self_duration += selfDuration;
third_part_duration += thirdPartDuration;
}
//输出,封装成一个bean对象输出
final SpeakBean bean = new SpeakBean(self_duration, third_part_duration, key.toString());
context.write(key, bean);
}
}### --- 编写驱动
package com.yanqi.mr.speak;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class SpeakDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
final Configuration conf = new Configuration();
final Job job = Job.getInstance(conf, "speakDriver");
//设置jar包本地路径
job.setJarByClass(SpeakDriver.class);
//使用的mapper和reducer
job.setMapperClass(SpeakMapper.class);
job.setReducerClass(SpeakReducer.class);
//map的输出kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(SpeakBean.class);
//设置reduce输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(SpeakBean.class);
//读取的数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交任务
final boolean flag = job.waitForCompletion(true);
System.exit(flag ? 0 : 1);
}
}五、运行程序
### --- 运行程序
~~~ 配置程序接收的文件参数:speak.data
~~~ 查看统计结果
~~~ mr编程技巧总结
~~~ 结合业务设计Map输出的key和v,利用key相同则去往同一个reduce的特点!!
~~~ map()方法中获取到只是一行文本数据尽量不做聚合运算
~~~ reduce()方法的参数要清楚含义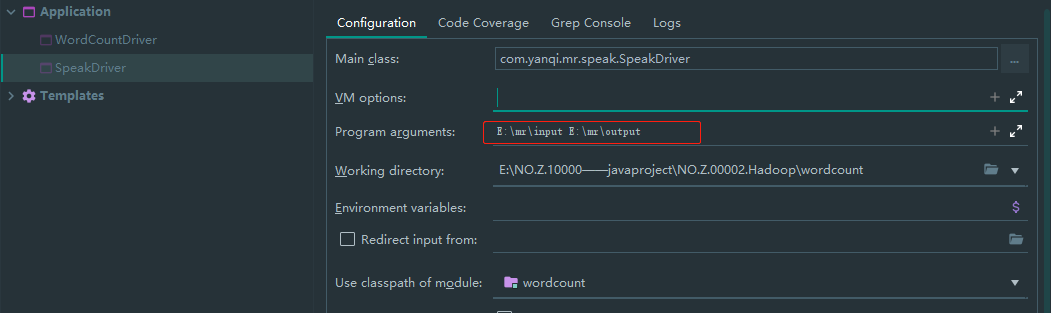

Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通