
【敏感词检测】用DFA构建字典树完成敏感词检测任务
任务概述
敏感词检测是各类平台对用户发布内容(UGC)进行审核的必做任务。
对于文本内容做敏感词检测,最简单直接的方法就是规则匹配。构建一个敏感词词表,然后与文本内容进行匹配,如发现有敏感词,则提交报告给人工审核或者直接加以屏蔽。
当然也可以用机器学习的方法来做,不过需要收集及标注大量数据,有条件的话也可以加以实现。
任务难点及解决策略
1)对抗检测的场景:比如同音替换、字形替换、隐喻暗指、词中间插入特殊字符等。
解决策略:特殊字符可以使用特殊字符词表过滤,其他几种不好解决,主要通过扩大敏感词表规模来。
2)断章取义的问题:从语义上理解没有问题,但按窗口大小切出几个字来看,却属于敏感词,造成误报。
解决策略:这个问题主要是分词错误导致的,应当考虑分词规则,而不是无脑遍历,或者用正则匹配。
3)检测效率问题:随着词表的增大,循环查找词表的速度会变得很慢。
解决策略:使用DFA算法构建字典树。
4)词的歧义问题:一个词某个义项是违规的,但其他义项或许是正常的。
解决策略:这个要结合上下文考虑,机器学习类的方法比较容易解决这一问题。
5)词表质量问题:从网络上获取得到的敏感词词表,要么包含词汇较少,不能满足检测需求,要么包含词汇过多,检测出了很多当前业务场景下不需要屏蔽的词。
解决策略:需要定期人工整理。
敏感词字典树的构建
构建字典树使用的是确定有限自动机(DFA)。DFA算法的核心是建立了以敏感词为基础的许多敏感词树。
它的基本思想是基于状态转移来检索敏感词,只需要扫描一次待检测文本(长度n),就能对所有敏感词进行检测。
且DFA算法的时间复杂度O(n)基本上是与敏感词的个数无关的,只与文本长度有关。
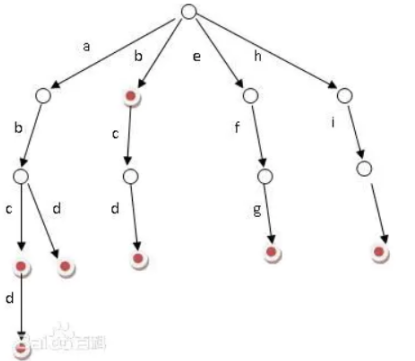
如下图所示,比如abcd,abd,bcd,efg,hij这几个词在树中表示如下。
中文的常用字只有四五千个,但由这些字构成的词却难以计数,如果循环遍历,时间消耗极大,而通过字典树,沿着根节点向下,每走一步就可以极大地缩小搜索空间。
代码实现
import jieba
min_match = 1 # 最小匹配原则
max_match = 2 # 最大匹配原则
class SensitiveWordDetect:
def __init__(self, sensitive_words_path, stopWords_path):
#============把敏感词库加载到列表中====================
temp_line_list = []
with open(sensitive_words_path, 'r', encoding='utf-8') as file:
temp_line_list = file.readlines()
self.sensitive_word_list = sorted([i.split('\n')[0] for i in temp_line_list])
# print(self.sensitive_word_list[-10:])
#============把停用词加载到列表中======================
temp_line_list_2 = []
with open(stopWords_path, 'r', encoding='utf-8') as file:
temp_line_list_2 = file.readlines()
self.stop_word_list = [i.split('\n')[0] for i in temp_line_list_2]
#==============得到sensitive字典=======================
self.sensitive_word_map = self.init_sensitive_word_map(self.sensitive_word_list)
#print(self.sensitive_word_map)
#print(len(self.sensitive_word_map))
# 构建敏感词库
def init_sensitive_word_map(self, sensitive_word_list):
sensitive_word_map = {}
# 读取每一行,每一个word都是一个敏感词
for word in sensitive_word_list:
now_map = sensitive_word_map
# 遍历该敏感词的每一个特定字符
for i in range(len(word)):
keychar = word[i]
word_map = now_map.get(keychar)
if word_map != None:
# now_map更新为下一层
now_map = word_map
else:
# 不存在则构建一个map, isEnd设置为0,因为不是最后一个
new_next_map = {}
new_next_map["isEnd"] = 0
now_map[keychar] = new_next_map
now_map = new_next_map
# 到这个词末尾字符
if i == len(word)-1:
now_map["isEnd"] = 1
# print(sensitive_word_map)
return sensitive_word_map
def check_sensitive_word(self, txt, begin_index=0, match_mode=min_match):
'''
:param txt: 输入待检测的文本
:param begin_index:输入文本开始的下标
:return:返回敏感词字符的长度
'''
now_map = self.sensitive_word_map
sensitive_word_len = 0 # 敏感词的长度
contain_char_sensitive_word_len = 0 # 包括特殊字符敏感词的长度
end_flag = False #结束标记位
for i in range(begin_index, len(txt)):
char = txt[i]
if char in self.stop_word_list:
contain_char_sensitive_word_len += 1
continue
now_map = now_map.get(char)
if now_map != None:
sensitive_word_len += 1
contain_char_sensitive_word_len += 1
# 结束位置为True
if now_map.get("isEnd") == 1:
end_flag = True
# 最短匹配原则
if match_mode == min_match:
break
else:
break
if end_flag == False:
contain_char_sensitive_word_len = 0
#print(sensitive_word_len)
return contain_char_sensitive_word_len
def get_sensitive_word_list(self, txt):
# 去除停止词
new_txt = ''
for char in txt:
if char not in self.stop_word_list:
new_txt += char
# 然后分词
seg_list = list(jieba.cut(new_txt, cut_all=False))
cur_txt_sensitive_list = []
# 注意,并不是一个个char查找的,找到敏感词会增强敏感词的长度
for i in range(len(txt)):
length = self.check_sensitive_word(txt, i, match_mode=max_match)
if length > 0:
word = txt[i:i+length]
cur_txt_sensitive_list.append(word)
i = i+length-1 # 出了循环还要+1 i+length是没有检测到的,下次直接从i+length开始
# 对得到的结果和分词结果进行匹配,不匹配的不要
rst_list = []
for line in cur_txt_sensitive_list:
new_line = ''
for char in line:
if char not in self.stop_word_list:
new_line += char
if new_line in seg_list:
rst_list.append(line)
return rst_list
def replace_sensitive_word(self, txt, replace_char='*'):
lst = self.get_sensitive_word_list(txt)
#print(lst)
# 如果需要加入的关键词,已经在关键词列表存在了,就不需要继续添加
def judge(lst, word):
if len(lst) == 0:
return True
for str in lst:
if str.count(word) != 0:
return False
return True
# 最严格的打码,选取最长打码长度
for word in lst:
replace_str = len(word) * replace_char
txt = txt.replace(word, replace_str)
new_lst = []
for word in lst:
new_word = ""
# newWord是除去停用词、最精炼版本的敏感词
for char in word:
if char in self.stop_word_list:
continue
new_word += char
length = self.check_sensitive_word(new_word, 0, match_mode=min_match)
if judge(new_lst, new_word[:length]):
new_lst.append(new_word[:length])
else:
continue
return txt, new_lst # 最终返回的结果是屏蔽敏感词后的文本,以及检测出的敏感词

 浙公网安备 33010602011771号
浙公网安备 33010602011771号