

【论文翻译】Deep Speech 2(百度, 2015) : End-to-End Speech Recognition in English and Mandarin
论文地址
百度的 DeepSpeech2 是语音识别业界非常知名的一个开源项目。
本博客主要对论文内容进行翻译,开源代码会单独再写一篇进行讲解。
这篇论文发表于2015年,作者人数非常多,来自于百度硅谷AI实验室语音技术组。
论文下载地址:https://arxiv.org/pdf/1512.02595.pdf (28页)
http://proceedings.mlr.press/v48/amodei16.pdf (10页,本文主要介绍10页的这个版本)
开源项目地址:https://github.com/PaddlePaddle/DeepSpeech
0. 摘要
端到端的技术的优势是,可以用深度神经网络替代传统的流水线式的手工方法,使得语音识别系统可以在噪音、口音、多语言等情况下通用。
摘要主要是讲 DeepSpeech2 采用了端到端的 ASR 技术,通过 HPC 技术等提高了训练速度,可以在几天内完成,因此可以快速迭代,从而发现更好的算法或架构。
DeepSpeech2 在一些任务上达到了 benchmark,可以与人工转录的结果相当。
此外,还可以在GPU上做批处理,从而可以较为容易地实现部署,可以服务大量用户,而且延时较低。
1. 介绍
端到端的语音识别技术,是使用一个深度神经网络去替换掉多个工程模块,比如 bootstrapping / alignment / clustering / HMM 等,而且也可以达到SOTA的效果。
对此,可以尝试很多深度学习的技术,需要获取更大的训练集,可以利用算力去训练更大的模型,而且要有条理地去调整网络结构。
这篇论文详细介绍了我们对于模型结构、标注数据集、计算规模方面做的工作。包括对于模型结构的广泛调研,以及获取比通常的语音识别系统更多训练数据的方法。
为了达到媲美人类水平的语音识别性能,我们在多个公开测试集上达到了benchmark。
最后,我们还在多个数据集的说话人数据间做了对比。我们发现我们最好的中文模型在转录简短的语音查询上,效果超过了一般的中文转录员。
本文其余部分:
第2节:对深度学习、端到端语音识别和可伸缩性的相关工作进行回顾,
第3节:介绍了模型对于体系结构和算法的改进,
第4节:介绍了如何高效地做计算,
第5节:讨论了训练数据和为进一步扩大训练集而采取的步骤,
第6节:展示了英语和普通话的测试结果。
第7节:介绍了如何将该语音识别系统部署到实际应用环境。
2. 相关工作(隐去了参考文献索引)
前馈神经网络FNN的声学模型早在二十多年前就提出了,当时RNN和CNN也被应用在了语音识别上。目前深度学习已经成为了语音识别SOTA论文的标配。
CNN在声学模型上效果很好,RNN也部署在了SOTA的模型中,并且和CNN在特征提取上效果很好。
端到端的语音识别是目前一个热门的研究方向,对于DMM-HMM和standalone的输出打分效果很显著。
结合注意力机制的RNN编码解码器在预测phonemes或graphemes时表现很好。
CTC损失函数与RNN对于时间信息建模,在按字符输出的端到端的语音识别系统上效果显著。
CTC-RNN模型在预测phonemes时表现也很好,虽然在这种情况下依然要使用语音词典(lexicon)。
到目前为止,计算规模依然是深度学习效果提升的关键。在GPU上训练可以提高性能,而当GPU数量增加时,性能也几乎会线性提升。
GPU效率的提高,对于低层网络基元有用。模型并行和数据并行可以用于创建一个高速的、可伸缩的系统,用于深度RNN网络训练语音识别。
数据也是成功的关键,有人用7000小时的标注数据进行了训练。数据增强在CV及ASR领域都非常有效。
现有的语音识别系统也可以引导新数据生成,比如可以用于对齐及过滤数千小时的语音图书。
我们受这些数据生成及增强的方法启发,以增加我们系统的有效标注数据量。
3. 模型结构
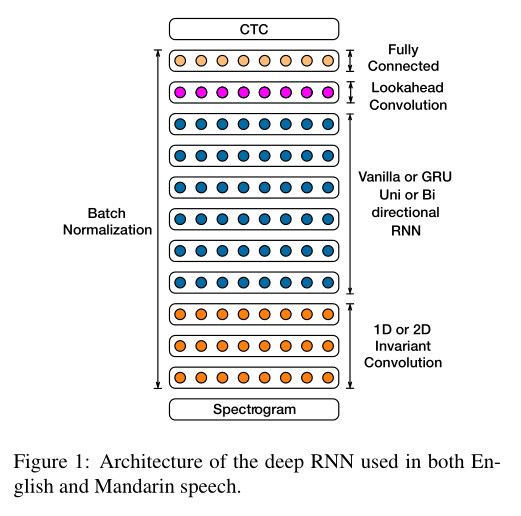
图1是我们的网络结构,其中列出了的可交换组件会在下文讨论。
我们系统的核心是,若干个CNN输入层加一个RNN,后接多个单向或双向的RNN层,及一个全连接层,一个softmax层。
我们用的是CTC损失函数,可以直接从输入语音预测字符序列。(对于双向RNN,使用ReLU,σ(x) = min{max{x,0}, 20} 作为激活函数)
网络的输入是一个指数归一化的语音片的对数频谱序列,窗口大小为20ms。输出是某种语言的一些字符。
在每个输出时间步,RNN做了预测\(p(l_t|x)\),其中\(l_t\)是字符表中的字符或者空白符。
在英语中,就是{a, b, c, ...,z,space, apostrophe, blank},我们在其中添加空格来划分单词边界。对于中文则是汉字。
在推断时,CTC模型与在大规模文本上训练得到的语言模型结合。我们使用专门的beam search来最大化 \(Q(y) = log(p_{RNN}(y|x)) + αlog(p_{LM}(y)) + β_{wc}(y)\)
其中\(wc(y)\)是转录文本中的字符数或者单词数。\(\alpha\)用于调整语言模型和CTC网络的权重。\(\beta\)允许比词表中更多的字。这些参数可以通过在开发集上用held out留出法来调。
3.1 深度RNN网络的batch normalization(批归一化)
为了在扩大训练集时有效地利用数据,我们通过添加RNN层增加了网络的深度。但是随着网络大小和深度的增加,使用梯度下降也变得比较困难。
已经证实可以使用批归一化来更快地训练深度网络。最近的研究表明,BatchNorm可以加快RNN训练的收敛速度,尽管并不是总能改善泛化误差。
相比之下,我们发现在大数据集上使用非常深的RNN网络时,除加速训练外,我们使用BatchNorm的变种还大大改善了最终的泛化误差。
RNN的公式:\(h_t^l = f(W^l h^{l-1}_t + U^l h^l_{t-1} + b)\)
其中,在时间步t的l层的激活值是通过将同一时间步t的前一层\(h^{l-1}_t\)的激活值与在当前层的前一个时间步t-1的\(h^l_{t-1}\)的激活值相结合来计算的。
有两种方式可以将BatchNorm应用到RNN操作中。
一种很自然的方式是在每次非线性操作前加上一个BatchNorm的转换\(B(.)\)。
\(h_t^l = f(B(W^l h^{l-1}_t + U^l h^l_{t-1}))\)
但这样的话,均值和方差在一个时间步的小批次上是累加的,这没有效果。
另外一种方法是按序列归一化(sequence-wise normalization),仅对垂直连接进行批量归一化。
\(h_t^l = f(B(W^l h^{l-1}_t) + U^l h^l_{t-1})\)
对于每个隐藏单元,我们计算整个序列中小批量中所有项的均值和方差。
图2显示了这种方法收敛地很快。

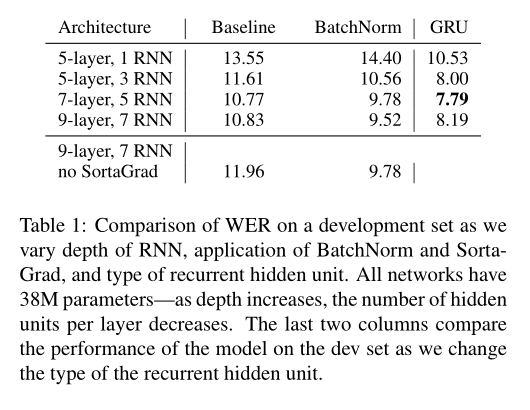
表1显示了按顺序归一化的性能改进随网络深度的增加而增加,最深层网络的性能差异为12%。我们存储训练期间收集的神经元的均值和方差的移动平均值,并将其用于评估阶段。
3.2 SortaGrad
即使使用批处理归一化,我们发现使用CTC进行训练有时还是不稳定的,尤其是在早期阶段。为了使训练更加稳定,我们尝试了一个训练机制,该机制可以训练地更快,有更好的泛化性能。
从头开始训练非常深的网络(或具有很多步的RNN)可能会在训练初期失败,因为输出和梯度必须经过许多未调好参数的网络层传播。
除了梯度爆炸外,CTC经常将接近零的概率赋值给非常长的转录文本,从而造成梯度消失。
对于这一现象,有一种叫SortaGrad学习策略:我们将语音的长度用来衡量复杂度,并首先训练较短(更容易)的语音。
具体来说,在第一轮训练中,我们按minibatch中最长语音的长度,从小到大遍历训练集中的批次。经过第一轮之后,重新回到随机顺序。
表1比较了在具有7个循环层的9层模型上有无SortaGrad的训练成本。
SortaGrad改善了训练的稳定性,并且在没有BatchNorm的网络中,这种效果尤其明显,因为这些网络的数值稳定性更低。
3.3 vanilla RNN和GRU的比较(vanilla就是simple的意思,朴素,简单)
目前我们使用的是简单的RNN模型,用了ReLU激活方法。不过一些更复杂的RNN变种,如LSTM,GRU在一些类似任务上也是效果很好。
我们用GRU来实验(因为在小数据集上,同样参数量的GRU和LSTM可以达到差不多的准确率,但GRU可以训练地更快且不易发散),
表1的最后两列显示,对于固定数量的参数,GRU体系结构可在所有网络深度上实现更低的WER。
3.4 时序卷积
时序卷积是语音识别中常用的一种方法,它可以有效地建模变长语音的时序平移不变性。
与大型全连接网络相比,时序卷积尝试更简洁地建模由于说话人引起的频谱变化。
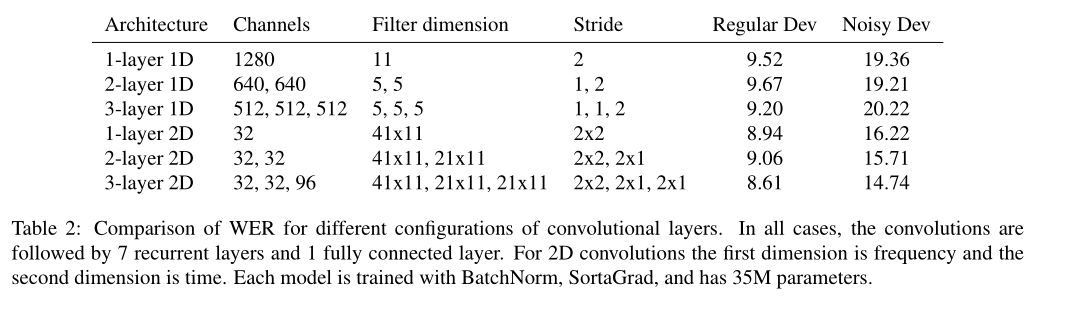
我们尝试添加一到三层卷积。这些都在时频域(2D)和仅时间域(1D)中。在所有情况下,我们都使用“相同”卷积。
在某些情况下,我们会跨两个维度指定步幅(下采样),从而减小输出的大小。
我们展示了两个数据集的结果:一个包括2048条语音的开发集(“ Regular Dev”)和一个噪声更大的2048条语音的数据集(“ Noisy Dev”),这些数据是从CHiME 2015开发集中随机采样的。
我们发现多层的一维卷积效果一般。2D卷积可显着改善嘈杂数据的结果,而对纯净数据却没有多少提升。从一层一维卷积到三层二维卷积的改变使噪声开发集上的WER提高了23.9%。
3.5 lookahead卷积和单向模型
双向RNN模型很难部署到实时、低延迟的环境中,因为当用户的声音到来时,它无法实现流式处理。
仅具有前向循环的模型通常比同类的双向模型性能差,这意味着一定数量的下文对于效果提升至关重要。
一种可能的解决方案是延迟系统产生预测结果的时间,直到它具有更多上下文为止,但我们发现很难在模型中实现这种行为。
为了构建一个没有损失精度的单向模型,我们开发了一种特殊的网络层,叫做lookahead convolution。如图3所示。
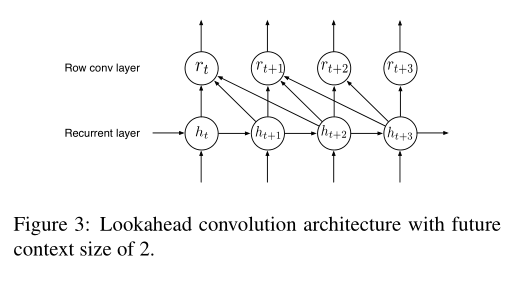
该层学习权重以线性组合每个神经元的激活时间步长\(\tau\),从而使我们能够控制所需的下文的量。
lookahead由参数矩阵\(W∈R^{(d,τ)}\)定义,其中d是上一层中的神经元数量。在时间步t对新层的激活\(r_t\)为:
\(r_{t,i} = \sum^{τ+1}_{j=1}W_{i,j}h_{t+j−1,i},\) for 1 ≤ i ≤ d.
我们将lookahead卷积放在所有循环层之上。这使我们能够以更精细的粒度在lookahead卷积以下做流式计算。
3.6 适配普通话
要将传统的语音识别流水线移植到另一种语言,通常需要大量新的基于语言的开发。
例如,人们经常需要手工设计一个声学模型。我们可能还需要明确建模基于语言的发音特征,例如普通话的音调。
由于我们的端到端系统直接预测字符,因此不再需要这些费时的工作。这使我们只需要稍微调整,就能够使用上述方法快速创建端到端的普通话语音识别系统(输出汉字)。
我们对网络所做的唯一结构更改来自于字符集。该网络输出大约6000个字符的概率,其中包括罗马字母,因为中英文混合转录很常见。
如果有字符不在表里,则会产生OOV的错误。不过这不要紧,因为我们的测试集仅有0.74%的字符是OOV的。
我们在普通话中使用字符级语言模型,因为通常文本没有做分词。
在第6.2节中,我们证明了我们的普通话语音模型在架构变化方面的改进与英文语音模型大致相同,这表明来自一种语言的建模知识可以很好地迁移给其他语言。
4. 系统优化
我们的网络具有数以千万计的参数,而一次训练实验需要几十的单精度exaFLOPs。(exa:艾,10^18, 百亿亿)
由于我们评估数据和模型假设的能力取决于训练速度,因此我们基于高性能计算(HPC)架构创建了高度优化的训练系统(集群的每个节点有8张NVIDIA Titan X,理论峰值可提供48单精度TFLOP/s)。
尽管存在许多用于在并行计算机上训练深度网络的框架,但我们发现,我们良好的扩展能力通常会被未优化的例程所困扰。因此,我们专注于精心优化用于训练的最重要例程。
具体来说,我们为OpenMPI创建了自定义的All-Reduce代码,以求和多个节点上各个GPU上的梯度,开发了针对GPU的CTC的快速实现,并使用了自定义内存分配器。
综合起来,这些技术使我们能够在每个节点上维持理论峰值性能的45%。
我们的训练使用同步SGD,将数据分配到多个GPU上并行计算,其中每个GPU复制一份模型到本地来处理当前的小批量,然后与其他所有的GPU交换计算出的梯度。
我们更喜欢同步SGD,因为它具有可重现性,这有助于发现和修复回归。但在此模式下,GPU必须在每次迭代时快速通信(使用“all-reduce”操作),以避免浪费计算周期。
以前论文的工作已经在使用异步更新来缓解此问题。相反,我们专注于优化全减少操作本身,使用减少特定工作负载的CPU-GPU通信的技术实现了4到21倍的加速。
同样,为了增强整体计算能力,我们使用了来自Nervana Systems和NVIDIA的高度优化的内核,这些内核针对我们的深度学习应用进行了调整。
我们同样发现,自定义内存分配例程对于最大程度地提高性能至关重要,因为它们减少了GPU和CPU之间的同步次数。
我们还发现,CTC成本计算占运行时间的很大一部分。由于没有开源的针对CTC进行优化的代码,因此我们开发了一种快速的GPU实施方案,将总体训练时间减少了10-20%。(后期会开源)
5. 训练数据
大型深度学习系统需要大量的带标签的训练数据。
为了训练我们的英语模型,我们使用11940个小时的标记语音,包含800万条语音,而普通话模型,使用了9400个小时的标记语音,包含1100万条。
5.1 数据集构建
英文和普通话数据集的一部分,是从原始数据中获取的长音频片段,这些片段的转录带有噪音。为了将音频分割成几个长片段,我们将语音与转录对齐。
对于给定的音频-转录对(x, y),计算最可能的alignment:
\(l^*=argmax_{l∈Align(x,y)}\prod^T_tp_{ctc}(l_t|x;\theta)\)
这是用CTC训练的RNN模型找到的Viterbi alignment。
由于CTC损失函数计算了所有的alignment,因此这并不能确定一个正确的alignment。然而我们发现当使用双向RNN时,是可以产生正确的alignment的。
为了过滤出转录不佳的片段,我们构建了一个具有以下特征的简单分类器:
CTC cost,音频序列长度归一化的CTC成本,转录文本长度归一化的CTC成本,序列长度与转录长度之比,转录文本中的单词数和字符数。
为了构建这个数据集,我们使用了大量的标签。
对于英语数据集,我们发现filter将WER从17%降低到5%,同时保留了超过50%的样本。
此外,我们通过给每个epoch添加SNR在0dB到30dB之间的独立噪声,来动态扩展数据集。
5.2 数据缩放
我们在表3中显示了增加标注训练数据量在WER上的效果。
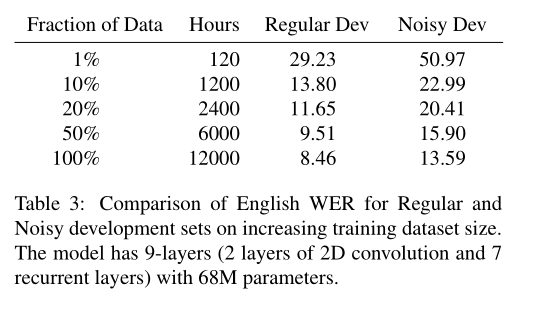
这是通过在训练之前对整个数据集进行随机抽样来完成的。
对于每个数据集,模型进行多达20轮epoch的训练,并根据在开发集留出部分(验证集)上的错误率使用早停机制,以防止过拟合。
训练集大小每增加10倍,WER就会降低约40%。
我们还发现,常规数据集和嘈杂数据集之间的WER相对差距(相对值约为60%),这意味着数据量的增多对这两种情况都有用。
6. 结果
为了更好地评估我们的语音系统在现实场景中的适用性,我们在各种测试集上进行了评估。我们使用了几个公开可用的基准以及内部收集的几个测试集。
所有模型都在第5节中所述的完整的英语数据集或完整的普通话数据集上训练了20个epoch。
我们对于每个有512条声音的小批量使用了具有Nesterov动量的随机梯度下降法。如果梯度的范数超过阈值400,则会将其重新缩放为400。
我们选择在训练阶段在验证集上表现最好的模型进行评估。
在[\(1×10^{-4}\), 6×\(10^{-4}\)]范围里选择学习率,以达到最快的收敛速度,并在每个epoch之后以常数因子1.2进行退火。我们对所有模型都使用0.99的动量。
6.1 英语
最好的英语模型有2层2D卷积,然后是3层单向递归层,每个层有2560个GRU单元,然后是由BatchNorm和SortaGrad训练的τ= 80的超前卷积层。
我们并不能使模型满足测试集中的所有语音条件。语言模型解码参数在留出的开发集中设置一次。
我们提供我们语音识别系统在多个测试集上的结果以及对人工转录的准确率的估计。
我们通过让Amazon Mechanical Turk的工作人员手动转录所有测试集,以此来评估人工转录的准确率。
众包工作者不如专门训练有素的转录员那么准确。
之前有工作通过:根据错误率对转录员进行额外奖励,对于打字及拼写自动纠错,以及让转录委员会审核,在WSJ-Eval92集上达到了接近1%的人工转录WER。
我们采用以下没有奖励及自动纠错的机制,对标竞品“ASR绿野仙踪”。
每个音频由两名随机的工作人员转录,每个转录音频平均约5秒。然后,我们将两次转录中较好的一个用于最终WER计算。
大多数工作人员都位于美国,被允许多次收听音频,平均每次转录花费27秒。
人工转录的结果与现有的ground truth进行比较,以产生WER估计值。
尽管现有的ground truth转录也有一些标签错误,但在大多数数据集上它都小于1%。
6.1.1 benchmark结果
具有高信噪比的阅读语音可以说是大词汇量连续语音识别中最简单的任务。
我们以《华尔街日报》(WSJ)阅读新闻文章的语料库和由有声读物构建的LibriSpeech语料库两个测试集为基准对我们的系统进行了测试。
表4显示,在4个测试集中,有3个测试系统的性能优于人工众包。
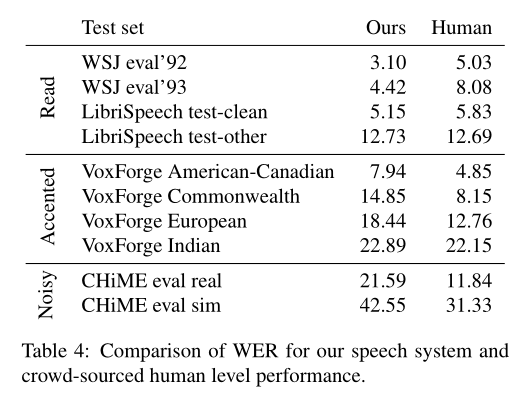
我们还使用VoxForge(http://www.voxforge.org)数据集测试了系统对常见口音的鲁棒性。该测试集包含多个不同口音的人的朗读语音。
我们将这些口音分为四类:美国-加拿大口音,印度口音,英联邦(英国、爱尔兰、南非、澳大利亚、新西兰)口音和欧洲(英语不是第一语言的国家)口音。
我们从VoxForge数据中构造了一个测试集,其中每种口音有1024个样本,总共4096个样本。我们的系统只在印度口音上超过了人工结果。
最后,我们使用来自最近结束的第3次CHiME竞赛的测试集对我们在嘈杂语音上的表现进行了测试。
该数据集使用WSJ测试集的语音数据,在实际嘈杂环境中收集,而且带有人为添加的噪声。
使用CHiME音频的全部6个声道可以显着提高性能。由于尚未普及使用多声道音频,因此我们对所有模型都使用一个声道。
相比给清晰的语音添加噪音,在来自真实嘈杂环境的数据上,我们的语音识别系统与人类水平的差距更大。
6.2 普通话
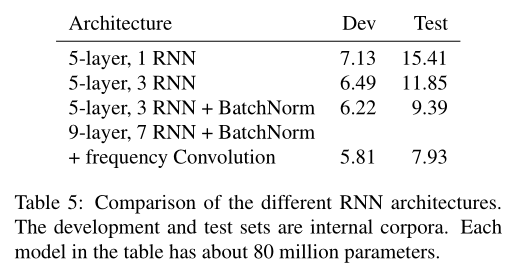
在表5中,我们比较了几种,在2000条语音的开发集和1882条嘈杂语音样本的测试集上,对普通话进行训练的网络结构。
此开发集还用于调整解码参数。我们看到,具有2D卷积和BatchNorm的最深的模型相对于浅层RNN的性能要高48%。
对于表6的两个数据集,我们最好的普通话语音识别系统相比于人工转录可以更好地转录简短的语音查询。

7. 模型部署
双向模型不是为实时转录而设计的:由于RNN具有多个双向层,因此转录语音要求将整个语音输入给RNN。
而且由于我们使用beam search进行解码,因此beam search成本会很高。
为了增加部署的可扩展性,同时仍提供低延迟的转录,我们构建了一个名为Batch Dispatch的批处理调度程序。
该批处理调度程序将来自用户请求的数据流组合成批进行处理,然后对这些批处理执行RNN前向传播。
使用此调度程序,我们可以在增加批处理大小从而提高效率,和增加延迟之间进行取舍。
我们使用一个贪心的批处理方案,该方案会在上一个批处理完成后立即进行下一个批处理,而不管此时准备完成多少工作。
该调度算法平衡了效率和延时,达到了相对较小的动态批次大小(每批次至多10个样本),服务器负载与批次大小的中位数线性相关。
我们在表7中看到,当系统加载10个并发流时,系统的中位数延迟为44ms,98百分位的延迟为70ms。该服务器使用一个NVIDIA Quadro K1200 GPU对RNN进行评估。
按此设计,随着服务器负载能力的提高,批处理调度程序将以更大的批进行数据处理,而延迟依然保持在很低的水平。
我们的部署系统使用半精度计算评估RNN,这对精度没有影响,但可以显着提高效率。
我们为此任务编写了自己的16位矩阵乘法例程,从而大大提高了相对较小批次的吞吐量。
使用beam search需要在n-gram语言模型中进行重复查找,其中大部分都是直接从内存而非缓存读取的。
为了降低这些查找的成本,我们采用启发式方法:仅考虑累积概率至少为p的少量字符。
在实践中,我们发现p = 0.99效果很好,此外,我们将搜索限制为40个字符。
这样的话,总体的普通话语言模型查找时间快了150倍,并且对CER的影响可以忽略不计(相对值0.1-0.3%)。
7.1 生产环境下的深度学习语音技术
深度学习的语音方法已经集成到面向用户的SOTA的语音产品线中。
我们发现了一些关键点,这些关键点会影响我们端到端的深度学习模型的部署。
首先,即使使用了大量的通用语音数据用于训练,少量基于应用场景的训练数据也是非常宝贵的。
例如,虽然我们使用超过10,000小时的普通话语音用于训练,但是仅有500小时的基于特定应用的数据也可以显着提高实际应用的性能。
同样,基于应用的语言模型对于达到高准确率也很重要,并且我们在DeepSpeech系统中使用了强大的预训练n-gram模型。
最后,由于我们的系统是从大量带标签的训练数据中训练出来的,是直接输出字符的,而具体的应用场景会有转录的特殊要求,这些需要做后处理(例如数字格式规范化)。
因此,尽管我们的模型消除了许多复杂性,但端到端的深度学习方法仍有待进一步研究,尤其是对于其适应性及基于应用场景的研究。
8. 总结
随着数据及算力的持续增加,对于语音识别系统的提高,端到端的深度学习展现出了令人惊喜的效果。由于该方法有高度的通用性,我们可以将其应用到新的语言上。
我们构建英文及普通话这两个性能优良的语音识别系统并没有借助任何语言方面的专家知识。最后,我们还说明了如何将其部署到GPU上供很多用户请求,为用户使用端到端的深度学习技术铺平了道路。
为了达到这一目标,我们尝试了很多网络结构,发现了很多有用的技术:使用Sorta Grad、批归一化、单向模型的超前卷积来增强数值优化。
这些尝试是在一个经过优化的、高性能计算系统上实现的,该系统使我们能够在短短几天之内对大型数据集进行全量的训练。
综上所述,我们的结果证明了端到端的深度学习技术在对于多种场景下的价值。我们相信这些技术会得到更广泛的应用。

