缓存和数据库之间的数据一致性
1. 什么是缓存?
缓存就是数据交换的缓冲区(称作Cache),是存贮数据(使用频繁的数据)的临时地方。当用户查询数据,首先在缓存中寻找,如果找到了则直接执行。如果找不到,则去数据库中查找。
2. 为什么要用缓存?
缓存的本质就是用空间换时间,牺牲数据的实时性,以服务器内存中的数据暂时代替从数据库读取最新的数据,减少数据库IO,减轻服务器压力,减少网络延迟,加快页面打开速度。
3. 缓存的种类
a.文件缓存
文件缓存是把一些需要高速存取的变量缓存在内存中。模板引擎用的就是文件缓存机制,把动态代码编译成静态文件放入硬盘,不用每次访问都编译,直接读出即可。
b.浏览器缓存
浏览器缓存根据一套与服务器约定的规则进行工作,在同一个会话过程中会检查一次并确定缓存的副本足够新。如果在浏览过程中前进或后退时访问到同一个图片,这些图片可以从浏览器缓存中调出而即时显示。
c.数据库缓存
常用的缓存方案有memcached、redis等。把经常需要从数据库查询的数据、或经常更新的数据放入到缓存中,这样下次查询时,直接从缓存直接返回,减轻数据库压力,提升数据库性能。
d. Web应用层缓存
应用层缓存指的是从代码层面上,通过代码逻辑和缓存策略,实现对数据、页面、图片等资源的缓存,可以根据实际情况选择将数据存在文件系统或者内存中,减少数据库查询或者读写瓶颈,提高响应效率。
e.服务器缓存
包括代理服务器缓存和CDN缓存。
4.导致数据不一致的原因
a.并发的场景下,导致读取老的 DB 数据,更新到缓存中。
b.缓存和 DB 的操作,不在一个事务中,可能只有一个操作成功,而另一个操作失败,导致不一致。
5.常见的数据保存方式
a.先更新缓存,后更新数据库
如果缓存更新成功,数据库更新失败,此时用户读取数据,仍然是从缓存中读取,读到的是数据最新值;但是过了一段时间缓存失效后,此时再读取数据就需要从数据库中读取,而之前数据库更新失败所以存的仍是旧值,并且重新写到缓存中也是旧值。这就导致用户发现自己修改的数据又变回去了,无疑会对业务造成影响!
b.先更新数据库,后更新缓存
如果数据库更新成功,缓存更新失败,那么此时数据库中是「新值」,缓存中是「旧值」。之后的请求仍然会先读取缓存获得「旧值」,缓存失效后再读取数据库的「新值」。这就导致用户刚修改的数据却看不到变更,过一段时间才能看到,同样会对业务造成影响!
c.先删除缓存,后更新数据库
如果缓存删除成功,数据库更新失败。用户读取数据时,缓存中为空,只能去数据库读取数据。但由于数据库更新失败,所以用户读取到的是旧的数据。
d.先更新数据库,后删除缓存
如果数据库更新成功,缓存删除失败。用户读取数据时会先从缓存中读取,而缓存中存储的是旧的数据。如果缓存中的数据没有失效时间,用户就会一直读取旧的数据!
6.如何解决
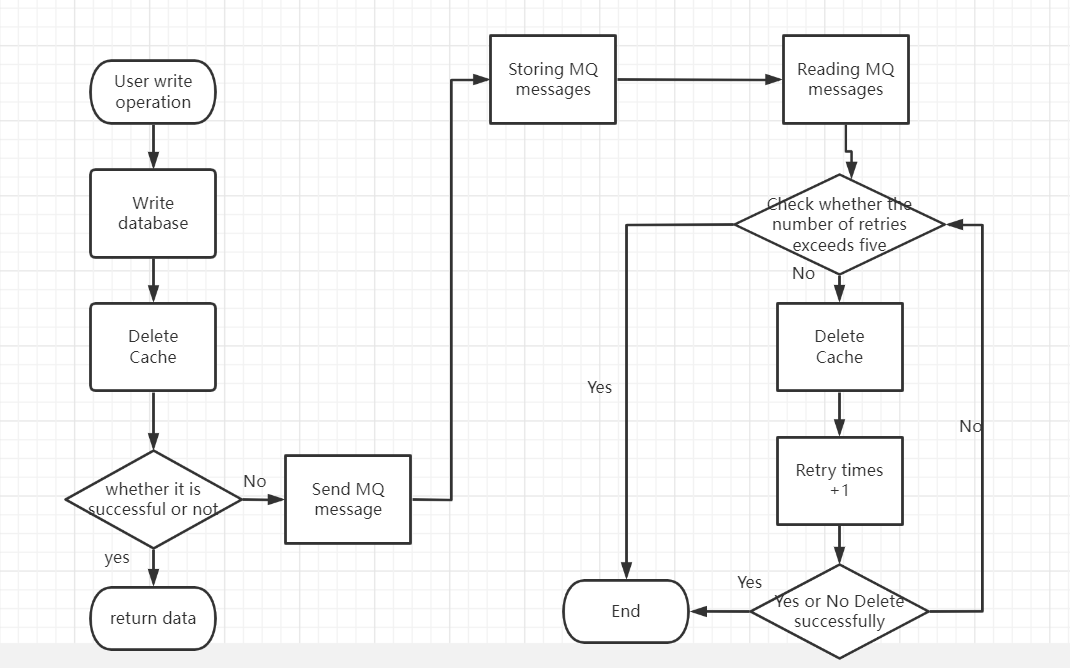
a.消息队列
采取异步重试把重试请求写到消息队列中,然后由专门的消费者来重试,直到成功。
消息队列保证可靠性:写到队列中的消息,成功消费之前不会丢失(重启项目也不担心)。
消息队列保证消息成功投递:下游从队列拉取消息,成功消费后才会删除消息,否则还会继续投递消息给消费者(符合我们重试的场景)。
b. binlog
订阅数据库变更日志(binlog),再操作缓存。当一条数据发生修改时,MySQL 就会产生一条变更日志(binlog),我们可以订阅这个日志,拿到具体操作的数据,然后再根据这条数据,去删除对应的缓存。
1.在业务接口中写数据库之后,直接返回成功。
2.mysql服务器会自动把变更的数据写入binlog中。
3.binlog订阅者(消费者)获取变更的数据,然后删除缓存。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号