
【笔记】机器学习 - 李宏毅 -- Transformer
1.RNN和CNN的局限性
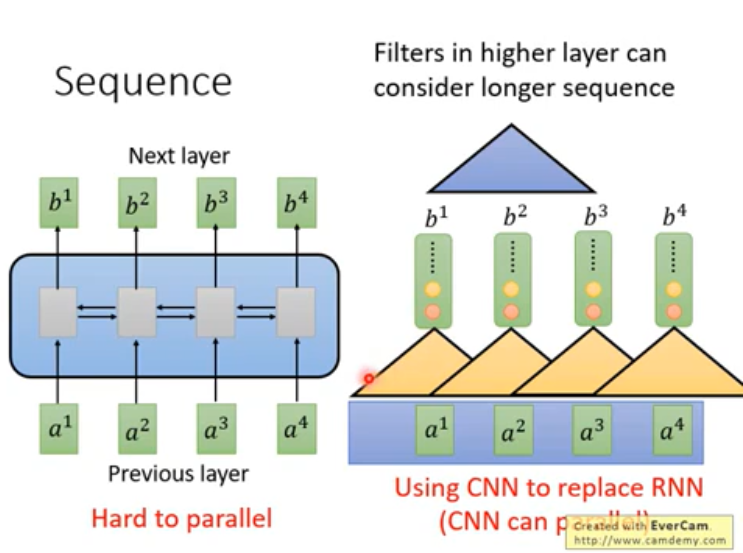
RNN是seq2seq的模型,RNN不易平行化,如果是单向的话,要输出\(b^3\),需要先看完\(a^1, a^2, a^3\)。如果是双向的话,可以看完整个句子。
CNN在高层的时候,可以考虑距离更长的信息,CNN易于并行化。CNN的缺点是,考虑的只是局部内容,要考虑长距信息,需要叠加很多层。
2.Self-attention
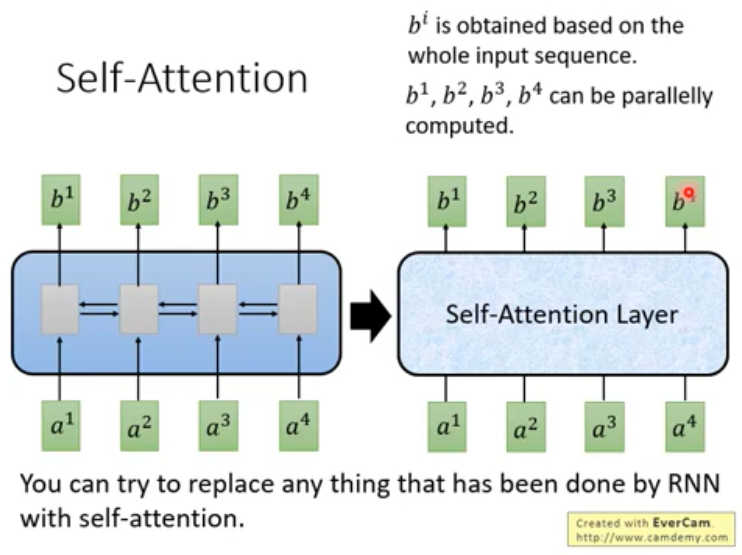
attention和bi-RNN有同样的能力,可以看完整个句子,并且可以并行化。所以同时包括了RNN和CNN的优点。
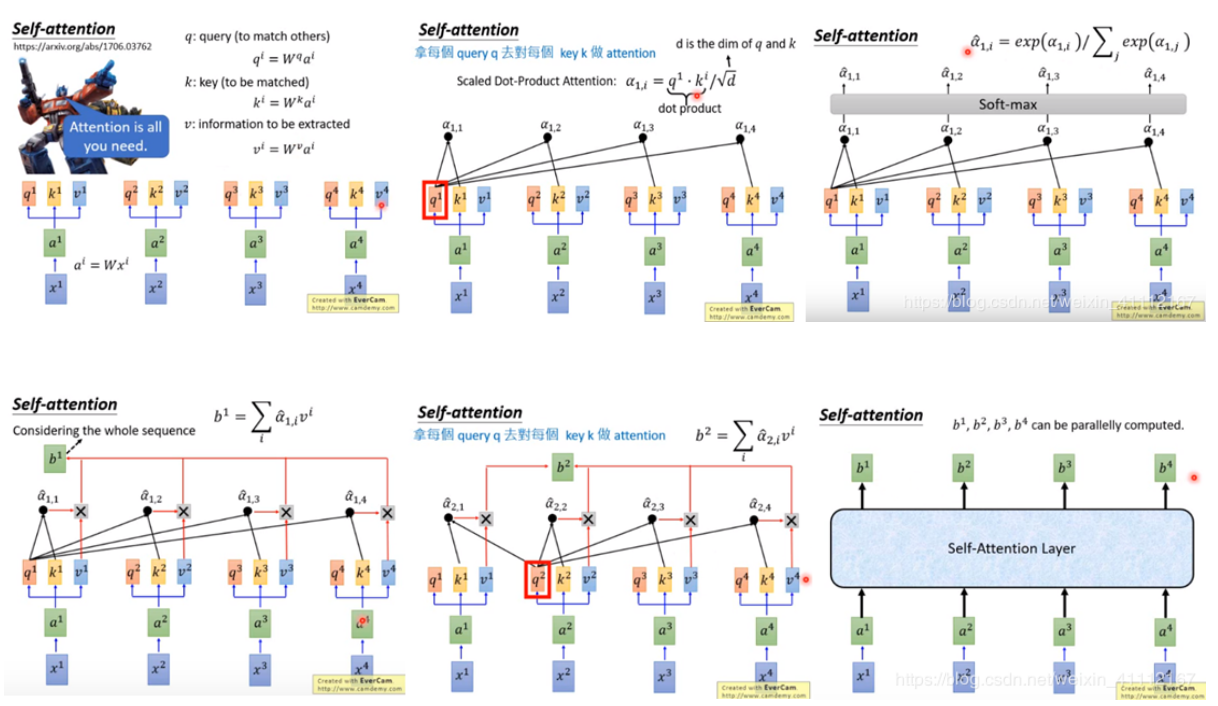
计算过程如下:
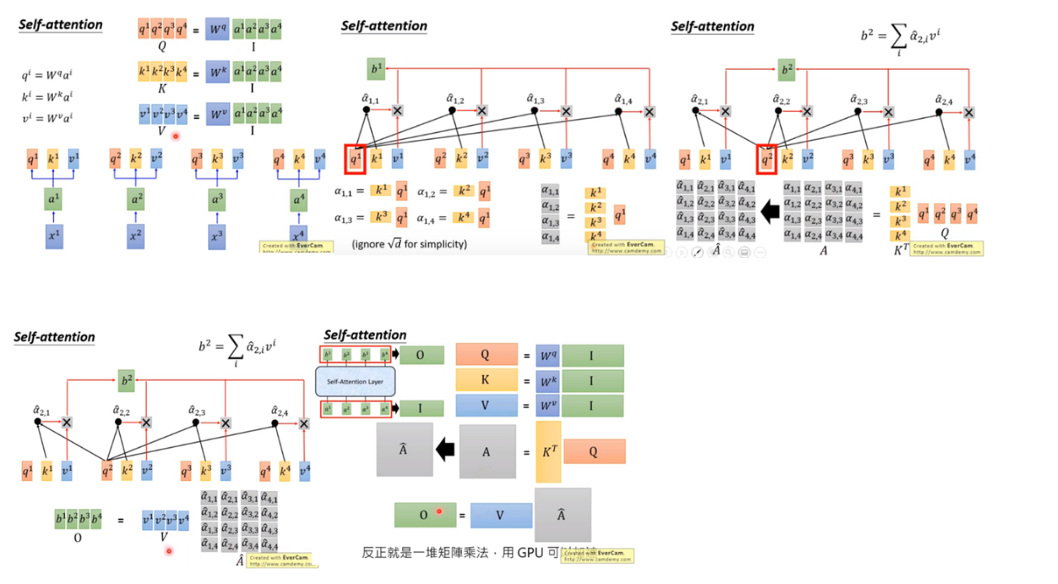
并行计算过程演示:
多头机制,有的head可能考虑局部信息,有的head考虑长距信息,各司其职。
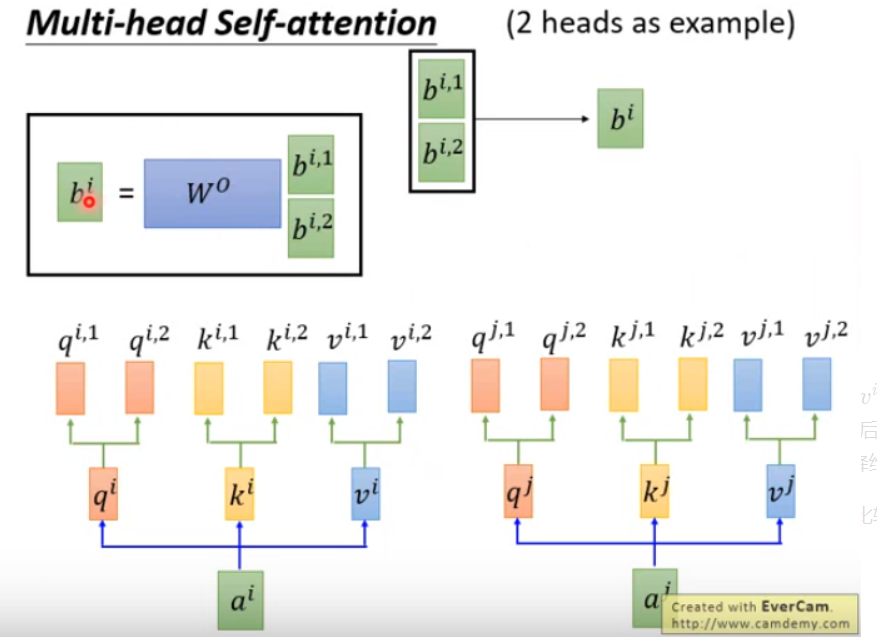
3.attention的局限性
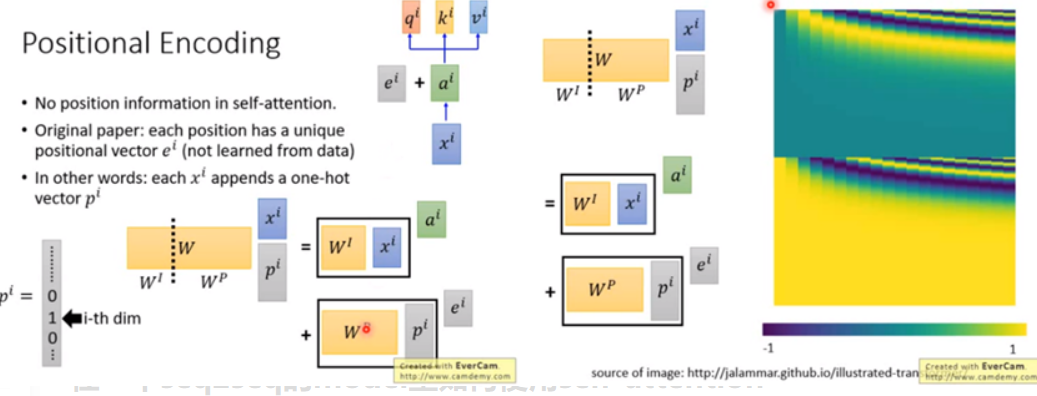
由于和每个input vector都做attention,没有考虑到顺序位置信息。
所以在原始paper里面,每一个input \(x^i\) 通过transform变成 \(a^i\) 以后,还要加上一个维度相同的向量 \(e^i\), \(e^i\) 是手设的,代表位置的资讯。
换一种讲法就是,在input \(x^i\) 后连接一个one-hot vector \(p^i\) 代表位置资讯,第i维是1,其余都是0。
连接之后乘上一个矩阵 W 做transform,W 可以拆成 \(W^I\) 和 \(W^P\),把 \(W^I\)跟 \(x^i\) 相乘得到 \(a^i\),\(W^p\)跟 \(p^i\) 相乘得到 \(e^i\)。
\(W^P\) 是可以learn的,论文里面是人手设的。
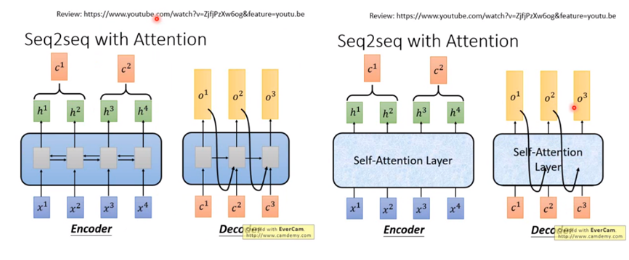
4.seq2seq中如何用attention
一般的seq2seq model包含两个RNN,分别是encoder和decoder,都可以用self-attention 取代掉。总之,看到RNN用self-attention替换掉。
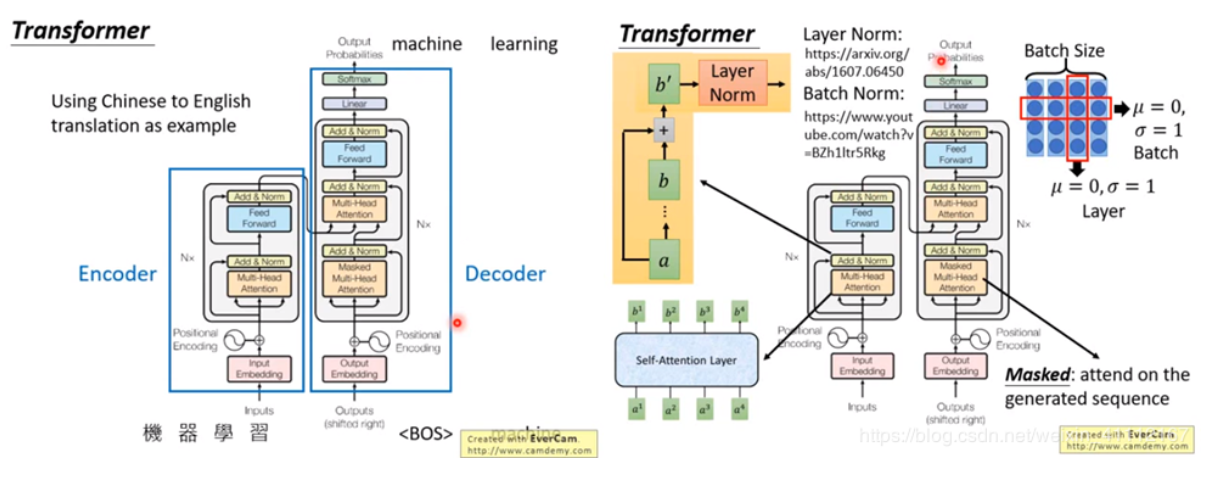
5.Transformer
以把中文翻译成英文为例,encoder的输入是中文的character sequence比如说是机器学习,在decoder给他一个begin of sequence的token就输出一个machine,在下一个timestep把machine当作输入,就输出learning,直到输出句点的时候翻译过程结束。
接下来看每一个layer做的事情。
-
先看左半部的encoder,input通过input embedding layer变成一个vector,然后vector加上positonal encoding,接下来进入灰色的block,这个block重复N次。
-
在灰色的block里面,第一层是multi-head attention,也就是说input一个sequence,通过multi-head attention layer得到另外一个sequence。
-
下一个layer是add & norm,在这一步,把multi-head attention 的 output 跟 multi-head attention 的 input 相加,然后做layer normalization。参考文献见ppt。
Layer normalization和batch normalization 的异同:
假设有一个大小为4的batch,在batch normalization 的时候,是对同一个batch里面不同data里面的同样的dimension做normalization,希望同一个dimension 的均值为0,方差为1。
而layer normalization是不需要考虑bacth的,给一个data,希望各个不同dimension的均值为0,方差为1。
一般情况下layer normalization会搭配RNN一起使用。transformer很像RNN,所以这里使用layer normalization。
-
接下来feed forward layer 会把input sequence 的每一个vector进行处理,还有另外一个add & norm 的layer。
-
接下来是右半部decoder的部分,这个decoder的input 是前一个time step 产生的output,通过output embedding 加上positional information,进入灰色的block,这个block重复N次。
-
这个灰色block的第一层叫masked multi-head attention。加masked的意思是说,现在做self-attention的时候,decoder会attend 到已经产生出来的 sequence,因为还没有产生出来的无法做attention。
-
add & norm layer
-
接下来是multi-head attention layer,这个是attend 到之前encoder的输出。
-
接下来还有add & norm layer, feed forward layer,add & norm layer
-
最后做linear,softmax得到最终的output
6.原始论文里Transformer的可视化
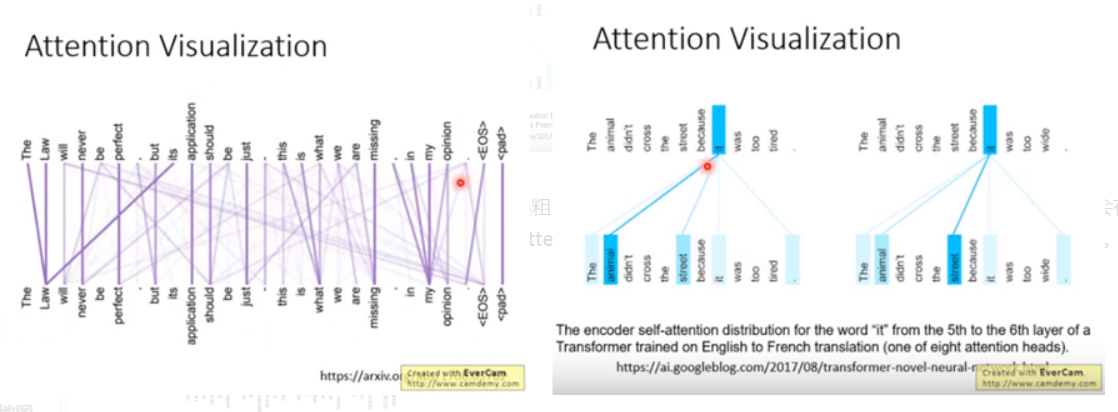
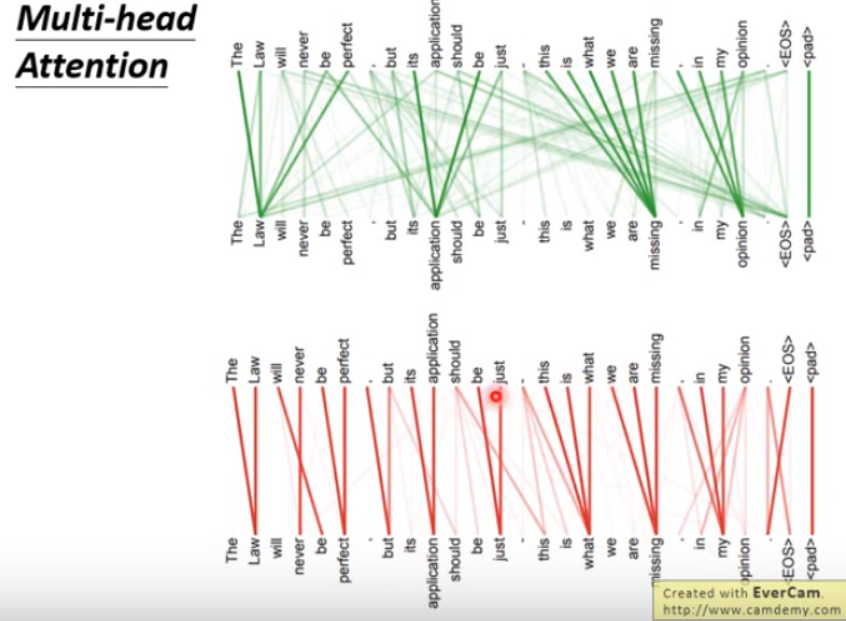
7.Transformer的应用
基本上原来可以做seq2seq的,都可以换成transformer。
-
做summarization
训练一个summarizer,input是一堆文章,output是一篇具有维基百科风格的文章。如果没有transformer,没有self-attention,很难用RNN产生\(10^3\)长的sequence,而有了transformer以后就可以实现。 -
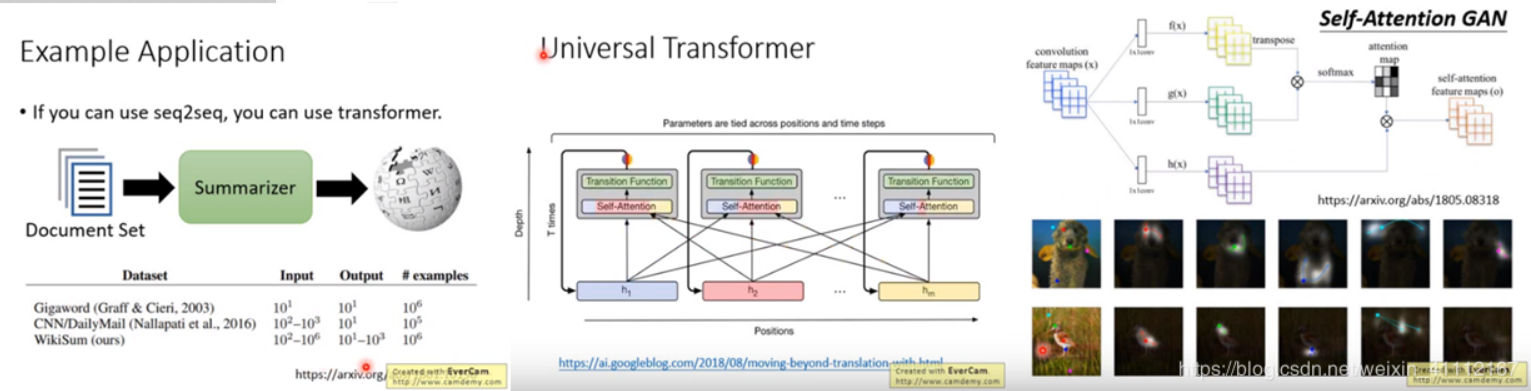
Universal transformer
简单的概念是说,本来transformer每一层都是不一样,现在在深度上做RNN,每一层都是一样的transformer,同一个transformer的block不断的被反复使用。 -
影像self-attention GAN
让每一个pixel都attend到其他的pixel,可以考虑比较global的资讯.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号