

【笔记】PyTorch框架学习 -- 1. 张量创建及操作,线性回归的实现
目录:
1. PyTorch简介
2. 张量的概念及创建
2.1 直接创建Tensor
2.2 依据数值创建Tensor
2.3 依据概率分布创建Tensor
3. 张量的操作
3.1 张量的拼接和切分
3.2 张量索引
3.3 张量变换
4. 实现线性回归
1. PyTorch简介
2017年,FAIR(Facebook AI Research)发布PyTorch,是在Torch框架基础上打造的,(Torch使用Lua语言,受众小未普及)。
英文文档:https://pytorch.org/docs/stable/index.html
中文文档:https://pytorch-cn.readthedocs.io/zh/latest/
本地安装: python, Anaconda, PyCharm, CUDA, cuDNN, torch, torchvision,
安装指南:https://www.cnblogs.com/yanqiang/p/12749030.html
2. 张量的概念及创建
张量就是一个多维数组,是标量(0维)、向量(1维)、矩阵(2维)的拓展。
Variable: 是torch.autograd中的数据类型。有data(被封装的Tensor),grad(data的梯度),grad_fn(创建Tensor的Function),requires_grad(是否需要梯度),is_leaf(是否为叶子节点)几个属性。
PyTorch 0.4.0 之后,Variable并入Tensor,还包括有dtype(张量的数据类型,如torch.FloatTensor,torch.cuda.FloatTensor),shape(张量形状),device(张量所在设备,cpu/gpu)。
2.1 直接创建Tensor
torch.tensor 功能:从data创建tensor
import torch
import numpy as np
torch.manual_seed(1)
# torch.tensor(data, # 数据,可以是list, numpy
# dtype=None, # 数据类型,与data一致
# device=None, # 所在设备,cuda/cpu
# requires_grad=False, # 是否需要梯度
# pin_memory=False) # 是否需要锁页内存
arr = np.ones((3, 3))
print("ndarray的数据类型:", arr.dtype) # float64
t = torch.tensor(arr, device='cuda')
print(t)
# tensor([[1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.]], device='cuda:0', dtype=torch.float64)
t = torch.tensor(arr)
print(t)
# tensor([[1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.]], dtype=torch.float64)
除了这种方式,还有一种是torch.from_numpy(ndarray)方法,从numpy创建tensor,区别在于:这种方式创建的tensor是和原ndarry共享内存的,当其中一个改变,另一个也会改变
# 测试代码
arr = np.array([[1, 2, 3], [4, 5, 6]])
t = torch.from_numpy(arr)
print("numpy array: ", arr)
print("tensor : ", t)
print("修改tensor")
t[0, 0] = -1
print("numpy array: ", arr)
print("tensor : ", t)
2.2 依据数值创建Tensor
torch.zeros 创建全0张量
torch.zeros_like() 依据input创建全0张量
# 1.
# torch.zeros(*size, # 张量的形状
# out=None, # 输出的张量
# dtype=None,
# layout=torch.strided, # 内存中布局形式,有strided, sparse_coo等
# device=None,
# requires_grad=False)
out_t = torch.tensor([1])
t = torch.zeros((3, 3), out=out_t)
print(t, '\n', out_t)
# tensor([[0, 0, 0],
# [0, 0, 0],
# [0, 0, 0]])
print(id(t), id(out_t), id(t) == id(out_t)) # True 同一个数据,仅命名不同
# 2.
# torch.zeros_like(input, # 创建与input形状相同的全0张量
# dtype=None,
# layout=torch.strided,
# device=None,
# requires_grad=False)
torch.ones(), torch.ones_like()类似
torch.full(), torch.full_like()
# torch.full(size, # 张量的形状
# fill_value, # 张量的值
# out=None,
# dtype=None,
# layout=torch.strided,
# device=None,
# requires_grad=False)
t = torch.full((3, 3), 1)
print(t)
# tensor([[1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.]])
torch.arange()
# torch.arange(start=0, # 数值区间 [start, end)
# end,
# step=1, # 数列公差
# out=None,
# dtype=None,
# layout=torch.strided,
# device=None,
# requires_grad=False)
t = torch.arange(2, 10, 2)
print(t) # tensor([2, 4, 6, 8])
torch.linspace() 创建均分的一维张量
# torch.linespace(start, # 数值区间 [start, end],闭区间
# end,
# step=100, # 数列长度
# out=None,
# dtype=None,
# layout=torch.strided,
# device=None,
# requires_grad=False)
t = torch.linspace(2, 10, 6) # (10-2)/(6-1)=1.6
print(t) # tensor([ 2.0000, 3.6000, 5.2000, 6.8000, 8.4000, 10.0000])
torch.logspace() 属性多一个base=10.0,对数底
torch.eye() 创建对角矩阵
# torch.eye(n, # 矩阵行数,默认为方阵
# m=None,
# out=None,
# dtype=None,
# layout=torch.strided,
# device=None,
# requires_grad=False)
2.3 依概率分布创建Tensor
比如,正态分布(高斯分布),均值mean, 标准差std, 分别为标量,张量,共四种模式。
# torch.normal(mean,
# std,
# out=None)
#
# torch.normal(mean,
# std,
# size,
# out=None)
#
# 1. mean:张量 std: 张量
mean = torch.arange(1, 5, dtype=torch.float)
std = torch.arange(1, 5, dtype=torch.float)
t_normal = torch.normal(mean, std)
print("mean:{}\nstd:{}".format(mean, std))
print(t_normal)
# mean:tensor([1., 2., 3., 4.])
# std:tensor([1., 2., 3., 4.])
# tensor([1.6614, 2.5338, 3.1850, 6.4853])
# mean和std各位置一一对应
# 2. mean:标量 std: 标量
t_normal = torch.normal(0., 1., size=(4,))
print(t_normal)
# tensor([-0.4519, -0.1661, -1.5228, 0.3817])
# 3. mean:张量 std: 标量
mean = torch.arange(1, 5, dtype=torch.float)
std = 1
t_normal = torch.normal(mean, std)
print("mean:{}\nstd:{}".format(mean, std))
print(t_normal)
# mean:tensor([1., 2., 3., 4.])
# std:1
# tensor([-0.0276, 1.4369, 2.1077, 3.9417])
# 4. mean: 标量 std: 张量
mean = 1
std = torch.arange(1, 5, dtype=torch.float)
t_normal = torch.normal(mean, std)
print("mean:{}\nstd:{}".format(mean, std))
print(t_normal)
# mean:1
# std:tensor([1., 2., 3., 4.])
# tensor([ 0.8045, -0.9313, 2.2672, 2.0693])
3. 张量操作
张量的操作包括:拼接、切分、索引、变换。
3.1 张量的拼接和切分
张量的拼接 torch.cat() torch.stack()
stack()会扩张张量维度,cat()不会
# torch.cat(tensors,
# dim=0,
# out=None)
#
# torch.stack(tensors,
# dim=0,
# out=None)
t = torch.ones((2, 3))
t_0 = torch.cat([t, t], dim=0)
# t_0:tensor([[1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.]]) shape:torch.Size([4, 3])
t_1 = torch.cat([t, t, t], dim=1)
# t_1:tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1., 1., 1., 1., 1.]]) shape:torch.Size([2, 9])
print("t_0:{} shape:{}\nt_1:{} shape:{}".format(t_0, t_0.shape, t_1, t_1.shape))
t = torch.ones((2, 3))
t_stack = torch.stack([t, t, t], dim=0)
# t_stack:tensor([[[1., 1., 1.],
# [1., 1., 1.]],
#
# [[1., 1., 1.],
# [1., 1., 1.]],
#
# [[1., 1., 1.],
# [1., 1., 1.]]]) shape:torch.Size([3, 2, 3])
print("\nt_stack:{} shape:{}".format(t_stack, t_stack.shape))
torch.chunk() 将张量按维度dim进行平均切分
返回值:张量列表,若不能整除,最后一个张量小于其他张量
torch.split() 功能更强大,可以指定切分的长度
# torch.chunk(input,
# chunks, # 要切分的份数
# dim=0)
a = torch.ones((2, 7)) # 7
list_of_tensors = torch.chunk(a, dim=1, chunks=3) # 3
# 第1个张量:tensor([[1., 1., 1.],
# [1., 1., 1.]]), shape is torch.Size([2, 3])
# 第2个张量:tensor([[1., 1., 1.],
# [1., 1., 1.]]), shape is torch.Size([2, 3])
# 第3个张量:tensor([[1.],
# [1.]]), shape is torch.Size([2, 1])
for idx, t in enumerate(list_of_tensors):
print("第{}个张量:{}, shape is {}".format(idx+1, t, t.shape))
# torch.split(tensor,
# split_size_or_sections, # int, 每一份的长度, list, 按list元素切分
# dim=0)
t = torch.ones((2, 5))
list_of_tensors = torch.split(t, [2, 1, 2], dim=1)
# 第1个张量:tensor([[1., 1.],
# [1., 1.]]), shape is torch.Size([2, 2])
# 第2个张量:tensor([[1.],
# [1.]]), shape is torch.Size([2, 1])
# 第3个张量:tensor([[1., 1.],
# [1., 1.]]), shape is torch.Size([2, 2])
for idx, t in enumerate(list_of_tensors):
print("第{}个张量:{}, shape is {}".format(idx+1, t, t.shape))
3.2 张量索引
torch.index_select() 在维度dim上,按index索引数据
torch.masked_select() 按mask中的True进行索引,返回值:一维张量
# torch.index_select(input,
# dim,
# index,
# out=None)
t = torch.randint(0, 9, size=(3, 3))
idx = torch.tensor([0, 2], dtype=torch.long) # float
t_select = torch.index_select(t, dim=0, index=idx)
# t:
# tensor([[4, 5, 0],
# [5, 7, 1],
# [2, 5, 8]])
# t_select:
# tensor([[4, 5, 0],
# [2, 5, 8]])
print("t:\n{}\nt_select:\n{}".format(t, t_select))
# torch.masked_select(input,
# mask,
# out=None)
t = torch.randint(0, 9, size=(3, 3))
mask = t.le(5) # ge is mean greater than or equal/ gt: greater than le lt
t_select = torch.masked_select(t, mask)
# t:
# tensor([[0, 2, 3],
# [1, 8, 4],
# [0, 3, 6]])
# mask:
# tensor([[ True, True, True],
# [ True, False, True],
# [ True, True, False]])
# t_select:
# tensor([0, 2, 3, 1, 4, 0, 3])
print("t:\n{}\nmask:\n{}\nt_select:\n{} ".format(t, mask, t_select))
3.3 张量变换
torch.reshape()
当张量在内存中是连续的时,新张量与input共享数据内存
# torch.reshape(input,
# shape)
t = torch.randperm(8)
t_reshape = torch.reshape(t, (-1, 2, 2)) # -1 根据其他维度计算,不需要关心
print("t:{}\nt_reshape:\n{}".format(t, t_reshape))
# t:tensor([5, 4, 2, 6, 7, 3, 1, 0])
# t_reshape:
# tensor([[[5, 4],
# [2, 6]],
#
# [[7, 3],
# [1, 0]]])
t[0] = 1024
print("t:{}\nt_reshape:\n{}".format(t, t_reshape))
print("t.data 内存地址:{}".format(id(t.data)))
print("t_reshape.data 内存地址:{}".format(id(t_reshape.data)))
# t:tensor([1024, 4, 2, 6, 7, 3, 1, 0])
# t_reshape:
# tensor([[[1024, 4],
# [ 2, 6]],
#
# [[ 7, 3],
# [ 1, 0]]])
# t.data 内存地址:2461063346072
# t_reshape.data 内存地址:2461063346072
torch.transpose() 交换张量的两个维度
torch.t() 2维张量转置,相当于torch.transpose(input, 0, 1)
# torch.transpose(input,
# dim0,
# dim1)
# torch.t(input)
t = torch.rand((2, 3, 4))
t_transpose = torch.transpose(t, dim0=1, dim1=2) # c*h*w h*w*c
print("t shape:{}\nt_transpose shape: {}".format(t.shape, t_transpose.shape))
# t shape:torch.Size([2, 3, 4])
# t_transpose shape: torch.Size([2, 4, 3])
torch.squeeze() 压缩长度为1的维度,dim为None,移除所有长度为1的轴,dim指定时,移除指定维度的。
torch.unsqueeze() 依据dim扩展维度
# torch.squeeze(input,
# dim=None,
# out=None)
#
# torch.unsqueeze(input,
# dim,
# out=None)
t = torch.rand((1, 2, 3, 1))
t_sq = torch.squeeze(t)
t_0 = torch.squeeze(t, dim=0)
t_1 = torch.squeeze(t, dim=1)
t_u = torch.unsqueeze(t_sq, dim=1)
print(t.shape) # torch.Size([1, 2, 3, 1])
print(t_sq.shape) # torch.Size([2, 3])
print(t_0.shape) # torch.Size([2, 3, 1])
print(t_1.shape) # torch.Size([1, 2, 3, 1])
print(t_u.shape) # torch.Size([2, 1, 3])

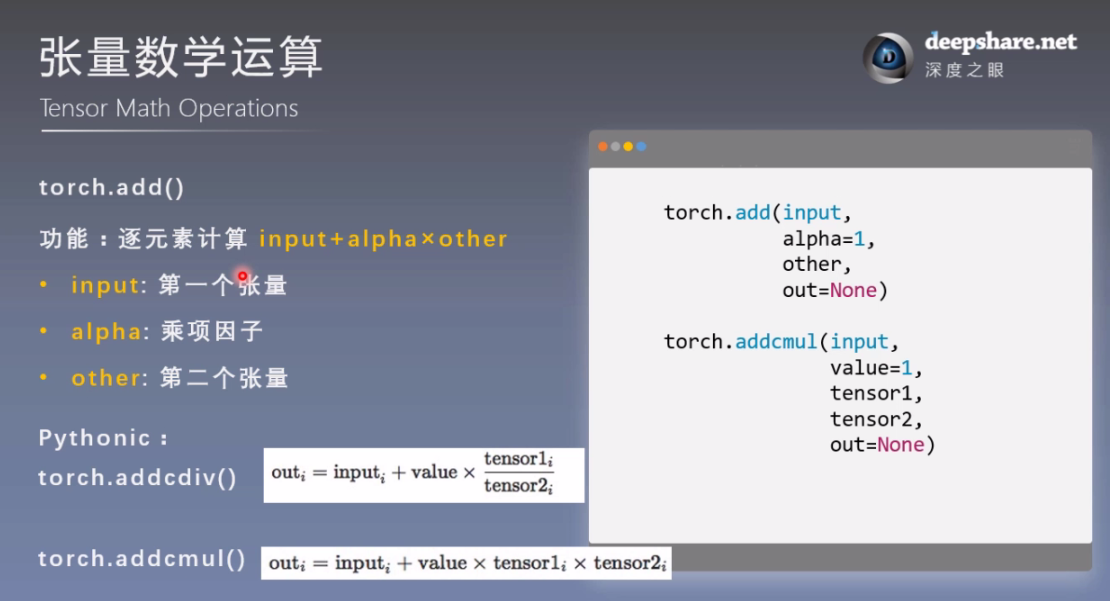
t_0 = torch.randn((3, 3))
t_1 = torch.ones_like(t_0)
t_add = torch.add(t_0, 10, t_1)
print("t_0:\n{}\nt_1:\n{}\nt_add_10:\n{}".format(t_0, t_1, t_add))
# t_0:
# tensor([[ 0.6614, 0.2669, 0.0617],
# [ 0.6213, -0.4519, -0.1661],
# [-1.5228, 0.3817, -1.0276]])
# t_1:
# tensor([[1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.]])
# t_add_10:
# tensor([[10.6614, 10.2669, 10.0617],
# [10.6213, 9.5481, 9.8339],
# [ 8.4772, 10.3817, 8.9724]])
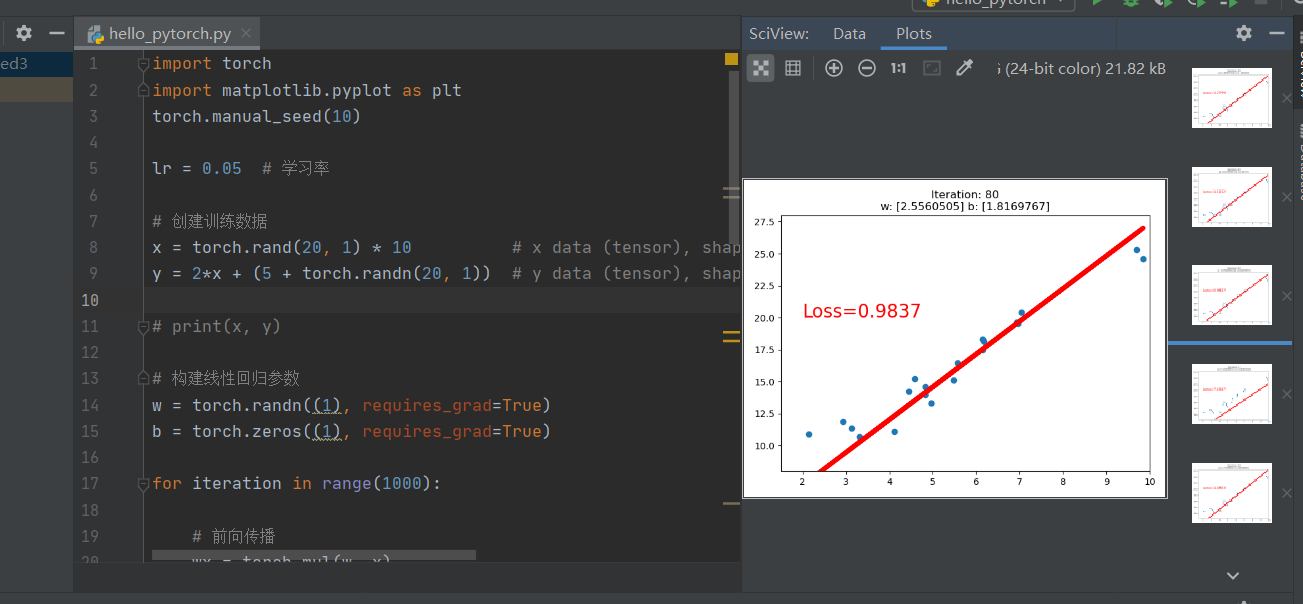
4. 实现线性回归

import torch
import matplotlib.pyplot as plt
torch.manual_seed(10)
lr = 0.05 # 学习率
# 创建训练数据
x = torch.rand(20, 1) * 10 # x data (tensor), shape=(20, 1) rand, 均匀分布中随机抽取
y = 2*x + (5 + torch.randn(20, 1)) # y data (tensor), shape=(20, 1) randn, 正态分布中随机抽取
# print(x, y)
# 构建线性回归参数
w = torch.randn((1), requires_grad=True)
b = torch.zeros((1), requires_grad=True)
for iteration in range(1000):
# 前向传播
wx = torch.mul(w, x)
y_pred = torch.add(wx, b)
# 计算 MSE loss
loss = (0.5 * (y - y_pred) ** 2).mean()
# 反向传播
loss.backward()
# 更新参数
b.data.sub_(lr * b.grad) # 下划线表示原地操作 in-place,不产生返回值,不会产生副本
w.data.sub_(lr * w.grad)
# 清零张量的梯度
w.grad.zero_()
b.grad.zero_()
# 绘图
if iteration % 20 == 0:
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), y_pred.data.numpy(), 'r-', lw=5)
plt.text(2, 20, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.xlim(1.5, 10)
plt.ylim(8, 28)
plt.title("Iteration: {}\nw: {} b: {}".format(iteration, w.data.numpy(), b.data.numpy()))
plt.pause(0.5)
if loss.data.numpy() < 1:
break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号