
【知识总结】预训练语言模型BERT的发展由来
语言模型
语言模型是根据语言客观事实对语言进行抽象数学建模。可以描述为一串单词序列的概率分布:
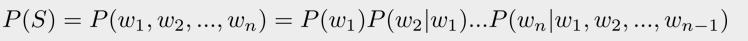
通过极大化L可以衡量一段文本是否更像是自然语言(根据文本出现的概率):
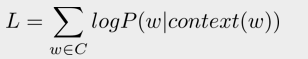
函数P的核心在于,可以根据上文预测后面单词的概率(也可以引入下文联合预测)。
其中一种很常用的语言模型就是神经网络语言模型。
神经网络语言模型NNLM:
给定上文的单词,利用神经网络来预测当前位置的单词。即最大化:
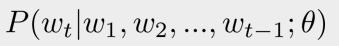
模型结构如下图所示,首先将one-hot表示的词向量通过look-up表,也就是矩阵Q,转换为word embedding的表示,作为输入层。
训练刚开始用随机值初始化矩阵Q,随着网络训练好之后,矩阵Q的内容也被正确赋值了。所以Word Embedding是NNLM的副产物。
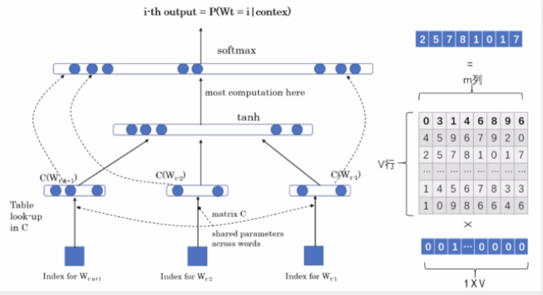
这个Word Embedding其实可以单独拿出来用于下游任务,所以就有了专门预训练Word Embedding的word2vec。
预训练语言模型
预训练首先在计算机视觉领域ImageNet上取得了突破性的进展,人们发现底层的网络可以捕捉到边角弧线等基础特征,而高层网络捕捉到的特征更为复杂,与下游任务更相关。
所以底层网络其实是可以在不同的任务间通用的,而高层网络则可以根据任务进行调整。
底层的网络参数抽取出特征跟具体任务越无关,则越具备任务的通用性。
而高层特征跟具体任务的关联较大,实际任务中可以不使用,或者采用Fine-tuning的方法,用新数据集合清洗掉高层无关的特征抽取器。
这种思想后来也被用到了NLP领域。
Word2Vec:
word2vec的主要目的就是训练得到Word Embedding词向量,有两种训练方式:CBOW(用上下文来预测当前词),skip-gram(用当前词预测上下文单词)。
此外,为了减少计算量,还使用了Negative Sampling,Hierarchical Softmax等方法。
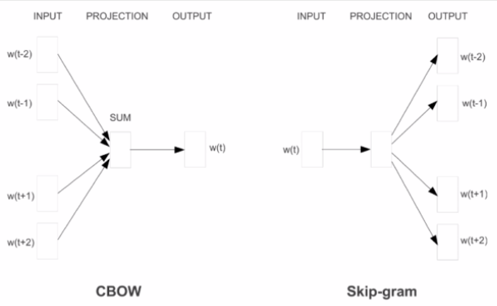
对于下游任务,将句子中的每个词以one-hot的形式输入,然后乘以预训练得到的word embedding矩阵,从而取出对应的词向量。
使用方式有两种:
1)Frozen:embedding层的网络参数不动;
2)Fine-Tuning: embedding层的参数跟着训练过程一起更新。
不过,这种Word Embedding无法区分一词多义(因为同一个词占用的是同一行的参数空间),然而单词的歧义在语言中广泛存在(多义性是语言信息编码的灵活性和高效性的表现)。
为了解决这一问题,就出现了以下一些预训练模型。以下这些模型不仅可以得到预训练的词向量,还可以得到预训练好的网络参数,用于下游任务fine-tune。
ELMo:
ELMo的两个阶段:1)预训练,2)将各层的Embedding作为新特征补充到下游任务中(基于特征融合)。
不仅学到了单词的Embedding,还学到了一个双层双向的LSTM的网络结构。
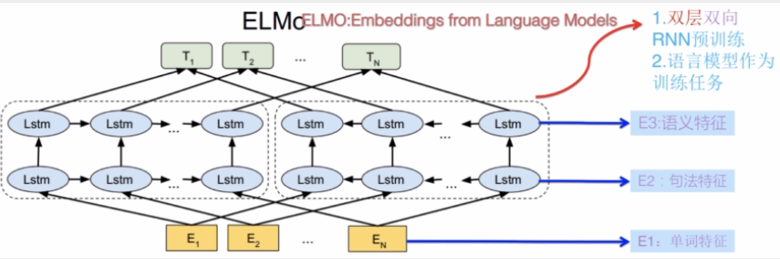
缺点(对比后来出现的GPT/BERT):1)特征提取:LSTM的特征抽取能力远低于Transformer
2)特征融合:浅层的双向拼接,特征融合能力比较弱
GPT:
特点:1)特征抽取器采用Transformer,抽取能力优于RNN;
2)采用单向的语言模型(漏掉了很多有用信息)(只使用了Transformer的Decoder,所以是单向的)
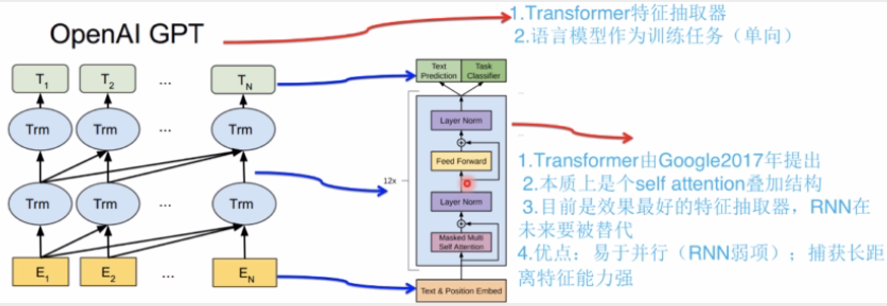
GPT的两阶段:1)预训练,2)通过Fine-tuning解决下游任务(基于Fine-tuning)。
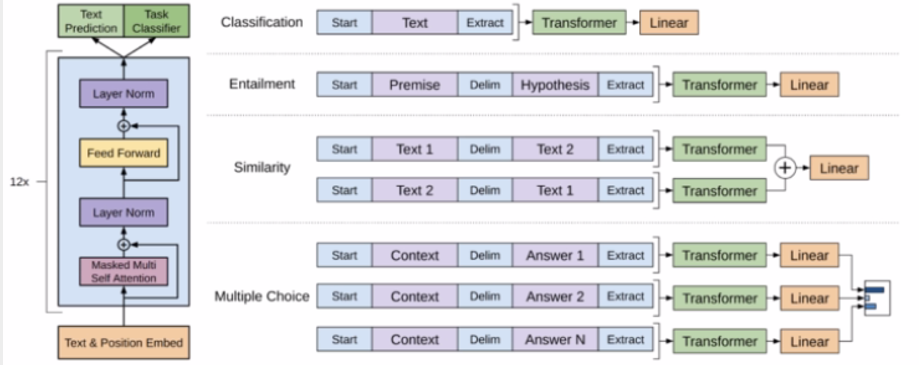
Fine-tuning: 对于下游任务,将任务的网络结构改造成和GPT一样,使用GPT的参数来初始化。(下图是不同任务上fine-tune的方法)
BERT:
BERT模型就是预训练模型的集大成者,刷新了很多任务的benchmark,而且因其通用性,可以应用于很多NLP任务,所以得到了广泛的使用和传播。
BERT模型借鉴了很多以往模型的方法,创新不多,其主要创新点在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
BERT的特点:1)使用Transformer作为特征抽取器,2)预训练的时候采用了双向语言模型。(结合了ELMo和GPT的优点)
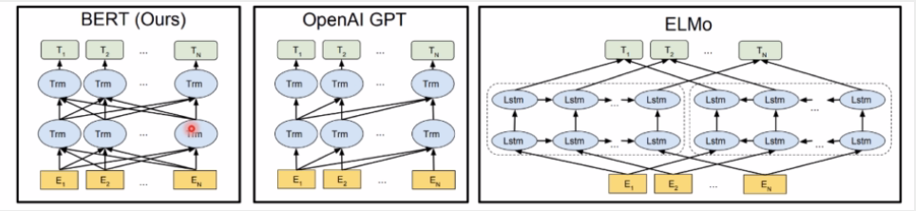
BERT是一种自编码的语言模型。
AutoEncoder(自编码器)是为了避免过拟合,会以一定概率抹掉input矩阵。这种破损数据训练出来的噪声较小,因为噪声也在一定程度上被擦除了,减轻了训练数据与测试数据的GAP。
BERT就是基于DAE(去噪自编码器),在BERT中称为Masked LM。
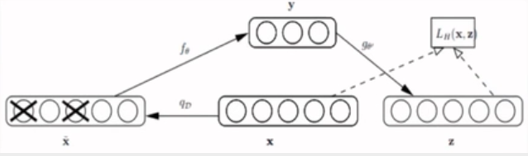
备注:
Autoregressive ML: 根据上文预测下一个单词,即LTR任务,或者反过来,从右到左。(ELMo, GPT, XLNET)
Autoencoder ML: 让语言模型试图去还原原始输入的系统。(BERT, RoBerta)
相关资料
NNLM: Yoshua Bengio. A Neural Probabilistic Language Model. JMLR. 2003.
Word2Vec: Efficient Estimation of Word Representations in Vector Space. Tomas Mikolov. 2013. https://arxiv.org/abs/1301.3781v3 (Mikolov是Bengio的高徒)
ELMo: Deep contextualized word representations. Matthew E. Peters. 2018. https://arxiv.org/abs/1802.05365
GPT: Improving Language Understanding by Generative Pre-Training. OpenAI. 2018. https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. 2018. https://arxiv.org/abs/1810.04805
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史,张俊林. https://zhuanlan.zhihu.com/p/49271699
放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较。张俊林。 https://zhuanlan.zhihu.com/p/54743941

 浙公网安备 33010602011771号
浙公网安备 33010602011771号