Kubernetes: NGINX/PHP-FPM 502错误和优雅结束
我们有一个运行在Kubernetes上的PHP应用,每个POD由两个独立的容器组成 - Nginx和PHP-FPM。
在我们对应用进行缩容时,遇到了502错误,例如,当一个POD在结束中时,POD里面的容器无法正确关闭连接。
在这个博文中,让我们深入看一下POD的结束流程,特别是Nginx和PHP-FPM容器。
本文中的测试是在AWS Kubernetes Service上使用Yandex.Tank工具进行。
使用AWS ALB Ingress Controller创建Ingress并自动创建AWS Application Load Balancer。
Kubernetes工作节点上使用Docker作为容器运行时。
Pod的生命周期之Pod的结束
首先,让我们来看看pod结束的过程。
Pod其实是一组运行在Kubernetes工作节点上的进程,也受标准的IPC (Inter-Process Communication) 信号控制的。
为了让pod可以正常完成它的操作,容器运行时会先发送一个SIGTERM信号(优雅结束)给每个容器内的PID 1进程(参考docker stop)。同时,集群会开始计时,在grace period计时结束后,会发送SIGKILL信号直接杀掉pod。
在容器镜像中,可以使用STOPSIGNAL重写SIGTERM信号。
Pod删除的完整流程如下(以下引用自官方文档):
- 当用户通过kubectl delete或kubectl scale deployment命令触发pod删除时,集群会同时开始grace period的计时(默认30秒);
- API server会把pod的状态从Running更新为Terminating(参考Container states)。Pod所在工作节点上的kubelet接收到pod状态变化后,开始了pod结束流程;如果pod里面有容器配置了
preStophook,kubelet会执行它。假如30秒的grace period结束时,preStop hook还在执行,grace period会自动延长2秒钟。Grace period可以通过terminationGracePeriodSeconds配置。 - 当preStop hook完成时,kubelet会通知Docker运行时停止pod内的所有容器。Docker守护进程会发送SIGTERM信号给容器内的PID 1进程。所有容器收到信号的顺序是随机的。
- 在优雅结束开始的同时,kube-controller-manager会把pod从endpoints(参考Kubernetes – Endpoints)中移除,此时Service会停止往这个pod转发流量;
- 在grace period计时结束后,kubelet会强制停止容器 - Docker会发送SIGKILL信号给pod里面所有容器内的所有进程,此时进程不再有机会正常完成它们的操作,而是会被直接结束;
kubelettriggers deletion of the pod from the API server- Kubelet发送删除pod的请求给API server;
- API server 把pod对应的记录从etcd中删除。

这里有两个问题:
- Nginx和PHP-FPM把SIGTERM信号当作强制结束信号,并且会立刻结束进程,不再处理当前的连接而是立即关闭(参考 Controlling nginx 和 php-fpm(8) - Linux man page)
- 第2和第3步,也就是发送SIGTERM信号和移除endpoint是同时进行的,但实际上Ingress Controller可能没那么快就能够更新endpoints的数据,pod被kill掉时,ingress可能还在往pod转发流量,此时就会导致502错误的发生
例如,当Nginx主进程正在fast shutdown时,我们往nginx发送一个连接请求,nginx会直接丢弃这个连接请求,而我们的客户端则会接收到一个502错误,参考Avoiding dropped connections in nginx containers with “STOPSIGNAL SIGQUIT”。
NGINX STOPSIGNAL 和 502
好了,现在我们已经有了大概的了解,让我们开始来重现第一个问题。
以下的例子参考了上面的文档,并部署到kubernetes集群中。
准备好Dockerfile:
FROM nginx RUN echo 'server {\n\ listen 80 default_server;\n\ location / {\n\ proxy_pass http://httpbin.org/delay/10;\n\ }\n\ }' > /etc/nginx/conf.d/default.conf CMD ["nginx", "-g", "daemon off;"]
在这里,nginx会把请求转发给http://httpbin.org并延迟10秒钟以模仿后端PHP应用。
构建一个镜像并推送到镜像仓库:
$ docker build -t setevoy/nginx-sigterm .
$ docker push setevoy/nginx-sigterm
现在,用这个镜像部署一个有10给实例的Deployment。
下面这个清单包括了Namespace, Service和Ingress,在接下来的测试中不再重复,只会提及需要更新的部分。
--- apiVersion: v1 kind: Namespace metadata: name: test-namespace --- apiVersion: apps/v1 kind: Deployment metadata: name: test-deployment namespace: test-namespace labels: app: test spec: replicas: 10 selector: matchLabels: app: test template: metadata: labels: app: test spec: containers: - name: web image: setevoy/nginx-sigterm ports: - containerPort: 80 resources: requests: cpu: 100m memory: 100Mi readinessProbe: tcpSocket: port: 80 --- apiVersion: v1 kind: Service metadata: name: test-svc namespace: test-namespace spec: type: NodePort selector: app: test ports: - protocol: TCP port: 80 targetPort: 80 --- apiVersion: extensions/v1beta1 kind: Ingress metadata: name: test-ingress namespace: test-namespace annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]' spec: rules: - http: paths: - backend: serviceName: test-svc servicePort: 80
部署:
$ kubectl apply -f test-deployment.yaml namespace/test-namespace created deployment.apps/test-deployment created service/test-svc created ingress.extensions/test-ingress created
检查Ingress:
$ curl -I aadca942-testnamespace-tes-5874–698012771.us-east-2.elb.amazonaws.com HTTP/1.1 200 OK
现在有10个 pods在运行:
$ kubectl -n test-namespace get pod NAME READY STATUS RESTARTS AGE test-deployment-ccb7ff8b6–2d6gn 1/1 Running 0 26s test-deployment-ccb7ff8b6–4scxc 1/1 Running 0 35s test-deployment-ccb7ff8b6–8b2cj 1/1 Running 0 35s test-deployment-ccb7ff8b6-bvzgz 1/1 Running 0 35s test-deployment-ccb7ff8b6-db6jj 1/1 Running 0 35s test-deployment-ccb7ff8b6-h9zsm 1/1 Running 0 20s test-deployment-ccb7ff8b6-n5rhz 1/1 Running 0 23s test-deployment-ccb7ff8b6-smpjd 1/1 Running 0 23s test-deployment-ccb7ff8b6-x5dc2 1/1 Running 0 35s test-deployment-ccb7ff8b6-zlqxs 1/1 Running 0 25s
为Yandex.Tank准备好load.yaml:
phantom: address: aadca942-testnamespace-tes-5874-698012771.us-east-2.elb.amazonaws.com header_http: "1.1" headers: - "[Host: aadca942-testnamespace-tes-5874-698012771.us-east-2.elb.amazonaws.com]" uris: - / load_profile: load_type: rps schedule: const(100,30m) ssl: false console: enabled: true telegraf: enabled: false package: yandextank.plugins.Telegraf config: monitoring.xml
这里,我们会以每秒一次的速率请求Ingress后端的pods。
开始测试:
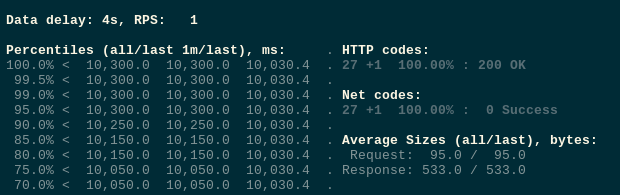
到目前为止一切正常。
现在,把Deployment缩容到一个实例:
$ kubectl -n test-namespace scale deploy test-deployment — replicas=1 deployment.apps/test-deployment scaled
Pods状态变成Terminating:
$ kubectl -n test-namespace get pod NAME READY STATUS RESTARTS AGE test-deployment-647ddf455–67gv8 1/1 Terminating 0 4m15s test-deployment-647ddf455–6wmcq 1/1 Terminating 0 4m15s test-deployment-647ddf455-cjvj6 1/1 Terminating 0 4m15s test-deployment-647ddf455-dh7pc 1/1 Terminating 0 4m15s test-deployment-647ddf455-dvh7g 1/1 Terminating 0 4m15s test-deployment-647ddf455-gpwc6 1/1 Terminating 0 4m15s test-deployment-647ddf455-nbgkn 1/1 Terminating 0 4m15s test-deployment-647ddf455-tm27p 1/1 Running 0 26m …
此时,我们收到了502报错:

现在,我们更新一下Dockerfile - 添加STOPSIGNAL SIGQUIT:
FROM nginx RUN echo 'server {\n\ listen 80 default_server;\n\ location / {\n\ proxy_pass http://httpbin.org/delay/10;\n\ }\n\ }' > /etc/nginx/conf.d/default.conf STOPSIGNAL SIGQUIT CMD ["nginx", "-g", "daemon off;"]
构建并推送镜像:
$ docker build -t setevoy/nginx-sigquit .
docker push setevoy/nginx-sigquit
更新Deployment中的镜像:
... spec: containers: - name: web image: setevoy/nginx-sigquit ports: - containerPort: 80 ...
重新部署并测试:
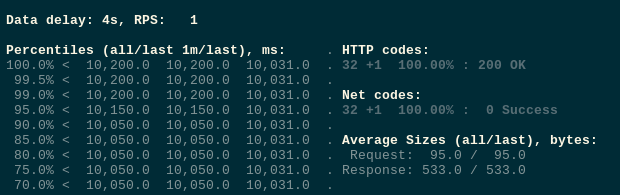
再次对deployment进行缩容:
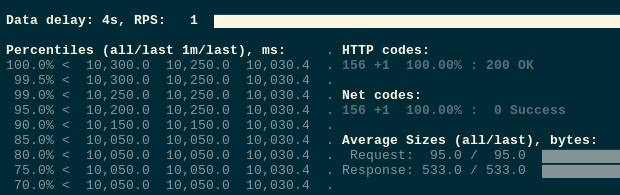
$ kubectl -n test-namespace scale deploy test-deployment — replicas=1 deployment.apps/test-deployment scaled
这次不再报错:
Traffic, preStop, 和 sleep
但其实,如果我们重复测试的话,有时还是会有502错误:

这时,我们应该是遇到了第二个问题 - endpoints更新和SIGTERM同步发生的问题。
让我们加一个sleep的preStop hook,在集群接收到停止pod的请求之后,kubelet会先等待5秒钟后才发送SIGTERM信号,留一些冗余时间以更新endpoints和Ingress。
... spec: containers: - name: web image: setevoy/nginx-sigquit ports: - containerPort: 80 lifecycle: preStop: exec: command: ["/bin/sleep","5"] ...
重新测试,这一次不再有错误了。
我们的PHP-FPM没有这个问题,因为它原本的镜像就已经添加了 STOPSIGNAL SIGQUIT。
其它可能的解决方案
当然,在调试期间我尝试了一些其它的方法。
具体请参考本文最后的参考文献,这里我只做简单的介绍。
preStop 和 nginx -s quit
其中一个方法就是在preStop hook中发送QUIT信号给Nginx:
lifecycle: preStop: exec: command: - /usr/sbin/nginx - -s - quit
或:
... lifecycle: preStop: exec: command: - /bin/sh - -SIGQUIT - 1 ....
然并卵。虽然这个主意(在kubelet/docker发送TERM信号之情,先发送QUIT信号给nginx进程优雅结束)看上去没什么问题,但不知为啥不行。
你可以尝试通过strace看看nginx是否真的接收到QUIT信号了。
NGINX + PHP-FPM, supervisord, 和 stopsignal
我们这个应用是在一个pod里面运行两个容器,我也尝试过使用单个容器运行Nginx + PHP-FPM,例如 trafex/alpine-nginx-php7。
使用这个镜像并在supervisor.conf文件中给Nginx和PHP-FPM配置stopsignal sigquit,虽然想法看起来是对的,结果也是不行。
有兴趣的朋友可以试试。
PHP-FPM, 和 process_control_timeout
在 Graceful shutdown in Kubernetes is not always trivial 和 Stackoveflow 上的 Nginx / PHP FPM graceful stop (SIGQUIT): not so graceful 中提到,FPM’s master 进程先于子进程被杀也会导致502错误。
虽然这不是我们讨论的问题,但你可以关注 process_control_timeout.
NGINX, HTTP, 和keep-alive session
还有,在http头中加入 [Connection: close] 也是个不错的主意,这样子客户端就会在一个请求完成后关闭连接,从而减少502的发生。
但始终还是不能完全避免nginx在处理请求时接收到SIGTERM导致的问题。
参考 HTTP persistent connection.
参考文献
- Graceful shutdown in Kubernetes is not always trivial (перевод на Хабре)
- Gracefully Shutting Down Pods in a Kubernetes Cluster — the
nginx -s quitin thepreStopsolution, also there is a good description of the issue with the traffic being sent to terminated pods - Kubernetes best practices: terminating with grace
- Termination of Pods
- Kubernetes’ dirty endpoint secret and Ingress
- Avoiding dropped connections in nginx containers with “STOPSIGNAL SIGQUIT” — actually, here I’ve found our solution plus an idea of how to reproduce it
Originally published at RTFM: Linux, DevOps and system administration.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号