
解析XML
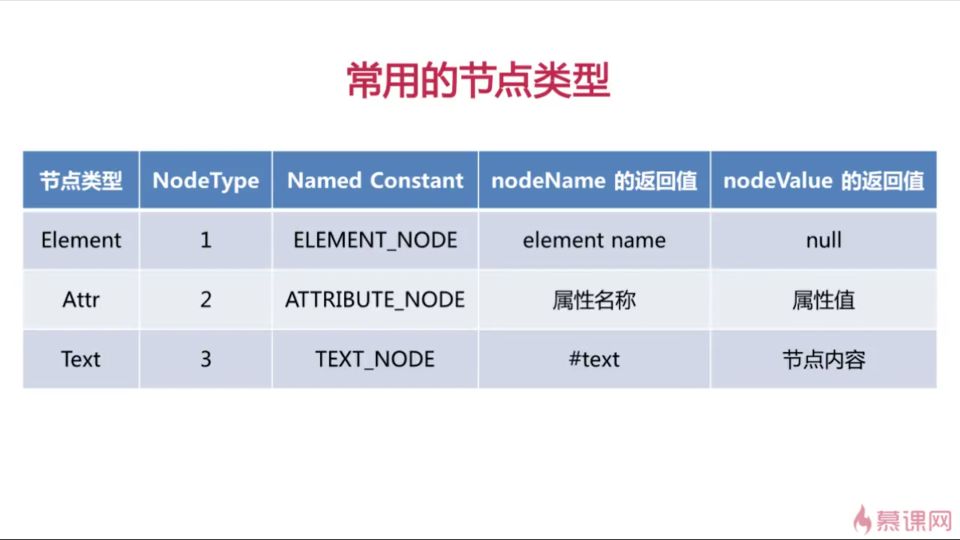
Java会把开始和结束标签中的所有内容看成这个节点的子节点,文字类型的节点就会看成Text类型的节点,带标签的节点就会看出Element类型节点。所以空白和换行看成了一个子节点。
package com.wyl.parseXml; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.NamedNodeMap; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; /** 1.创建一个DocumentBuilderFactory对象 * 2.创建一个DocumentBuilder对象 * 3.通过DocumentBuilder对象的parse(String fileName)方法解析xml文件 * * * 节点类型:Element,Attr,Text * java程序在解析xml文档的时候会把myuser节点开始到结束中的所有类容都看成myuser的子节点。 * 文字类型的会看出Text节点(空白和换行都当成了子节点)。带标签的会看成Element节点。 * * * 为什么所有element类型的节点getNodeValue()是null? * 因为它只看节点标签,认为节点标签就是NodeName。而值是这个节点的子节点,所以说就要获取孙子节点的值 */ public class DOMTest { public static void main(String[] args) { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();//创建一个DocumentBuilderFactory的对象 try { DocumentBuilder db = dbf.newDocumentBuilder();//创建一个DocumentBuilder的对象 Document document = db.parse("user.xml");//通过DocumentBuilder的parse方法加载user.xml文件。 NodeList myuserList = document.getElementsByTagName("myuser");//解析是通过实际的加载了user.xml文件的Document对象解析的。获取所有myuser节点的集合 System.out.println("myuser节点的个数:"+myuserList.getLength()); //遍历每一个myuser节点 for (int i = 0; i < myuserList.getLength(); i++) { System.out.println("======================第"+(i+1)+"层节点开始======================"); //通过 item(i)获取一个myuser节点 Node myuser = myuserList.item(i);//Node接收一下item的返回值 /*1.解析节点的属性名和属性值*/ //遍历myuser的属性 NamedNodeMap attrs = myuser.getAttributes();//获取的就是myuser节点中所有的属性值。NamedNodeMap存储所有myuser属性的集合 System.out.println("第"+(i+1)+"层的节点的属性的个数是:"+attrs.getLength()); for (int j = 0; j < attrs.getLength(); j++) { System.out.println(" 第"+(i+1)+"层的第"+(j+1)+"个节点的属性名和属性值的开始"); Node attr = attrs.item(j); String name = attr.getNodeName(); String value = attr.getNodeValue(); System.out.println(" 第"+(i+1)+"层的第"+(j+1)+"个节点的节点名是:"+name+" 节点值是:"+value); System.out.println(" 第"+(i+1)+"层的第"+(j+1)+"个节点的属性名和属性值的结束"); } /*1.解析节点的节点名和节点值*/ //解析myuser节点的子节点 NodeList childNodes = myuser.getChildNodes(); //遍历childNodes获取每个节点的节点名和节点值 System.out.println("&&&&&第"+(i+1)+"层节点的子节点个数:"+childNodes.getLength()); for (int j = 0; j < childNodes.getLength(); j++) { //区分出text类型的node以及element类型的node if(childNodes.item(j).getNodeType() == Node.ELEMENT_NODE) { Node element = childNodes.item(j); String childNodeName = element.getNodeName(); String childNodeValue = element.getFirstChild().getNodeValue(); // String childNodeValue = element.getTextContent(); System.out.println("*****&&&&&^^^^^^"+childNodeName); System.out.println("*****&&&&&^^^^^^"+childNodeValue); } } /*2.解析节点的属性名和属性值*/ //知道节点属性的名字 /*Element myuser = (Element) myuserList.item(i); String attrValue = myuser.getAttribute("id"); System.out.println("id属性的属性值为"+attrValue);*/ System.out.println("======================第"+(i+1)+"层节点结束======================"); } } catch (ParserConfigurationException e) { e.printStackTrace(); } catch (SAXException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号