

【笔记】B站-2019-NLP(自然语言处理)之 BERT 课程 -- BERT理论部分
BERT 课程笔记
1. 传统方案遇到的问题
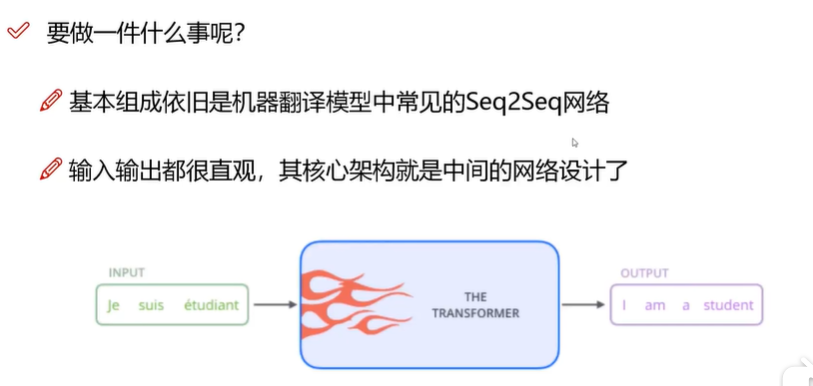
BERT的核心在于Transformer,Transformer就类似seq2seq网络输入输出之间的网络结构。
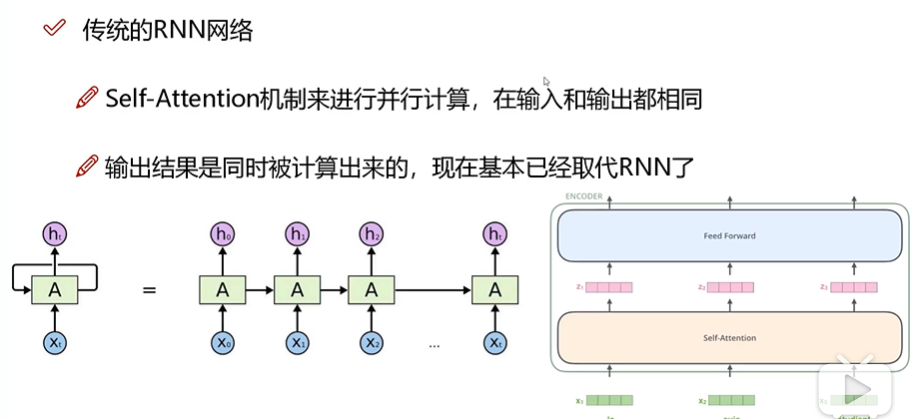
传统的RNN网络:最大的问题,因为不能并行计算,所以往往深度不够。
传统的word2vec:同一个词一经训练词向量便确定了下来,缺乏适应不同语境的灵活性。

2. 注意力机制的作用
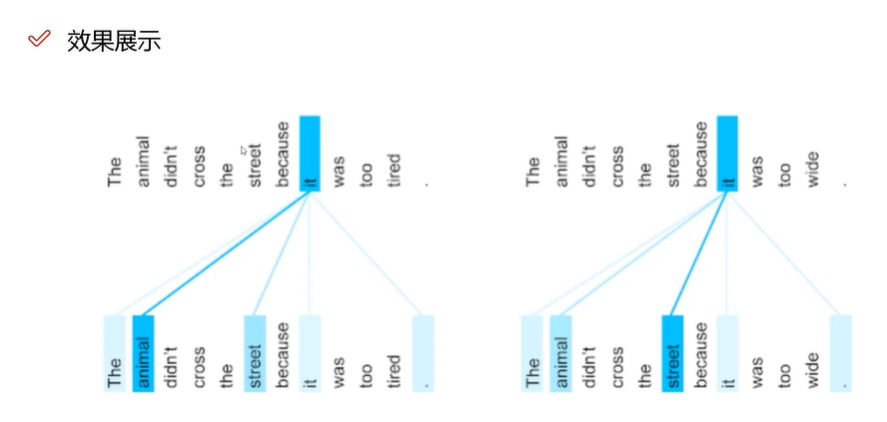
注意力机制的作用是能够体现句子中的重点词,而不是把所有词都同等看待。类似图右体现的关注热点区域。

self-attention举例:两个句子中it的指代是不同的,可以通过注意力机制体现出来。

3. Encoder部分:
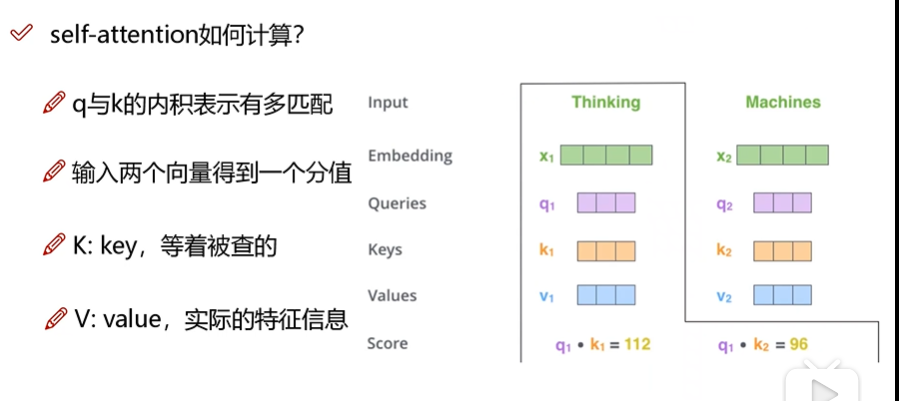
self-attention的计算方法:
首先是词嵌入,把输入的词表示成词向量。
然后,构建三个矩阵分别表示:上下文关系查询的施事者q,受事者k,以及实际的特征信息v。
计算相关性就是计算q和k的向量内积。

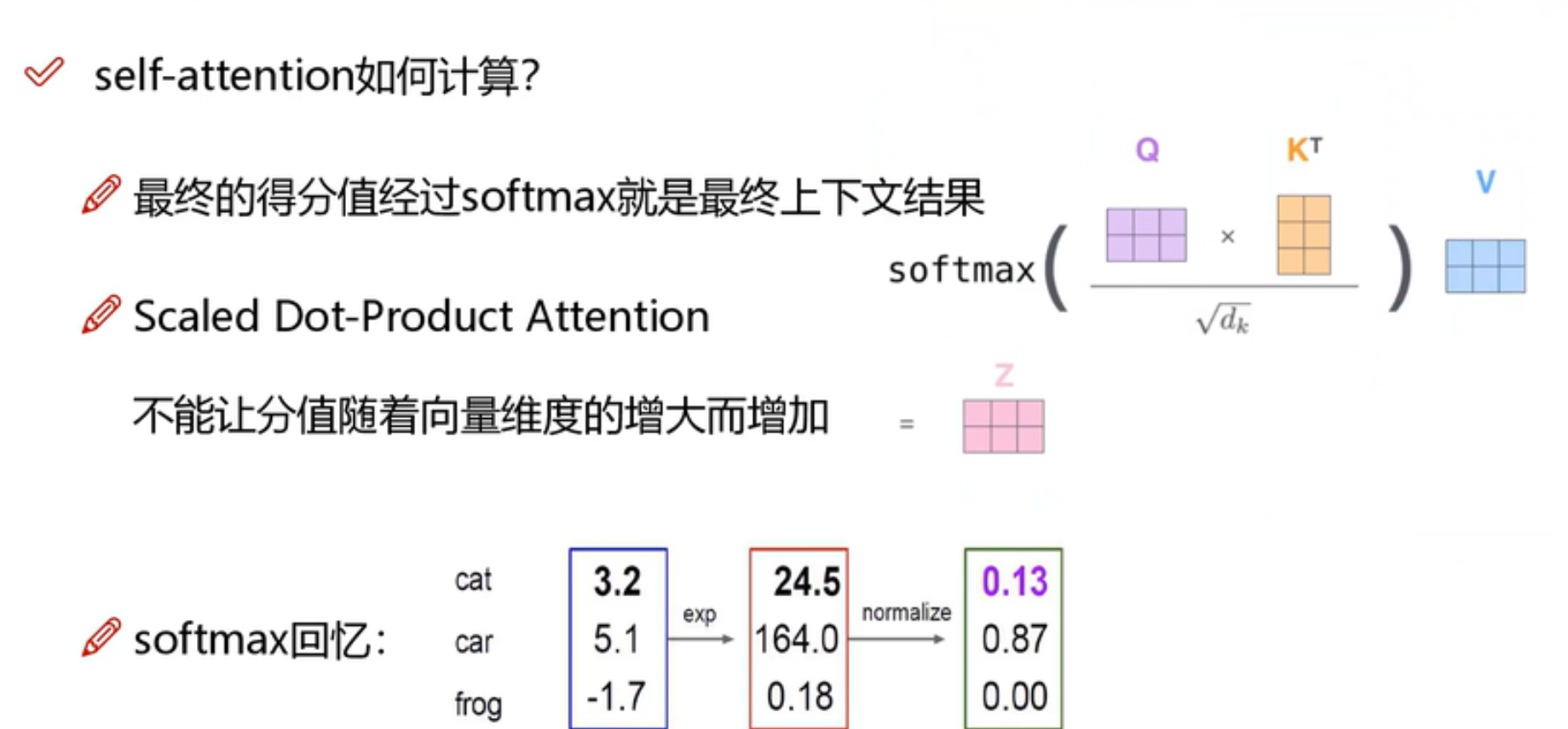
特征分配和softmax机制:
q和k相乘后的结果需要softmax以及归一化。其中还除以了一下向量维度的开方。然后乘以各自的v,就得到了z。
每个词都用同样的方式计算,都是矩阵计算,所以可以并行。计算流程如下:

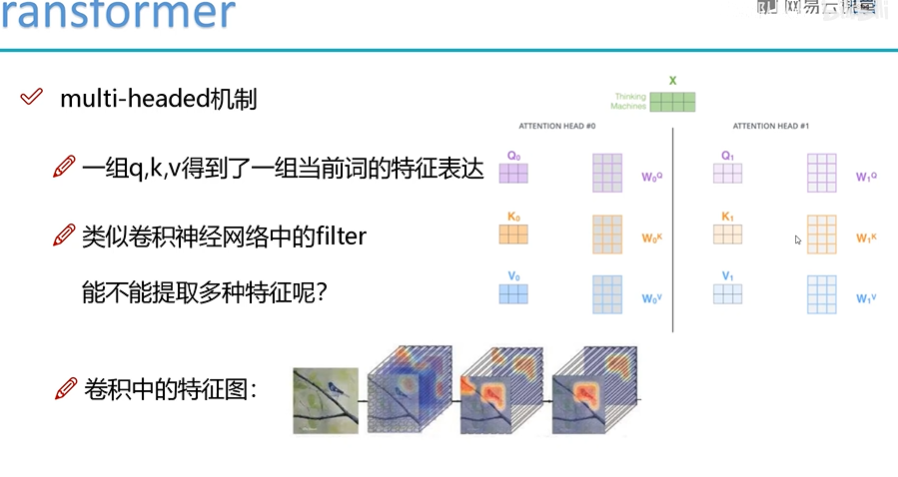
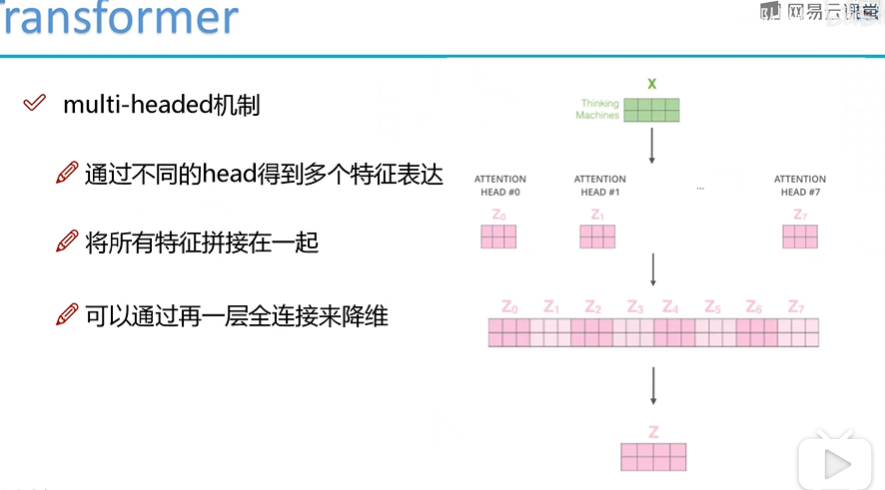
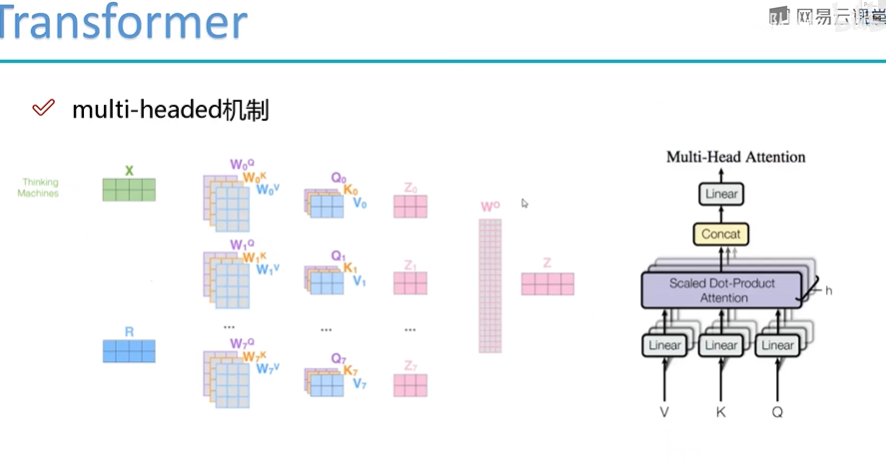
Multi-head的作用
Multi-head就类似CNN中的多个filter,提取多个特征。然后多个特征拼接,拼接后再用一个全连接网络来降维。
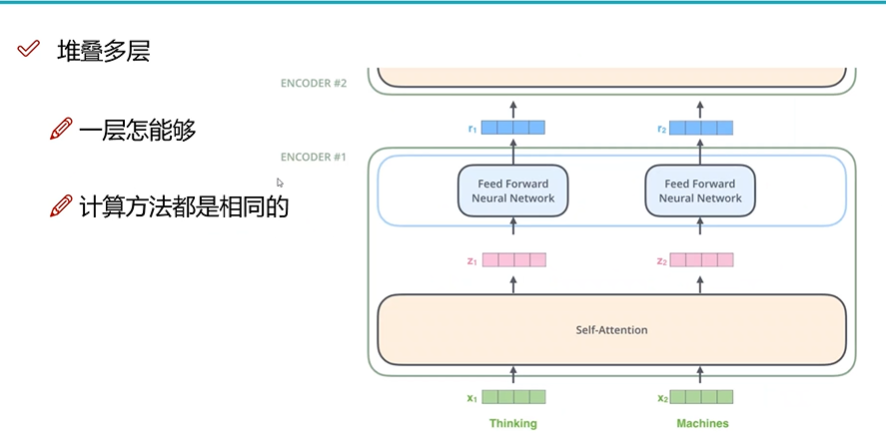
同样也可以和CNN一样堆叠多层(层数越多,特征越清晰)。
位置编码与多层堆叠
上述表示方法的问题在于,某个词出现在句子中的任何位置,都可以通过与其他词的计算得到同样的向量结果,这显然有问题。
解决策略就是,加上位置信息。位置信息有很多种表示方式,比如余弦、正弦这样的周期信号。

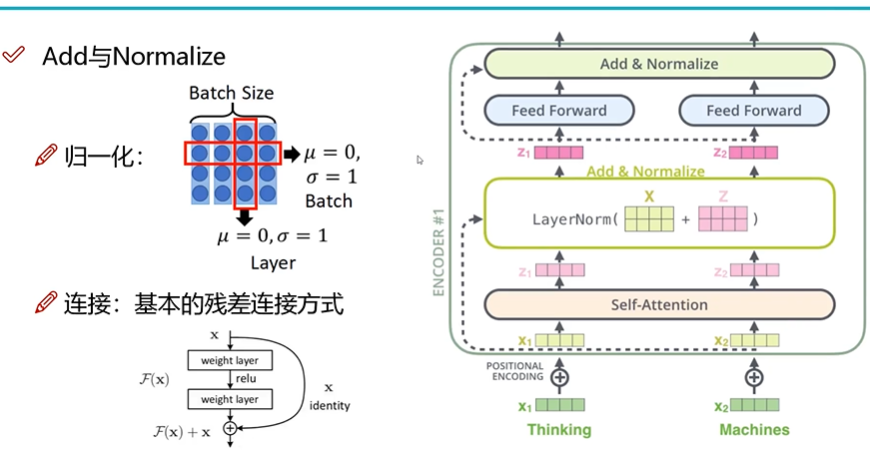
layer normalize,层归一化的含义,和batch normalize类似,只不过是不同层之间的归一化,如下图。归一化的好处是使训练更快更稳定。
残差连接方式的作用是,通过一层网络变换后的结果和最初的向量比较,看哪个更好(使梯度更小)用哪个,从而避免越训练越差。
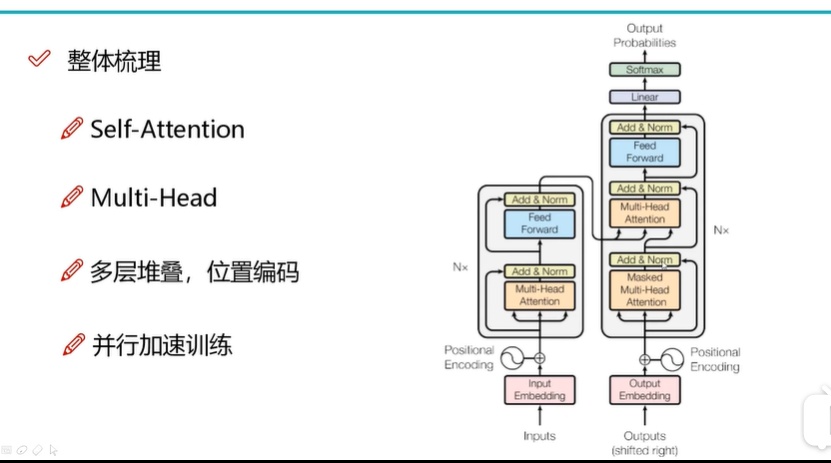
4. Transformer整体架构梳理
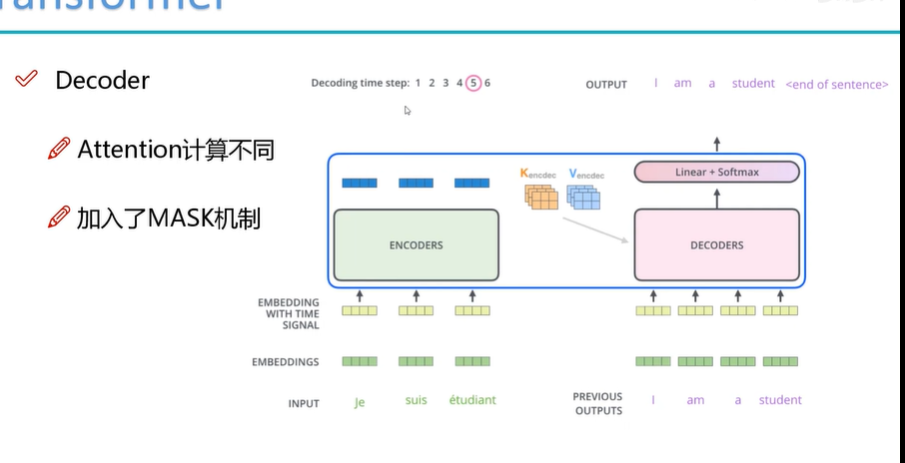
Decoder端和Encoder端差不多,不过Encoder得到的K,V会用到Decoder这儿,用q来查询。
此外还有MASK机制,就是还没有输出的词当做黑盒(暂时不知道)。
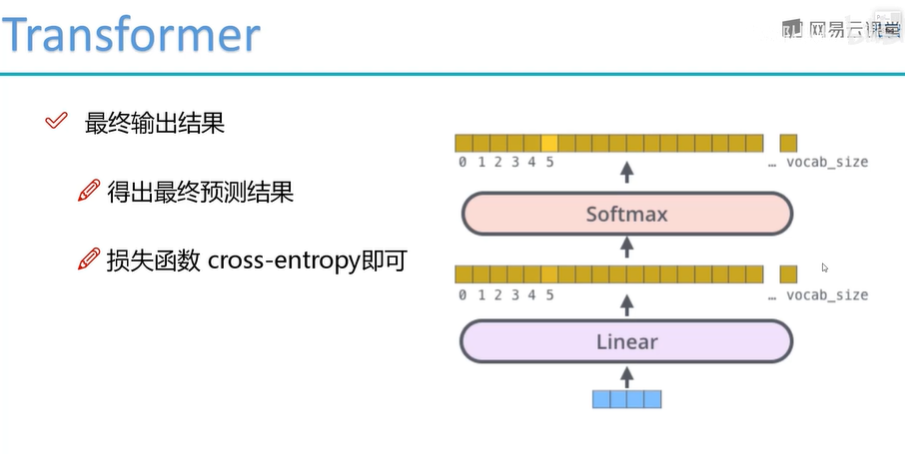
输出的话,就是一个分类任务,加个softmax。
==========================================================================
效果展示:
5. BERT模型
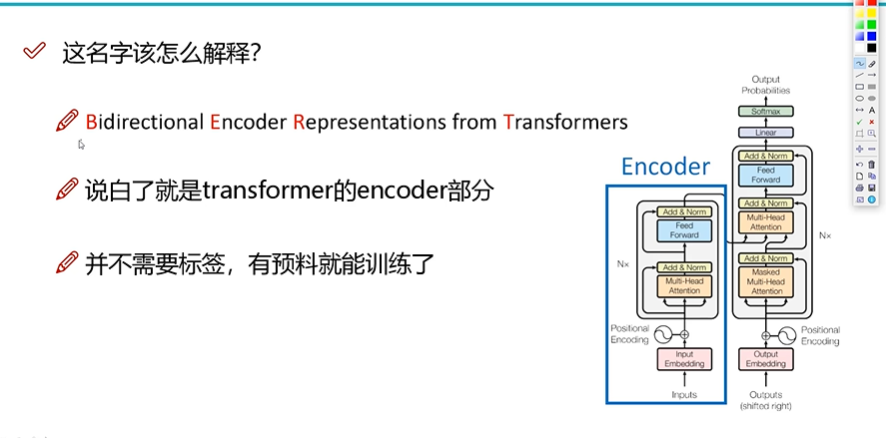
BERT模型训练原理
BERT就是Transformer的Encoder部分。
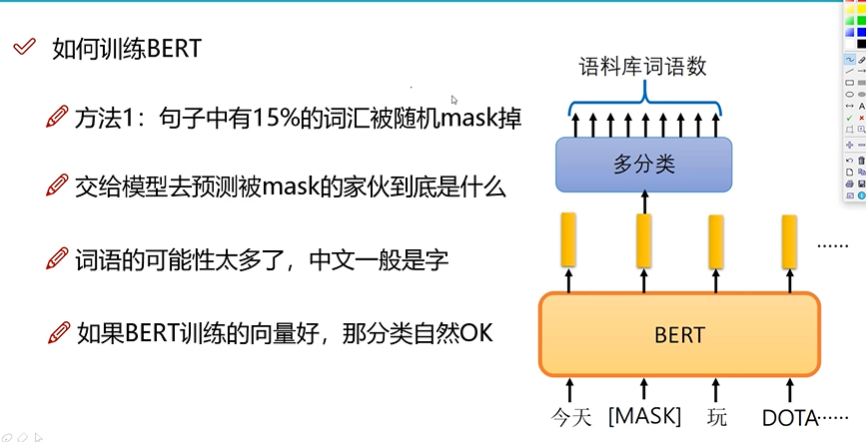
方法1:把15%的MASK掉,然后训练,得到的结果和自身比对,然后优化。注意:中文的粒度为字。
方法2:两个句子是否应该连在一起,做一个分类任务,yes/no。

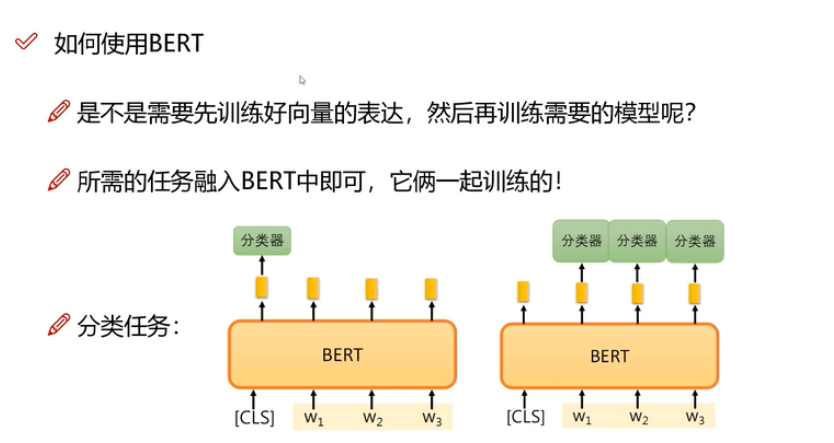
BERT和具体任务相结合
End2End,放在一起学习,不需要分步。
比如一个阅读理解的任务,输出的是答案词的位置编码。

额外训练两个辅助向量,然后用辅助向量和中间的结果向量做内积,然后可以得到答案为[d2, d3]。

相关资料
课程地址:2019 NLP(自然语言处理)之Bert课程
BERT github地址:google-bert
相关报道:吴恩达团队盘点2019AI大势:自动驾驶寒冬、NLP大跃进、Deepfake已成魔!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号