


【笔记】DLHLP - 李宏毅 - 5 - 语音识别 - Part 4 HMM
Hidden Markov Model (HMM)
以前语音识别用的是统计模型,而现在,深度学习的方法有很多思想也还是借鉴的HMM。
X是输入语音序列,Y是输出文字,我们的目标是穷举所有可能的Y,找到一个\(Y*\)使得\(P(Y|X)\)最大化。这个过程叫作解码。
根据贝叶斯定律,我们可以把它变成\(\frac{P(X|Y)P(Y)}{P(X)}\)。
由于P(X)与我们的解码任务是无关的,因为不会随着Y变化而变化,所以我们只需要算argmaxP(X|Y)P(Y)。
前面这项P(X|Y)是Acoustic Model,HMM可以建模,后面那项P(Y)是Language Model,有很多种建模方式。

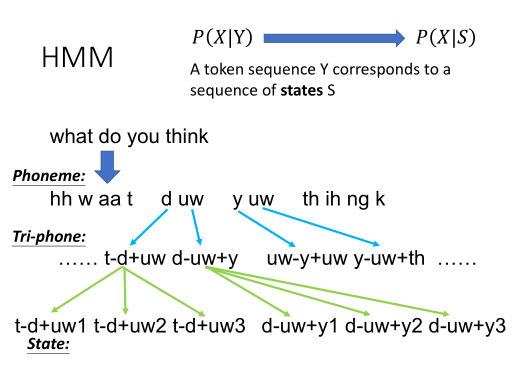
音标、字或词,这些单位,对HMM的隐变量来说,都太大了。所以我们需要为P(X|Y)建模,变成为P(X|S)建模。S为状态,是人定义的。它是比音素Phoneme还要小的单位。
序列中的每一个音素,都会受到前后音素单位的影响。我们会用一个Tri-phone,把当前的每一个音素,都加上它前后的音素,相当于把原来的音素切得更细。
这样d后面的uw,和y后面的uw表达出来就会是不同的单位了。
假设我们有一段声音信号X,它内容包含了一系列特征向量。我们会先从Start状态转移到第一个状态,发射出一些向量,再到第二个状态,发射出一些向量……以此类推,直至走到END状态。
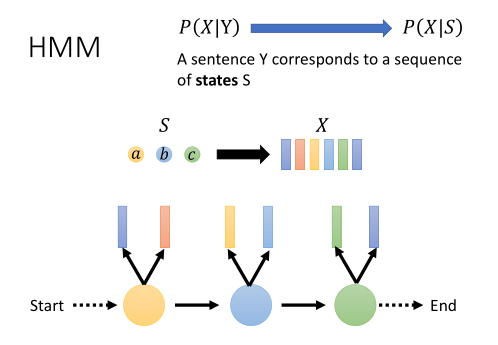
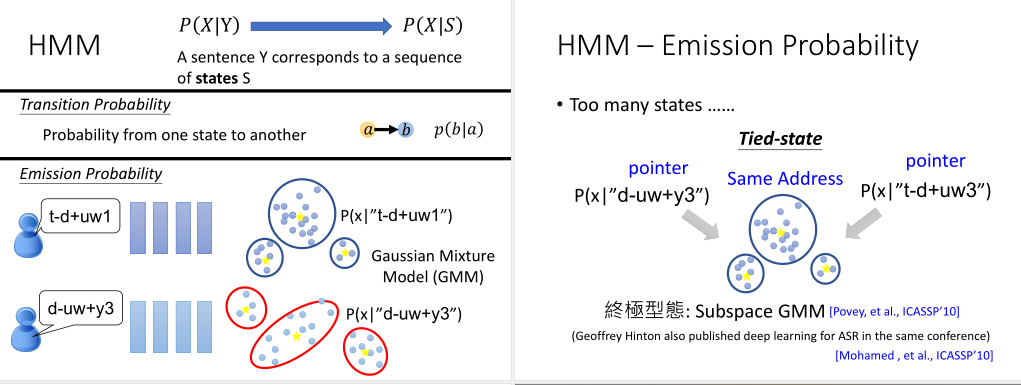
一个状态有两种概率,一种是转移概率,如P(b|a),即当前状态转移到其它状态或不转移状态的概率,
另一种是发射概率,如P(x|"t-d+uw1"),即该状态发射出某个样子的声学特征向量的概率。
假设每一个状态,它产生出来的声学特征向量有一个固定的分布。我们可以用高斯混合模型GMM来表示这个概率。
这便是为什么我们要用比Phoneme还要小的单位来表示状态。因为我们要假设每个状态发射出来的分布稳定。
为什么我们不用字符单位来当作状态呢?比如,c这个字母它的发音不是固定的,它在很多时候是发"ke",但它在h后面就发音"ch"。这样就不适合拿来当作HMM的状态。
不过,很多的State在训练中只出现一两次,根本就估计不准它的高斯混合分布。所以过去有个关键性的技术叫作Tied-state。
它假设某些State的发音就是一样的,所以可以共用同样的高斯混合分布,来减少使用的高斯混合模型的数量。这就好比你有两个命名不一样的指针,都指向了同样的内存。
这个方法在经过很多年很多年的研究之后,就产生了一个终极形态Subspace GMM。所有的State都共用同一个高斯混合模型。
它有一个池子,里面有很多高斯分布。每一个State,就好比是一个网子,它去这个池子中捞几个高斯分布出来,当作自己要发射的高斯混合分布。
所以每个State既有不同的高斯分布,又有相同的高斯分布。
(这篇是来自ICASSP 2010年的论文。有趣的是,Hinton在同年也在该论坛上发表了一篇关于深度学习的ASR的论文。但当时大家的注意力都在前一篇论文上,Hinton的研究并没有受到很多重视。原因在,它的表现当时不如SOTA。)
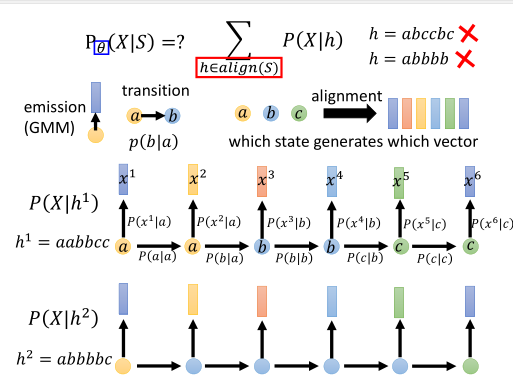
假设我们已经用给定好的数据算好了发射概率和转移概率,但我们还是算不出P(X|S)的概率。这关键技术在Alignment。
我们需要知道哪一个声学特征,是由哪一个状态产生的,才有办法用发射概率和转移概率去计算P(X|S)。
给定的候选对齐状态不同,算出来产生的声学特征的概率也就会不一样。我们就需要穷举所有可能,找到它产生与观测X的声学特征概率最大,最一致的对齐方式。
在HMM中如何使用深度学习
方法1:Tandem(串联)
之前的声学特征是MFCC格式,深度学习方法输入一个MFCC,预测它属于哪个状态的概率。
接着我们把HMM的输入,原为声学特征,由深度学习的输出取代掉。我们也可以取最后一个隐层或者是瓶颈层(bottleneck)。
方法2:DNN-HMM Hybrid(混合模型)
HMM中有一个高斯混合模型。我们想把它用DNN取代掉。
高斯混合模型是给定一个状态,预测声学特征向量的分布,即P(x|a)。
而DNN是训练一个State的分类器,计算给定一个声学特征下,它是某个状态的概率,即P(a|x)。
用贝叶斯定律,可以得到\(P(x|a) = \frac{P(a|x)P(x)}{P(a)}\)。
P(a)可以通过在训练资料中统计得到。P(x)可以忽略。
有人会觉得这个混合模型的厉害之处在把生成模型HMM中加入了判别模型。这个很早就有人做了,没什么稀奇。
也有人觉得他厉害之处在于用有更多参数的深度神经网络替换了GMM。但这小看了参数量大起来时GMM的表征能力。
实际上,这篇论文的贡献在,它让所有的给定观测,计算当前可能状态概率,都共用了一个模型。而不是像GMM那样,有很多不同的模型。
所以它是一个非常厉害的状态标注的方法。DNN可以是任何神经网络,比如CNN或者LSTM。

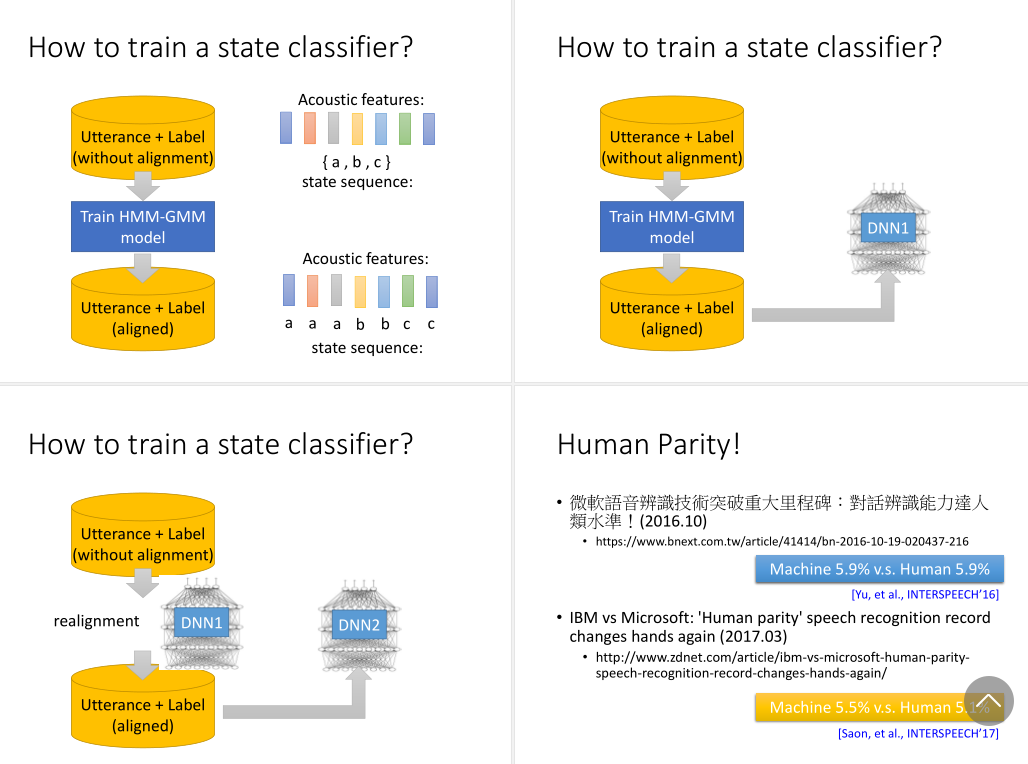
我们要如何训练一个状态分类器呢?
它的输入是一个声学特征,输出是它是某个状态的概率。
我们训练这个之前,需要知道每个声学特征和状态之间的对应关系。但实际中的标注数据都是没对齐的。
过去的做法是训练一个HMM-GMM,那这个粗糙的模型去做找出一个概率最大的对齐。然后再根据声学特征与状态之间的对齐数据,去训练状态分类器。
接着,我们再拿这个训练好的状态分类器,替换掉原来的HMM-GMM,再对数据对齐,来训练出一个更好的状态分类器。
我们反复重复这个过程。用训练得到的DNN去对数据做对齐,再用对齐的数据去训练一个新的DNN。
这个方法很强。微软在2016年的时候,让语音识别超过了人类水平。实际生产中,因为要考虑到推断速度,端对端的深度学习模型并不多,除了谷歌的手机助理。大部分都是混合模型。
语音识别的公认错误率指标大概在5%左右,就已经很强了。专业听写人员就在这个水平。
模型能达到5%算是极限了,因为正确答案也是人标注的,也存在5%左右的错误率。再往上提升,学到的只可能是错误信息。
在微软的文献中,他们训练了一个49层的残差神经网络。输出有9000个状态类别,输出是一个向量,用的是Softmax作归一化。


