
【笔记】机器学习 - 李宏毅 -- ELMO、BERT、GPT
1.背景知识
one-hot -> word class -> word embedding
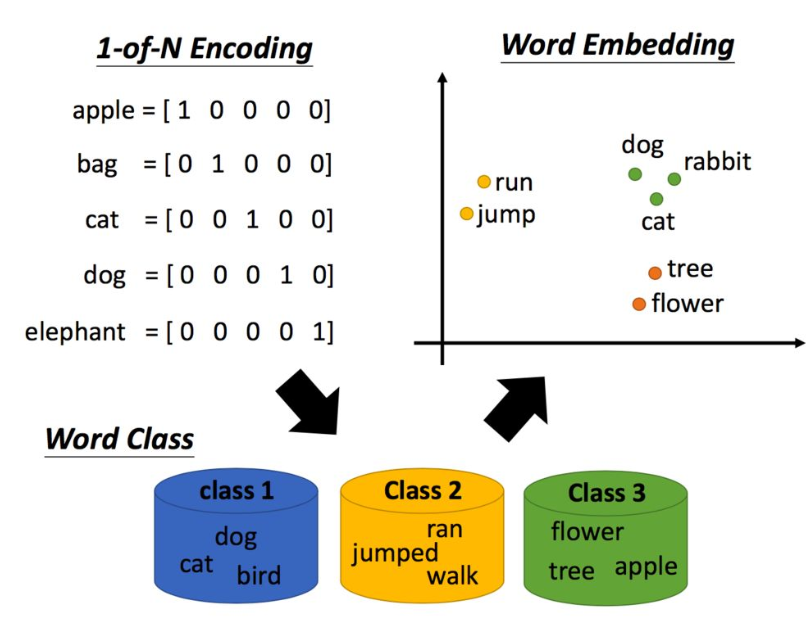
不过传统的word embedding解决不了多义词的问题。

2. ELMO
为了解决上述问题,首先有了ELMO。
它是一个双向的RNN网络,这样每一个单词都对应两个hidden state,进行拼接便可以得到单词的Embedding表示。当同一个单词上下文不一样,得到的embedding就不同。
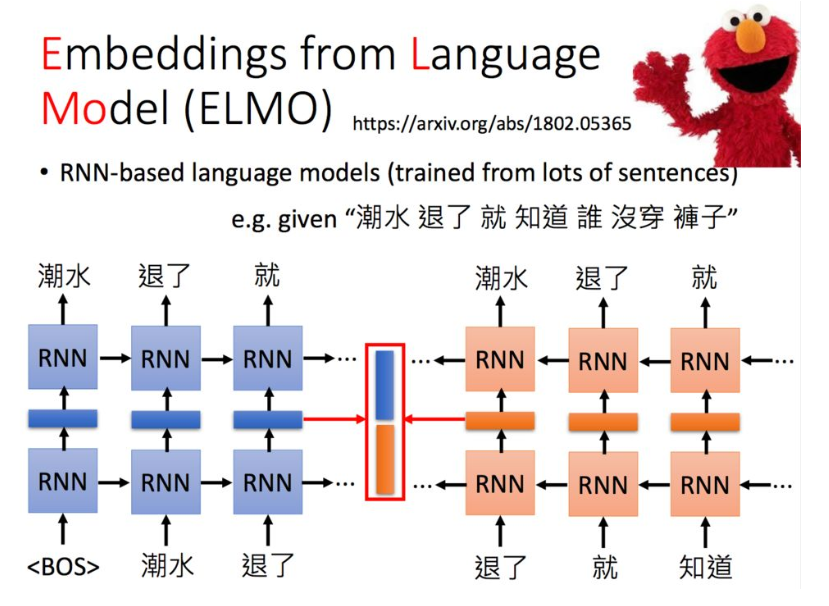
当然也可以搞很多层,每一层得到的embedding都要。

根据下游任务,可以得到不同embedding的权重。

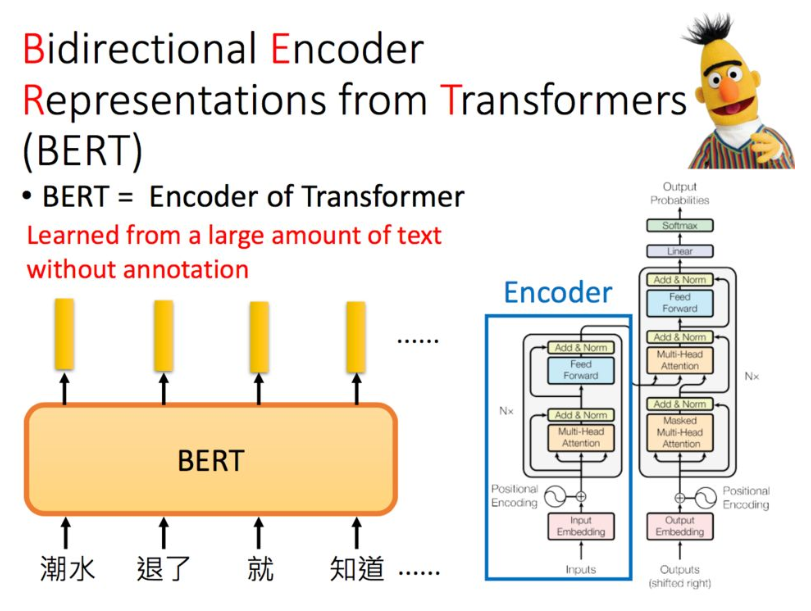
3. BERT
BERT只是Transformer中的Encoder,那Bert怎么训练呢?有两种方法。
第一个称为Masked LM,做法是随机把一些单词变为Mask,让模型去猜测盖住的地方是什么单词。
假设输入里面的第二个词汇是被盖住的,把其对应的embedding输入到一个多分类模型中,来预测被盖住的单词。

另一种方法是预测下一个句子,这里,先把两句话连起来,中间加一个[SEP]作为两个句子的分隔符。
而在两个句子的开头,放一个[CLS]标志符,将其得到的embedding输入到二分类的模型,输出两个句子是不是接在一起的。

实际中,同时使用两种方法往往得到的结果最好。
在ELMO中,训练好的embedding是不会参与下游训练的,下游任务会训练不同embedding对应的权重,但在Bert中,Bert是和下游任务一起训练的。
4. BERT的应用
如果是分类任务,在句子前面加一个标志,将其经过Bert得到的embedding输出到二分类模型中,得到分类结果。二分类模型从头开始学,而Bert在预训练的基础上进行微调(fine-tuning)。
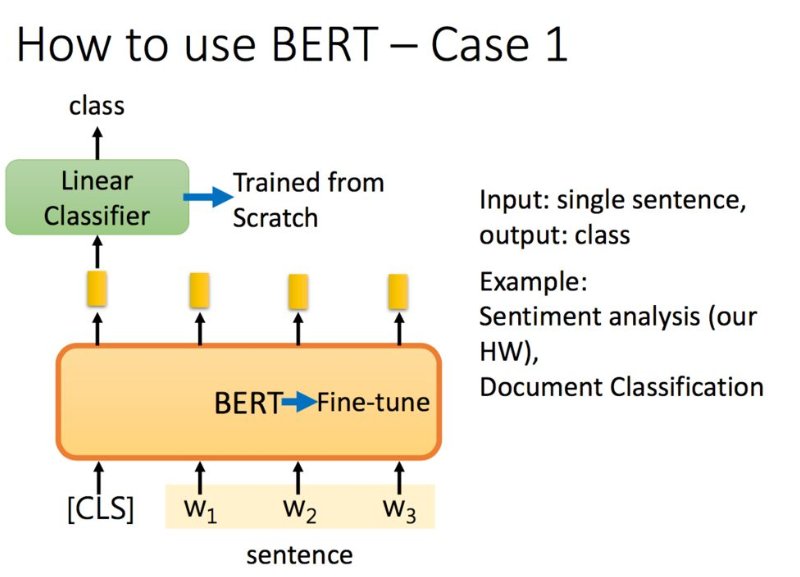
单词分类:
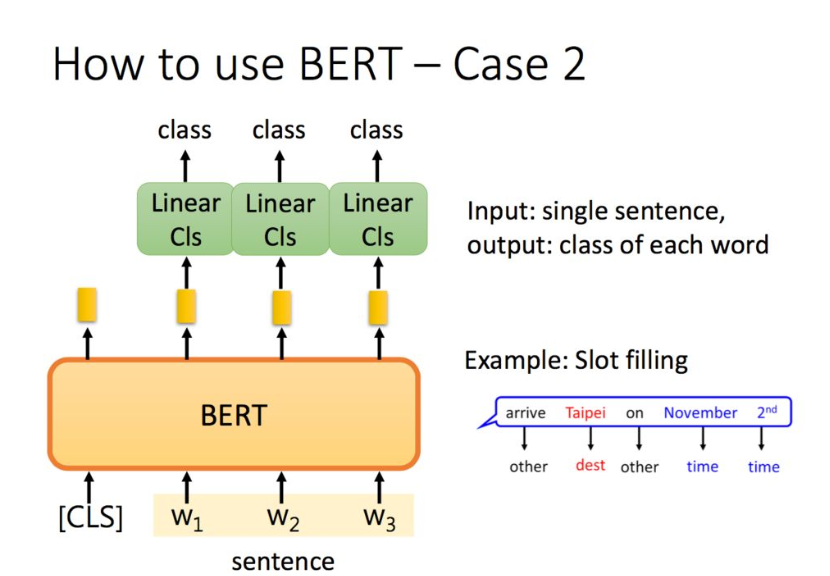
自然语言推理任务,给定一个前提/假设,判断得到推论是否正确:

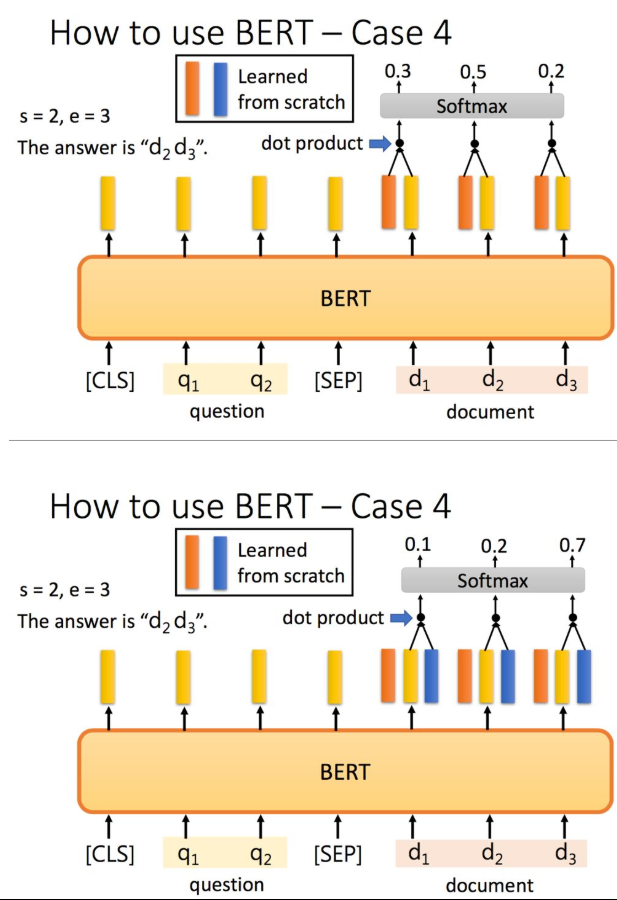
最后一个例子是抽取式QA,抽取式的意思是输入一个原文和问题,输出两个整数start和end,代表答案在原文中的起始位置和结束位置,两个位置中间的结果就是答案。

把问题 - 分隔符 - 原文输入到BERT中,每一个单词输出一个黄颜色的embedding,这里还需要学习两个(一个橙色一个蓝色)的向量,这两个向量分别与原文中每个单词对应的embedding进行点乘,经过softmax之后得到输出最高的位置。正常情况下start <= end,但如果start > end的话,说明是矛盾的case,此题无解。
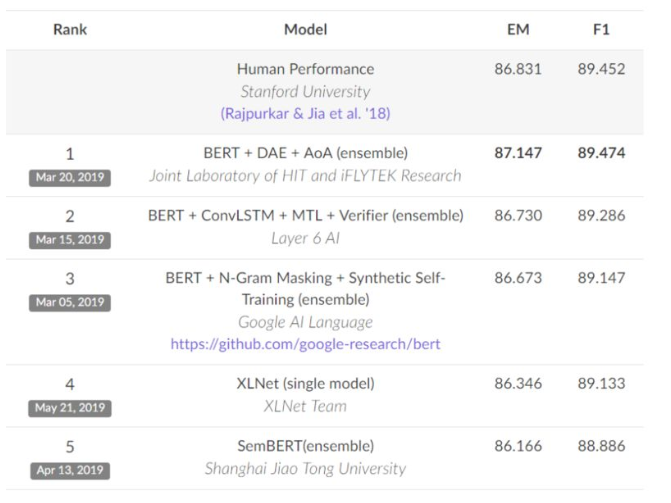
BERT在各大比赛中刷榜:
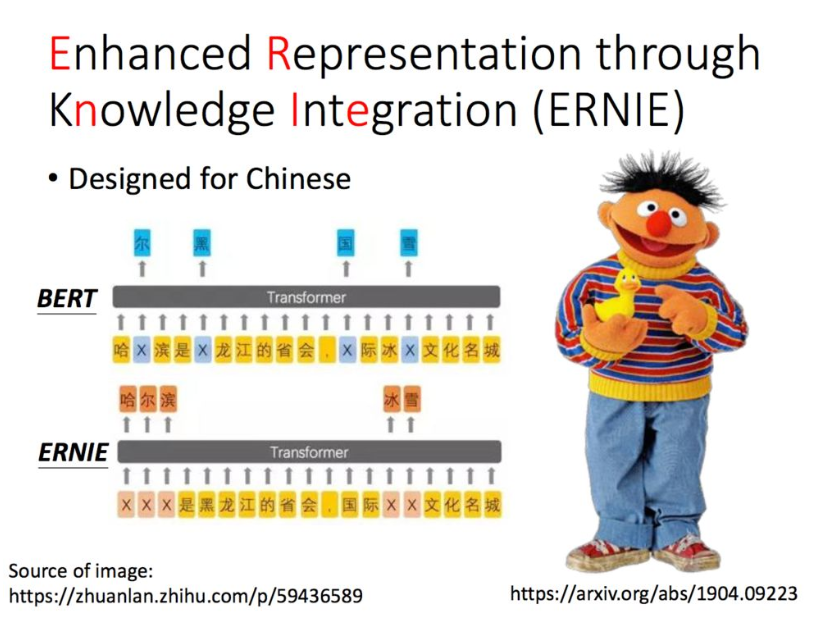
5. ERNIE
百度的ERNIE。
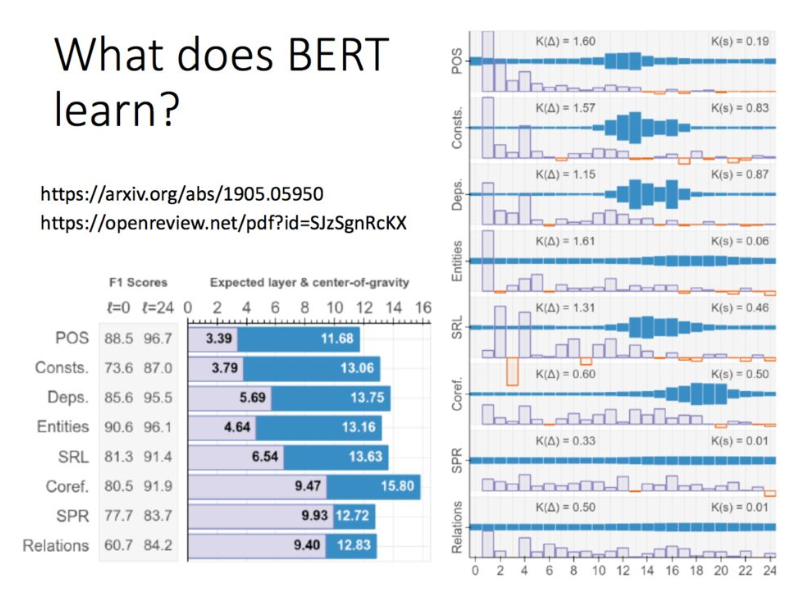
BERT学到了什么?
6. GPT-2
GPT-2的模型非常巨大,它其实是Transformer的Decoder。


由于GPT-2的模型非常巨大,它在很多任务上都达到了惊人的结果,甚至可以做到zero-shot learning(简单来说就是模型的迁移能力非常好),如阅读理解任务,不需要任何阅读理解的训练集,就可以得到很好的结果。
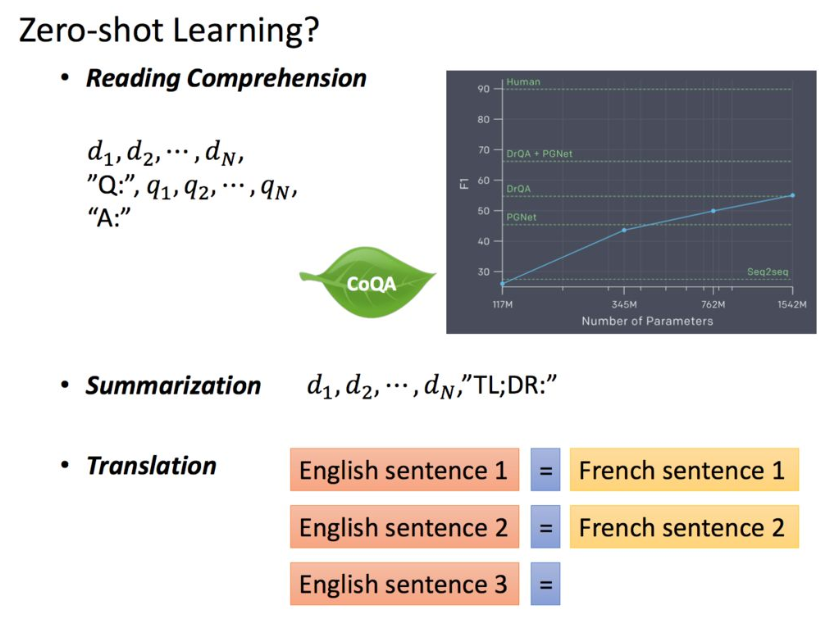
还可以自己进行写作,效果惊人。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号