
【笔记】机器学习 - 李宏毅 - 16 - Word Embedding
从one-hot到word embedding
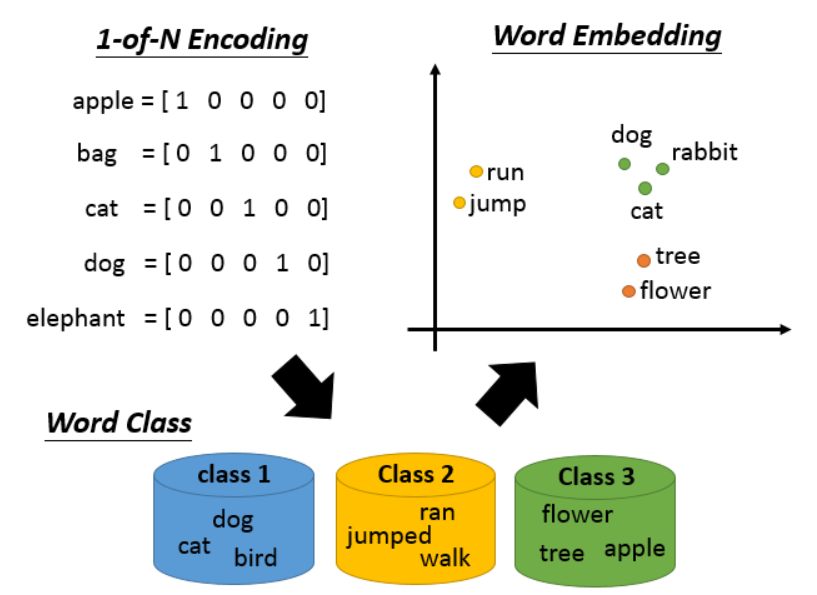
词表示最直觉的做法是1-of-N Encoding, 向量维度和词表大小一样,每个词在其中某一维为1,其他维为0。这种表示法无法体现出词之间的关系。
word class方法是将意思相似或者同种属性的词归为一类,但这种划分太粗糙了,而且需要很多人工设计。
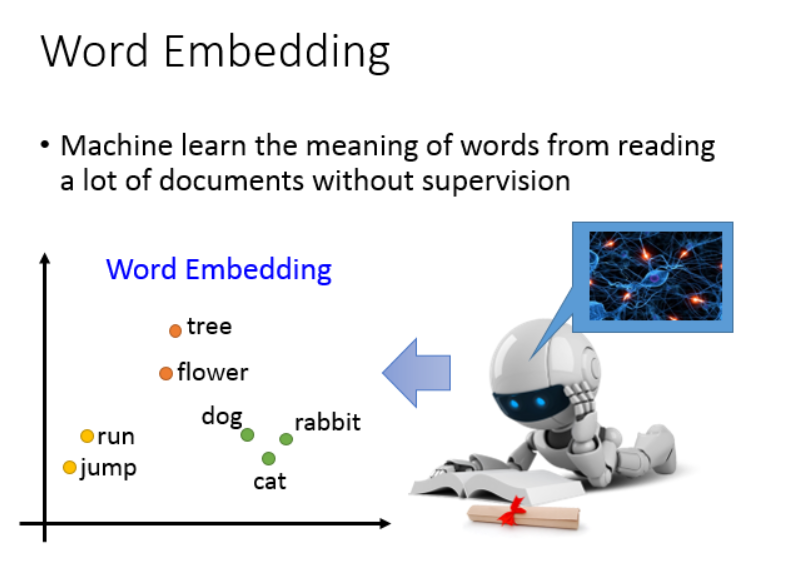
word embedding也是一种降维操作,不过是通过无监督的方法从文本中学出来的。最终学得的结果,可以在向量空间的距离上体现出词之间的关系。
基于计数的词嵌入
为了进行这种无监督学习,我们可以采用auto-encoder,从词的上下文context中学习。
count based的方法是基于共现关系的,如果两个词经常一起出现,那么这两个词就是相关的。比如Glove就是这样做的。
这就要求两个词的词向量的内积和他们在同一个文章中出现的次数相近。

基于预测的词嵌入
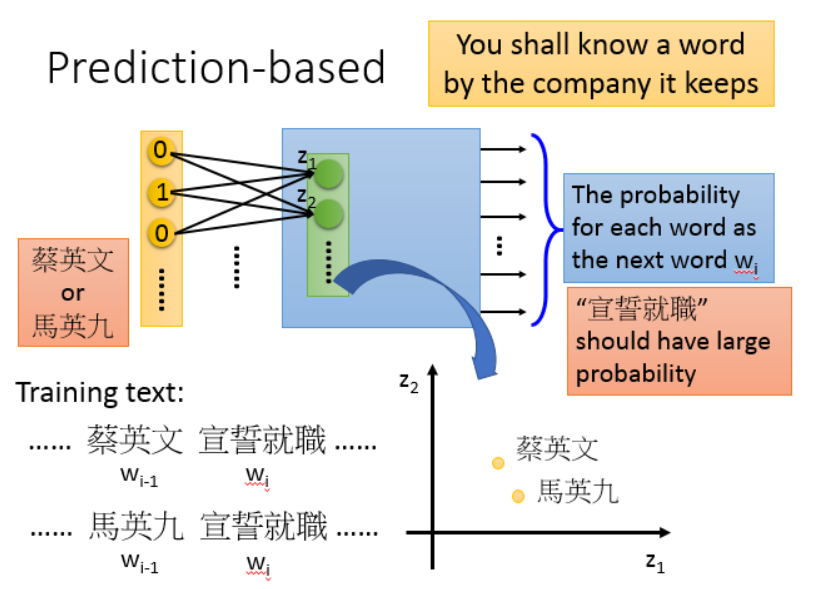
词预测的做法是输入前一个词的one-hot向量,然后输出后一个在所有词上的概率,网络训练好之后,把第一个隐层向量取出来就可以作为word embedding。

那么这种方法是怎么体现出词的相似性的呢?
为了能够让两个不同的词预测出同样的下文,那么这两个词的向量就要相近甚至相同。(因为总有些上下文是不同的,所以这两个词向量一般不会完全一样)
但是用一个词去预测下一个词,这种预测能力太弱了,所以我们会用更多的词(>10),但这会使模型参数的数量急剧上升。
所以我们用了共享参数的方法,但这种方法的缺点是,input的词失去了位置信息,因为词不同的顺序组合表达出来的意思其实是不一样的。
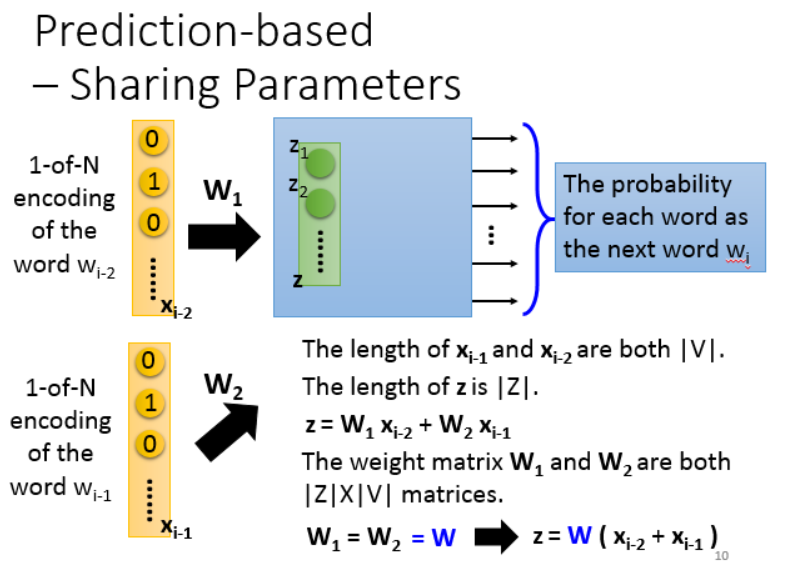
怎么让参数一样呢,首先初始值要一样,其次在参数更新的时候,同时减去双方的偏微分。

训练的话,最小化交叉熵就可以了。
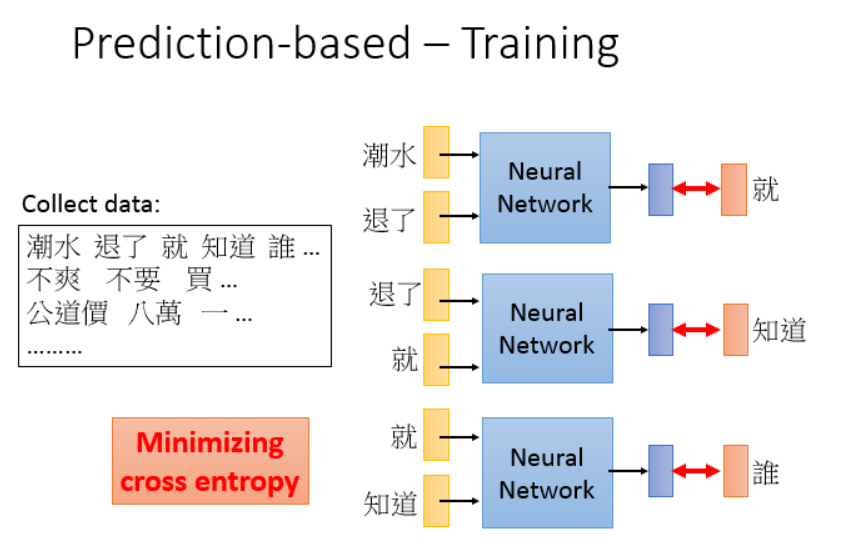
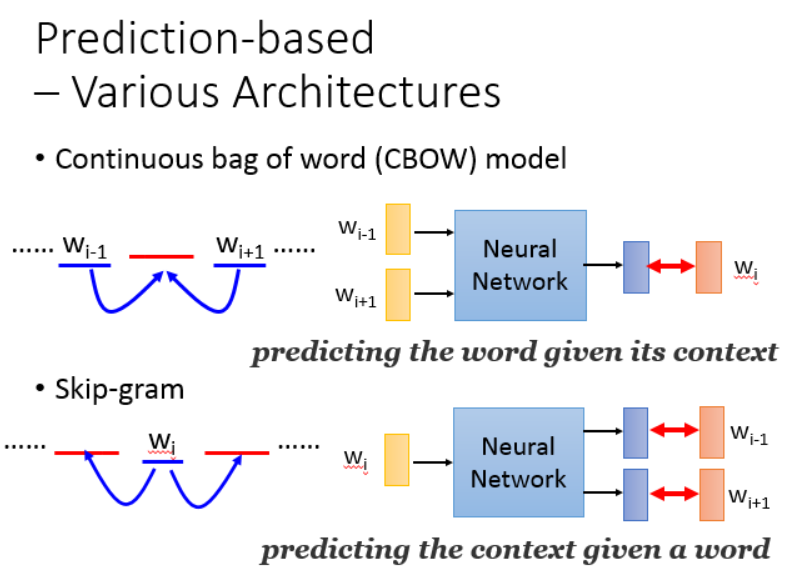
此外还有很多种训练方法,CBoW,skip-gram等,各有千秋。
不过这个网络不是深层网络,而只是一个线性的hidden layer,
一方面是计算量的考虑,层数少训练更快,另外一方面是因为很多NLP任务,这个后面还要深层网络,所以这里就不用做那么深。
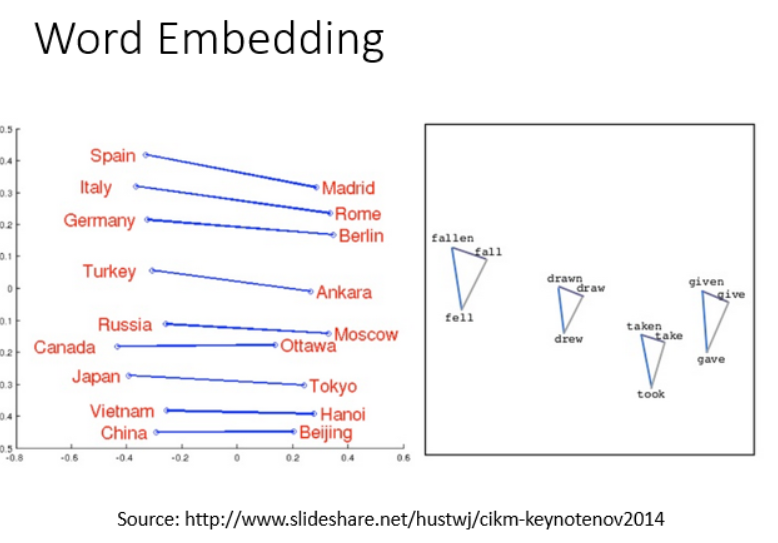
然后可以得到很多词关系的有趣结果。(只需要向量相减就可以,比如 中国 - 北京 ~= 美国 - 纽约)
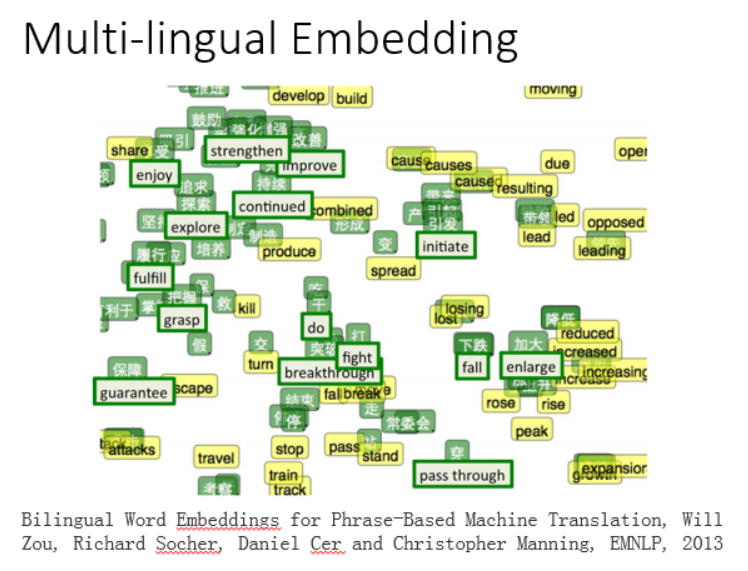
甚至还可以在多个语言之间做这个(翻译)。
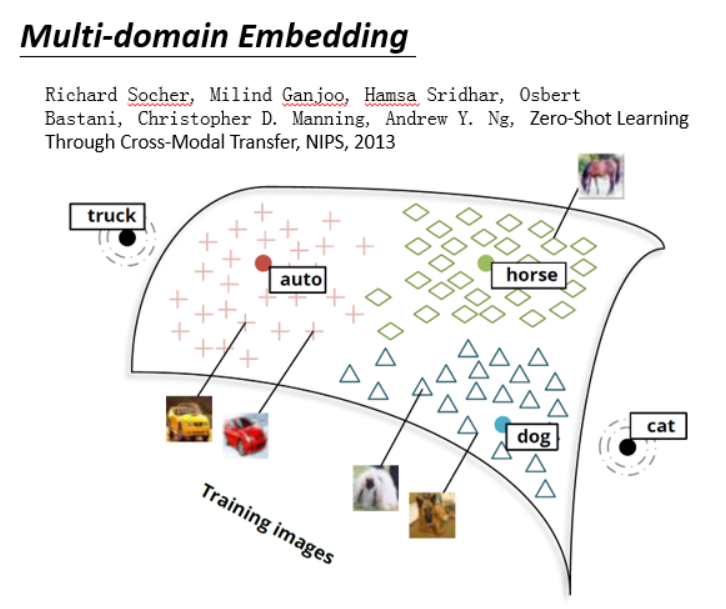
图像也可以做这个。
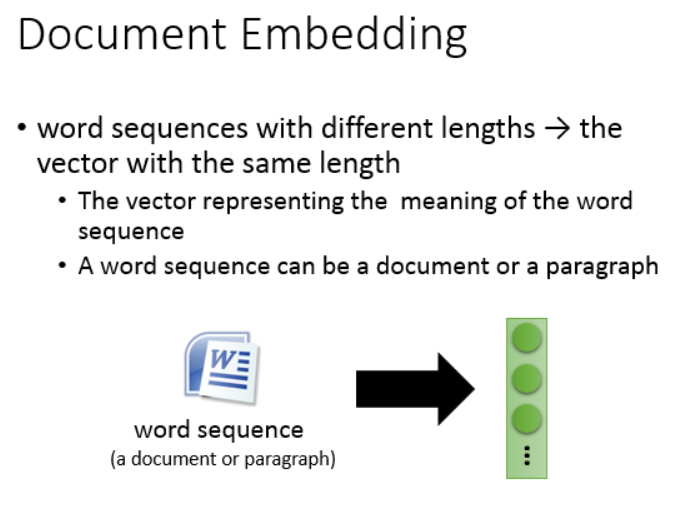
对于文章的话,也可以表示成向量。
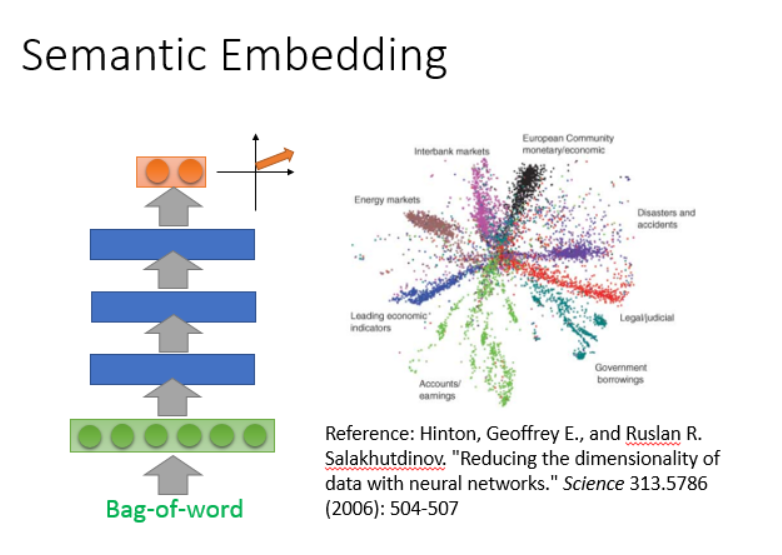
最简单的方法就像上面一样,把文章表示成词袋,然后用auto-encoder学出semantic embedding。
但是词的顺序是影响语义的,这里给了一些参考文献,前面是无监督的,后面是有监督的方法。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号