
python读取文件时出现多余的\ufeff时的解决方法及原因
当使用python读取文件后打印结果意外多出了一个\ufeff,如图:
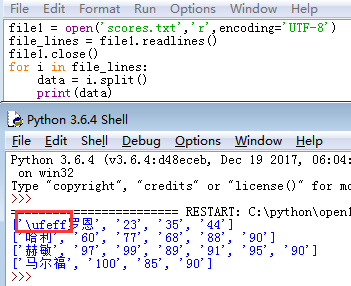
那要如何解决呢?其实也很简单只要将encoding = 'utf-8' 改成encoding = 'UTF-8-sig'就搞定了,如图:
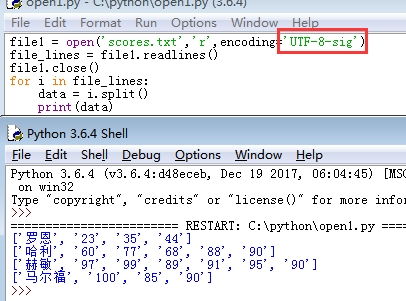
问题是解决了,但是这到底是什么原因呢?
答:在编写文本时保存时包含了BOM(Byte Order Mark,字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码)导致最后输出了\ufeff。
2、utf-8与utf-8-sig两种编码格式有什么区别呢?
答:UTF-8以字节为编码单元,它的字节顺序在所有系统中都是一様的,没有字节序的问题,也因此它实际上并不需要BOM(“ByteOrder Mark”)。但是UTF-8 with BOM即utf-8-sig需要提供BOM。
3、\ufeff到底是什么?
答:字节顺序标记(英语:byte-order mark,BOM)是位于码点U+FEFF的统一码字符的名称。当以UTF-16或UTF-32来将UCS/统一码字符所组成的字符串编码时,这个字符被用来标示其字节序。
它常被用来当做标示文件是以UTF-8、UTF-16或UTF-32编码的记号。

