
【笔记】DLHLP - 李宏毅 - 3 - 语音识别 - Part 2 LAS
语音识别模型:
语音识别模型主要分为两种,一种是基于seq2seq的,一种是基于HMM的。
seq2seq的模型主要有LAS,CTC,RNN-T,Neural Transducer,MoChA。
本节讲最流行的LAS,就是Listen,Atten,and Spell,典型的seq2seq+attention的自编码模型。
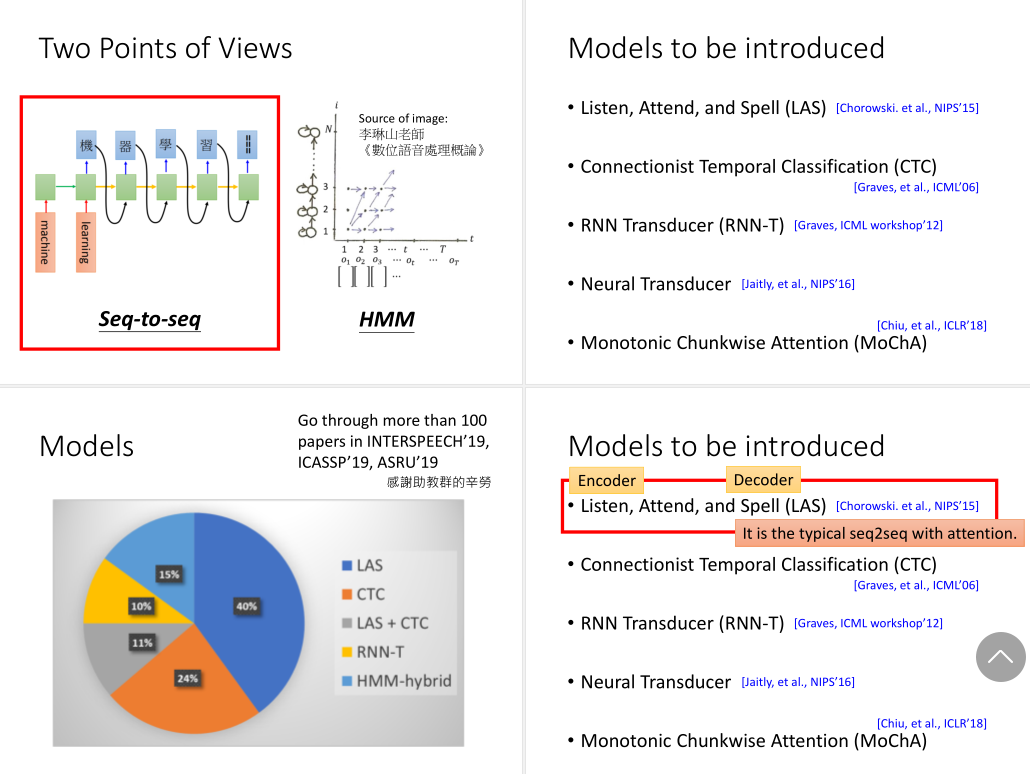
1. Listen:
编码器会把输入的一串声学特征,转换为高维隐层嵌入。它的主要目标是提取出内容信息,过滤掉说话者的嗓音变化和环境噪音。
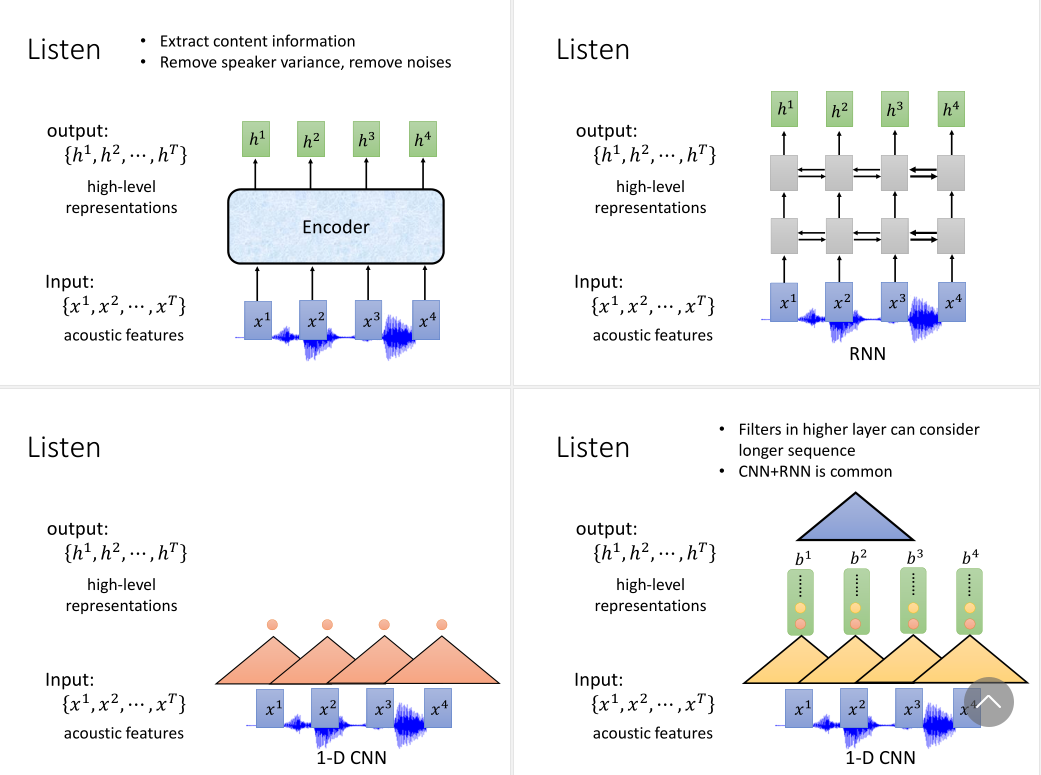
编码器我们可以用CNN和RNN,也可以是CNN+RNN,也可以用self-attention。
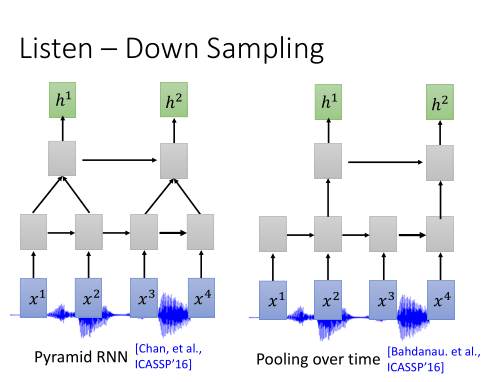
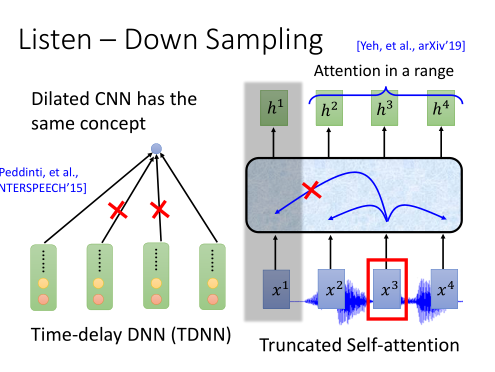
Down Sampling:
因为一段声音讯号太长了,而且相邻向量间,带有重复的信息。为了节省计算量 ,我们可以用:
1)Pyramid RNN: 在每一层的RNN输出后,都做一个聚合操作。把两个向量加起来,变成一个向量。
2)Pooling Over time: 两个time step的向量,只选其中一个,输入到下一层。
3)Time-delay DNN: 是CNN常用的一个变形。通常CNN是计算一个窗口内每个元素的加权之和,而TDDNN则只计算第一个和最后一个元素。
4)Truncated self-attention: 是自注意力的一个变形。通常自注意力会对一个序列中每个元素都去注意,而Truncated的做法是只让当前元素去注意一个窗口内的元素。
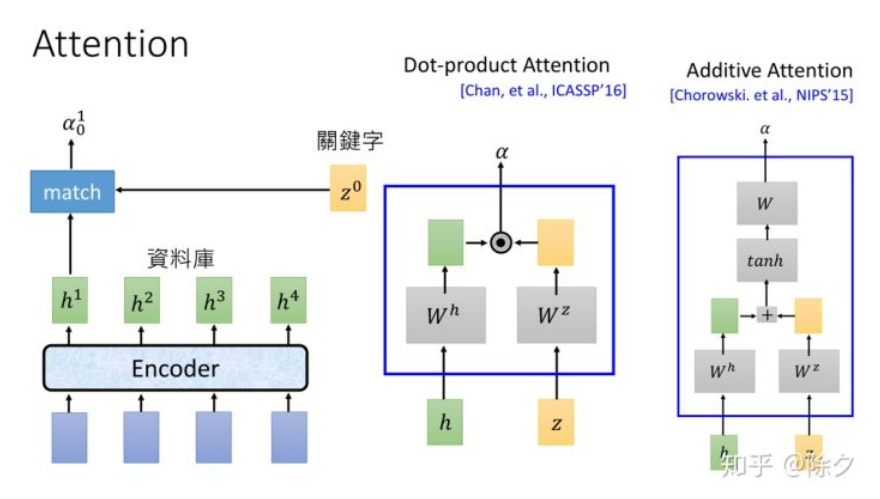
2. Attention:
在编码器和解码器中间的Attention层中,有个\(z^0\)的参数是query,而Encoder输出的隐层嵌入的每个位置的向量\(h^i\)都是key,注意力的计算方式就是这两者经过线性变换后的点积。
如果采用的是Additive Attention,则是这两个向量线性变换后相加再通过tanh,再经一次线性变换后得到注意力分数。
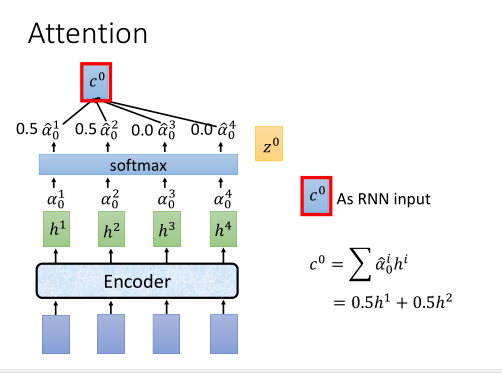
每个位置的注意力分数经过softmax,对\(h^i\)加权求和,就可以得到一个归一化的分布\(c^0\)。
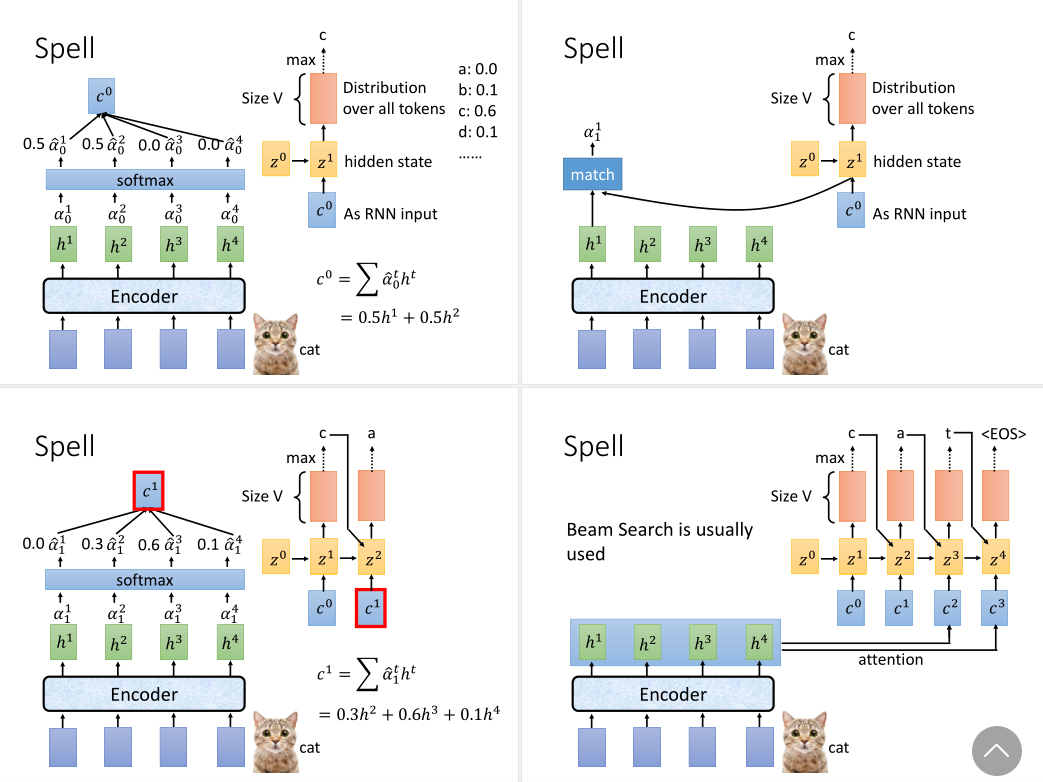
3. Spell:
这个归一化的分布向量和之前的\(z^0\)会作为解码器RNN的输入,输出是隐层\(z^1\),和一个对词表V中所有可能词预测的概率分布向量。我们取max就可以解码得到最可能的第一个token。
再拿\(z^1\)与原编码器的隐层向量做注意力,得到一个新的注意力分布\(z^2\)。它与\(c^1\)一同输入给RNN,同样的方式就能解码得到第二个token。
以此类推,直到解码得到的token是一个终止符
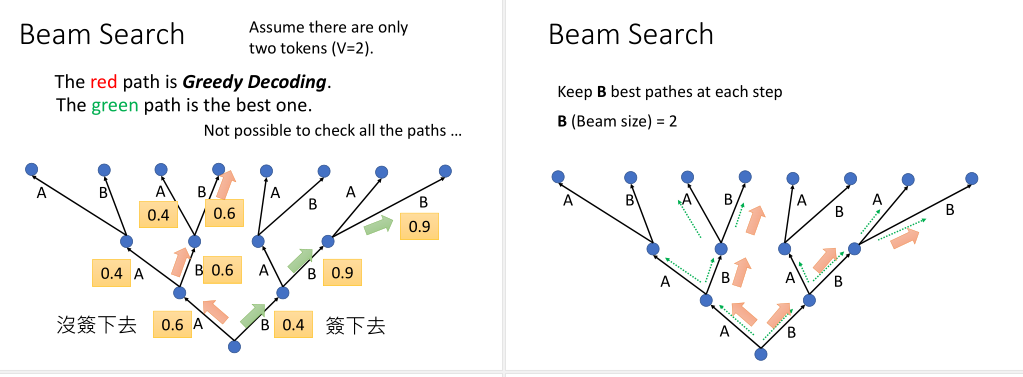
Beam Search:
如果我们每次都选择最大概率的方向,贪心策略并不能保证生成整个序列的概率是最优的。而且在实际中,词表通常很大,没有办法去搜索穷尽所有的可能路径。
解决这个问题的一种策略就是使用Beam Search,它是窗口大小为K的贪心搜索。从每个节点我们都保留K个最好的路径,一直往下。
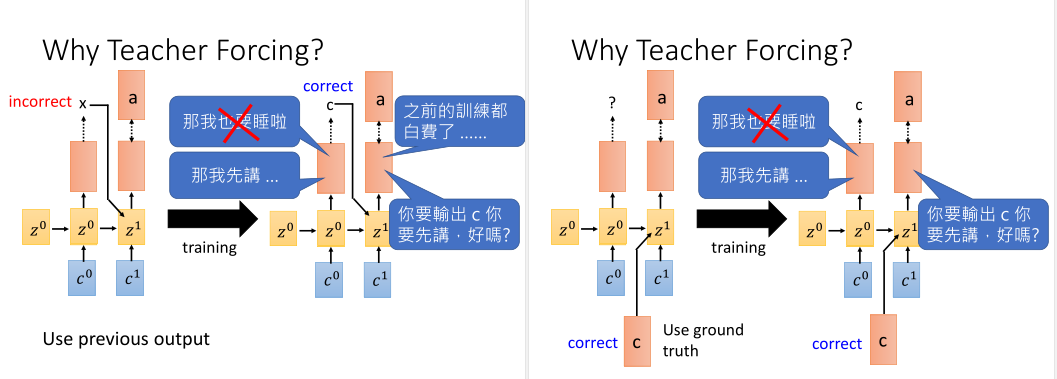
Teacher Forcing:
训练时,我们的标签是序列长度为N的one-hot向量。它会与解码器RNN第一步输出的大小为词表V的概率分布计算交叉熵损失。
在进行下一步RNN解码时,上一步的正确标签c会替代最大概率的\(c^0\)进行解码。这个技术叫作Teacher Forcing。

为什么要这么做?因为最开始的时候模型是从随机开始训练的,解码器的表现很差,输出的东西是乱的,会影响后续解码步骤的效果。
也就是说,前面解码的结果会影响后面,如果前面的结果很长时间都不正确,这会导致后面的解码步骤很难学到真正正确的信息。
所以最好的方式就是不要理睬RNN的输出,用正确标签去指导它去做下一步的预测。
两种注意力:
之前的注意力阶段,我们每次是用解码器的输出隐层去与编码器的输出做注意力。
除此以外,还有另一种做注意力的方式。
我们把解码器的隐层\(z^t\)拿出来与\(h^i\)做注意力得到\(c^t\)。这个\(c^t\)不是保留到下一个时间才使用,而是在当前时间点立刻使用。我们把\(z^t\)和\(c^t\)丢给解码器RNN,得到新分布\(z^{t+1}\)。
这两种注意力的区别在,注意力得到的结果是下一个时间使用还是当前时间使用。第一篇拿Seq2Seq做语音识别的论文,用的是二者的合体版本。

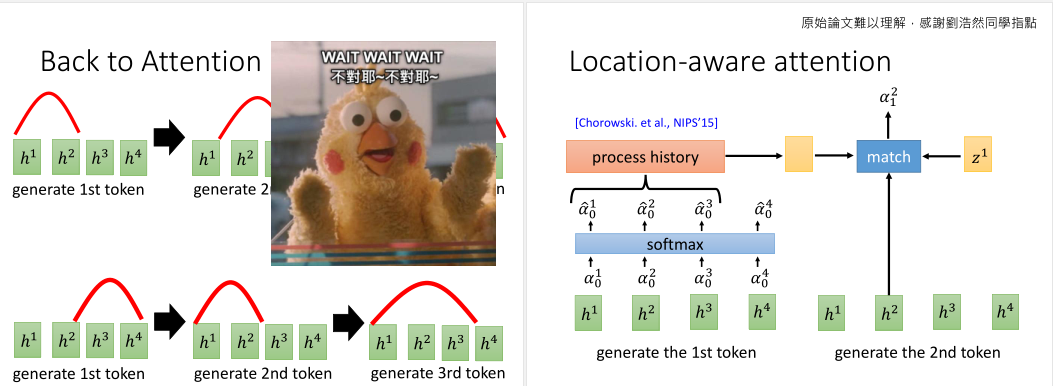
语音识别是否非要用注意力不可呢?
注意力最早是用在Seq2Seq翻译上解决源语言与目标语言的对齐问题。
这个弹性很大的注意力,在语音上用会有种杀鸡焉用牛刀的赶脚。因为语音上,每次注意跳跃是有限的。而不会出现像机器翻译那样,开头注意到结尾的的大跳跃情况。
我们可以用Location-aware attention来优化。我们的注意力不能够随便乱跳,而是要考虑前一个时间步得到的注意力权重影响。
我们把t之前的注意力权重\(α^0\)到\(α^{t-1}\)的向量,做一个线性映射后再输入给解码RNN。这样模型就能学到,每解码出一个token,注意力就要往右移动一点。
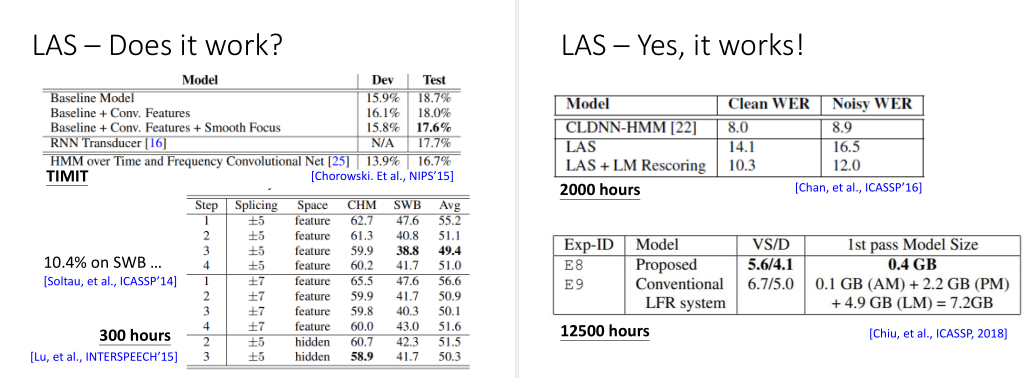
LAS模型需要在海量数据集上训练,和一些调参技巧,与传统方法相比才会有显著提升。但LAS有另一个好处是,它的模型参数可以比传统方法变得很小。
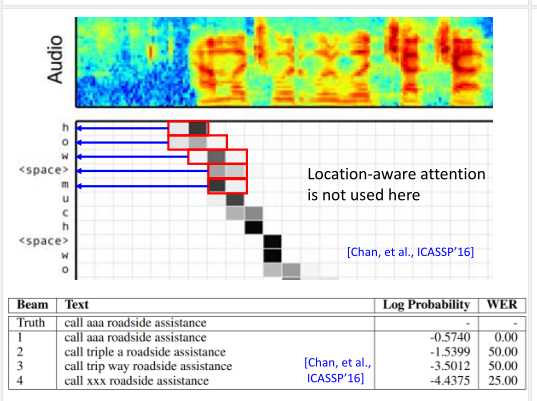
LAS的注意力可视化出来发现,即便没有用Location-aware attention,模型也可以自己学到这样的注意规律。
还有一个有趣的发现,模型能够自动识别出aaa和triple a是对应一样的声音讯号。这可以解释为,二者的上下文经常一样。 LAS可以学到复杂的输入讯号和输出讯号的关系。
LAS模型也可以用语言模型LM来提升。不过LAS本身很强,在给足训练集的情况下,不用LM来优化也是能表现很好的。
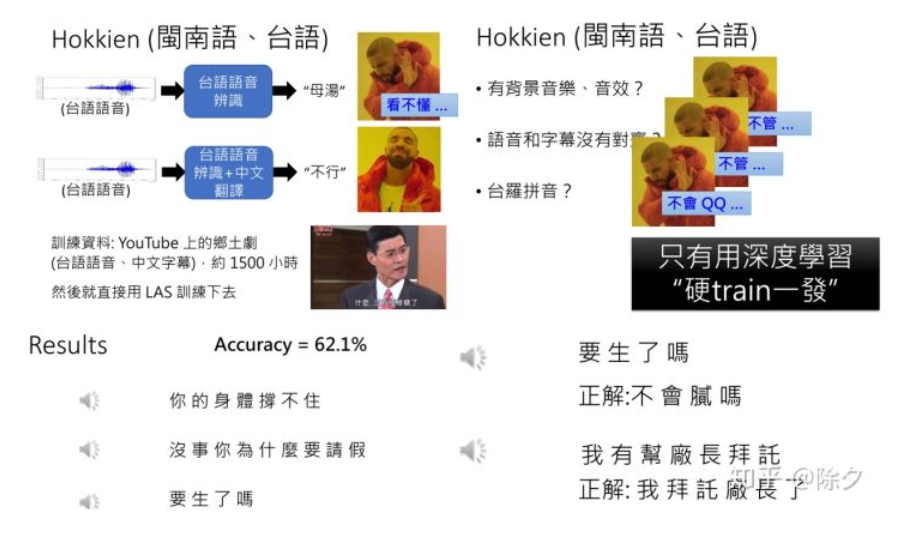
我们还可以用LAS模型来训练把闽南话语音翻译成中文字幕,或者是很多电影里面自动把英语语音翻译成中文字幕。
即便背景音存在音乐和音效,语音和字幕有时没有对齐,我们都可以无需去管。直接海量数据,深度学习模型硬train一发,以上问题统统都能自动解决。
LAS的局限:
LAS虽然神通广大,但它也有一些问题。我们期待我们的模型可以做online的识别,即能够一边听,一边做语音识别。而不是模型听完整句话后,等上一秒,模型才输出辨识结果。
之后要讲的模型,就是解决LAS的这个问题。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号