
【新人赛】阿里云恶意程序检测 -- 实践记录11.3 - n-gram模型调参
主要工作
本周主要是跑了下n-gram模型,并调了下参数。大概看了几篇论文,有几个处理方法不错,准备下周代码实现一下。
xgboost参数设置为:
param = {'max_depth': 6, 'eta': 0.1, 'eval_metric': 'mlogloss', 'silent': 1, 'objective': 'multi:softprob',
'num_class': 8, 'subsample': 0.5, 'colsample_bytree': 0.85}
n-gram模型,CountVectorizer
为了训练速度考虑,采用两折校验,对ngram_range参数,start=end,即只用某元:
| ngram | train-mean | val-mean |
|---|---|---|
| 1 | 0.113553 | 0.376238 |
| 2 | 0.086720 | 0.331593 |
| 3 | 0.085156 | 0.338862 |
| 4 | 0.102556 | 0.347408 |
| 5 | 0.090270 | 0.366249 |
import matplotlib.pyplot as plt
import numpy as np
train_mean = [0.113553, 0.086720, 0.085156, 0.102556, 0.090270]
val_mean = [0.376238, 0.331593, 0.338862, 0.347408, 0.366249]
# 绘制对比柱状图
plt.bar(x=range(1, 6), height=train_mean, label="train mean", alpha=0.8, width=bar_width)
plt.legend()
plt.xlabel("ngram_range(start=end)")
plt.ylabel("mean")
plt.title('result')
plt.show()
plt.bar(x=np.arange(1, 6), height=val_mean, label="val mean", alpha=0.8, width=bar_width)
plt.legend()
plt.xlabel("ngram_range(start=end)")
plt.ylabel("mean")
plt.title('result')
plt.show()
绘图可得:
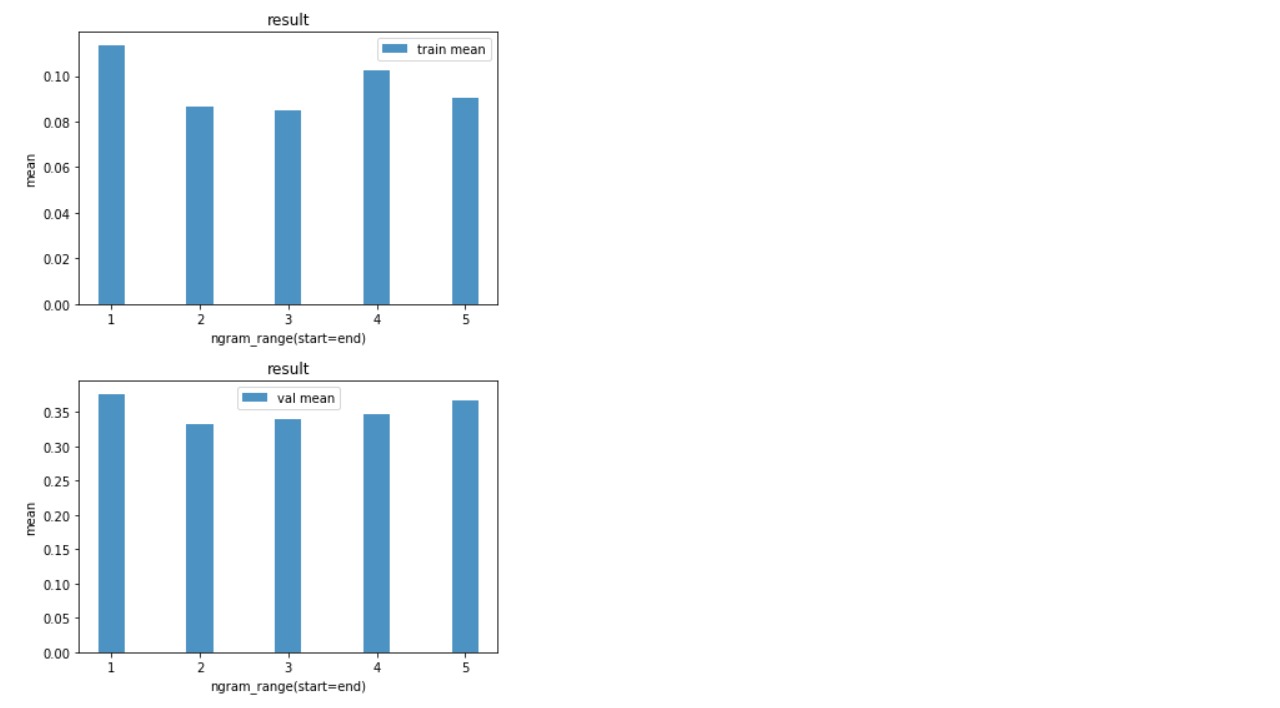
可以看到,二元、三元关系的拟合效果比较好。
所以在api序列中,依赖关系主要以短链为主,长链为辅,同时单个api也有一些价值。
而后,同样是2折校验,对start != end的情形做了一下训练。
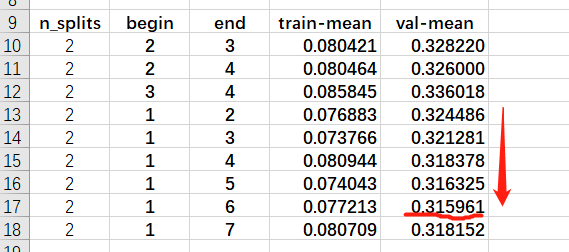
可以看到,start=1得到的结果比start=2得到的效果要好一些,
同时当start=1, end从2至6,拟合效果都有提升,当end=7之后又会变差。
所以n-gram模型,二元、三元的拟合效果比较好,加上一元,四元,五元,六元之后,效果都有提升,这几元都很有用。
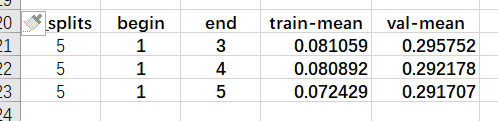
此外,将2折改为5折,计算开销增大,但结果会更好一些。
将5折得到的这几个结果,提交到线上,测试结果如下:
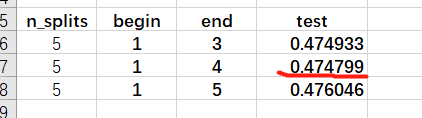
10折提交,结果如下:

在同学的基础上优化:
使用参数ngram_range=(1, 3),xgboost中subsample=0.8,


 浙公网安备 33010602011771号
浙公网安备 33010602011771号