Go语言-Slice详解
Go语言中的slice表示一个具有相同类型元素的可变长序列,语言本身提供了两个操作方法:
- 创建:make([]T,len,cap)
- 追加: append(slice, T ...)
同时slice支持随机访问。本篇文章主要对slice的具体实现进行总结。
1. 数据结构
go语言的slice有三个主要的属性:
- 指针:slice的首地址指针
- 长度:slice中元素的个数
- 容量:由于slice底层结构本身物理空间可能更大,因此该值记录slice实际空间大小。
因此,在golang官网中的Go Slices: usage and internals对slice的描述如下:
A slice is a descriptor of an array segment. It consists of a pointer to the array, the length of the segment, and its capacity (the maximum length of the segment).
slice是一段array,包括了上面的三个部分,他的物理结构如下:

如果我们通过make([]byte,5,5)创建了一个len=5,cap=5的slice,其物理结构如此:
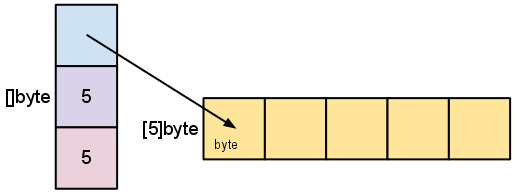
如果我们仅仅想使用原数组的一部分,例如:
s = s[2:4]
则s的物理结构如此:

但实际上,这两者所引用的是同一块连续的空间,如果我们修改其中一个,另一个也会跟着修改。实际上,slice在go语言中的代码表示为:
type slice struct {
array unsafe.Pointer
len int
cap int
}
我们是如何知道这件事的呢?请看继续阅读该文章。
操作
go语言为slice提供了两个修改类操作:
- 创建
- 追加
接下来我们会对这两个操作进行分析。
1. 创建slice
slice的定义(分配空间)有三种方式:
- 字面量创建:
s := []int{1,2,3} - 内置函数make创建:
make([]T, len, cap) - 切取其他数据结构:
s := array[1:2]
还有两种声明方式(不分配空间):
var s []ints := []int{}
接下来我们通过一组示例代码,查看slice的创建流程,以及上面的定义与声明的区别。
-
字面量创建方式
// main.go package main import "fmt" func main() { s1 := []int{1,2,3} fmt.Println(s1) }这组代码给出了一个通过字面量方式创建的slice
s1,我们通过delve工具对这部分代码进行debug。命令行进入到main.go所在目录,键入如下命令:dlv debug # 为main包的main函数第1行即文件第7行打上断点 b main.go:7 # 运行到断点处 c # 对要运行的部分进行反汇编 disassemble我们就可以看到如下代码:
TEXT main.main(SB) D:/code/Notes/docs/go/list/main.go main.go:6 0x948300 493b6610 cmp rsp, qword ptr [r14+0x10] main.go:6 0x948304 0f86f5000000 jbe 0x9483ff main.go:6 0x94830a 4883ec78 sub rsp, 0x78 main.go:6 0x94830e 48896c2470 mov qword ptr [rsp+0x70], rbp main.go:6 0x948313 488d6c2470 lea rbp, ptr [rsp+0x70] => main.go:7 0x948318* 488d05a1940000 lea rax, ptr [rip+0x94a1] main.go:7 0x94831f 90 nop # 调用runtime的newobject创建一个新的对象 main.go:7 0x948320 e81b53f6ff call $runtime.newobject # 将调用结果(即新slice的地址)存到栈顶中 main.go:7 0x948325 4889442428 mov qword ptr [rsp+0x28], rax # 把1放入slice中 main.go:7 0x94832a 48c70001000000 mov qword ptr [rax], 0x1 # 从栈顶将slice的地址取出放入rcx寄存器中 main.go:7 0x948331 488b4c2428 mov rcx, qword ptr [rsp+0x28] main.go:7 0x948336 8401 test byte ptr [rcx], al # 把2放入slice中 main.go:7 0x948338 48c7410802000000 mov qword ptr [rcx+0x8], 0x2 main.go:7 0x948340 488b4c2428 mov rcx, qword ptr [rsp+0x28] main.go:7 0x948345 8401 test byte ptr [rcx], al # 把3放入slice中 main.go:7 0x948347 48c7411003000000 mov qword ptr [rcx+0x10], 0x3 main.go:7 0x94834f 488b4c2428 mov rcx, qword ptr [rsp+0x28] main.go:7 0x948354 8401 test byte ptr [rcx], al main.go:7 0x948356 eb00 jmp 0x948358 # 最后设置slice的指针,并将len和cap都设置为3 main.go:7 0x948358 48894c2440 mov qword ptr [rsp+0x40], rcx main.go:7 0x94835d 48c744244803000000 mov qword ptr [rsp+0x48], 0x3 main.go:7 0x948366 48c744245003000000 mov qword ptr [rsp+0x50], 0x3由此可见,使用字面量创建slice时,len和cap都会设置为初始化数据的个数。
可以简单看一下刚才使用的
runtime.newobject(),该函数在runtime/malloc.go文件中,代码如下:func newobject(typ *_type) unsafe.Pointer { return mallocgc(typ.size, typ, true) }本质上还是通过内存管理机制为一个对象申请一块连续空间并返回对应指针。
-
make函数创建:
// main.go package main import "fmt" func main() { s := make([]int, 10,20) fmt.Println(s) }该例子使用make方式创建了slice
s,其len=10,cap=20,同样使用delve进行debug,脚本同上,我们得到的反汇编结果如下:TEXT main.main(SB) D:/code/Notes/docs/go/list/main.go main.go:6 0xea8300 493b6610 cmp rsp, qword ptr [r14+0x10] main.go:6 0xea8304 0f86cb000000 jbe 0xea83d5 main.go:6 0xea830a 4883ec70 sub rsp, 0x70 main.go:6 0xea830e 48896c2468 mov qword ptr [rsp+0x68], rbp main.go:6 0xea8313 488d6c2468 lea rbp, ptr [rsp+0x68] => main.go:7 0xea8318* 488d0541840000 lea rax, ptr [rip+0x8441] main.go:7 0xea831f bb0a000000 mov ebx, 0xa main.go:7 0xea8324 b914000000 mov ecx, 0x14 # 调用runtime.makeslice函数创建slice(其实也只是创建了一个指针) main.go:7 0xea8329 e8b244faff call $runtime.makeslice # 为创建好的对象设置起始指针,len和cap main.go:7 0xea832e 4889442438 mov qword ptr [rsp+0x38], rax main.go:7 0xea8333 48c74424400a000000 mov qword ptr [rsp+0x40], 0xa main.go:7 0xea833c 48c744244814000000 mov qword ptr [rsp+0x48], 0x14可以看到,这里不再使用
runtime.newobject()创建对象了,而是通过runtime.mallocslice()方法,该方法在runtime/slice.go文件中,源码如下:func makeslice(et *_type, len, cap int) unsafe.Pointer { // 计算一下要申请的空间大小 mem, overflow := math.MulUintptr(et.size, uintptr(cap)) // 并判断len和cap是否合理 if overflow || mem > maxAlloc || len < 0 || len > cap { // NOTE: Produce a 'len out of range' error instead of a // 'cap out of range' error when someone does make([]T, bignumber). // 'cap out of range' is true too, but since the cap is only being // supplied implicitly, saying len is clearer. // See golang.org/issue/4085. mem, overflow := math.MulUintptr(et.size, uintptr(len)) if overflow || mem > maxAlloc || len < 0 { panicmakeslicelen() } panicmakeslicecap() } // 最后还是要靠刚才的方法申请空间返回指针 return mallocgc(mem, et, true) }不过从这里可以看到,slice底层物理空间的大小不是无限分配的,而是有上限的,其上限就是
maxAlloc,该值的大小依赖于heapAddrBites,而heapAddrBites与操作系统有关。maxAlloc = (1 << heapAddrBits) - (1-_64bit)*1 -
切取其他数据结构
// main.go package main import "fmt" func main() { s := [4]int{1,2,3,4} s3 := s[1:] fmt.Println(s3) }该例子通过数组s创建了其slice
s3,并且内容为s的第2条和第三条数据,len=2。这里反汇编一下,看一下结果:main.go:6 0xdc8318 488d05a1940000 lea rax, ptr [rip+0x94a1] main.go:6 0xdc831f 90 nop # 为数组s分配空间 main.go:6 0xdc8320 e81b53f6ff call $runtime.newobject # 为数组s填充数据 main.go:6 0xdc8325 4889442428 mov qword ptr [rsp+0x28], rax main.go:6 0xdc832a 48c70001000000 mov qword ptr [rax], 0x1 main.go:6 0xdc8331 48c7400802000000 mov qword ptr [rax+0x8], 0x2 main.go:6 0xdc8339 48c7401003000000 mov qword ptr [rax+0x10], 0x3 main.go:6 0xdc8341 48c7401804000000 mov qword ptr [rax+0x18], 0x4 => main.go:7 0xdc8349* 488b4c2428 mov rcx, qword ptr [rsp+0x28] main.go:7 0xdc834e 8401 test byte ptr [rcx], al main.go:7 0xdc8350 eb00 jmp 0xdc8352 main.go:7 0xdc8352 eb00 jmp 0xdc8354 main.go:7 0xdc8354 488d5108 lea rdx, ptr [rcx+0x8] # 为切片设置起始地址以及len和cap main.go:7 0xdc8358 4889542440 mov qword ptr [rsp+0x40], rdx main.go:7 0xdc835d 48c744244802000000 mov qword ptr [rsp+0x48], 0x2 main.go:7 0xdc8366 48c744245003000000 mov qword ptr [rsp+0x50], 0x3这个例子有两个点要注意:
- slice s3的cap(容量)是3,也就是是
原始容量减去slice起始值,这里需要特别注意 - 这个例子中slice s3没有被在内存中分配指针,而是在栈中分配的,这个点有待考察。
- slice s3的cap(容量)是3,也就是是
-
两种声明方式
// main.go package main import "fmt" func main() { var s4 []int s5 := []int{} fmt.Println(s4) fmt.Println(s5) }该例子实现了对slice的两种声明方式,首先查看第7行于第9行的汇编代码:
# 将slice的起始地址设置为0 main.go:7 0xe58326 48c744246800000000 mov qword ptr [rsp+0x68], 0x0 main.go:7 0xe5832f 440f117c2470 movups xmmword ptr [rsp+0x70], xmm15 main.go:9 0xe58350 440f117c2440 movups xmmword ptr [rsp+0x40], xmm15 main.go:9 0xe58356 488d542440 lea rdx, ptr [rsp+0x40] main.go:9 0xe5835b 4889542430 mov qword ptr [rsp+0x30], rdx # 取出连续的三个空间 main.go:9 0xe58360 488b442468 mov rax, qword ptr [rsp+0x68] main.go:9 0xe58365 488b5c2470 mov rbx, qword ptr [rsp+0x70] main.go:9 0xe5836a 488b4c2478 mov rcx, qword ptr [rsp+0x78] # 将其转化为slice再进行打印 main.go:9 0xe5836f e80c2af6ff call $runtime.convTslice main.go:9 0xe58374 4889442428 mov qword ptr [rsp+0x28], rax main.go:9 0xe58379 488b7c2430 mov rdi, qword ptr [rsp+0x30] main.go:9 0xe5837e 8407 test byte ptr [rdi], al main.go:9 0xe58380 488d1599750000 lea rdx, ptr [rip+0x7599] main.go:9 0xe58387 488917 mov qword ptr [rdi], rdx main.go:9 0xe5838a 488d5708 lea rdx, ptr [rdi+0x8] main.go:9 0xe5838e 833dbb610f0000 cmp dword ptr [runtime.writeBarrier], 0x0 main.go:9 0xe58395 7402 jz 0xe58399 main.go:9 0xe58397 eb06 jmp 0xe5839f main.go:9 0xe58399 48894708 mov qword ptr [rdi+0x8], rax main.go:9 0xe5839d eb0a jmp 0xe583a9 main.go:9 0xe5839f 4889d7 mov rdi, rdx main.go:9 0xe583a2 e819ccfbff call $runtime.gcWriteBarrier main.go:9 0xe583a7 eb00 jmp 0xe583a9 main.go:9 0xe583a9 488b442430 mov rax, qword ptr [rsp+0x30] main.go:9 0xe583ae 8400 test byte ptr [rax], al main.go:9 0xe583b0 eb00 jmp 0xe583b2 main.go:9 0xe583b2 4889842498000000 mov qword ptr [rsp+0x98], rax main.go:9 0xe583ba 48c78424a000000001000000 mov qword ptr [rsp+0xa0], 0x1 main.go:9 0xe583c6 48c78424a800000001000000 mov qword ptr [rsp+0xa8], 0x1 main.go:9 0xe583d2 bb01000000 mov ebx, 0x1 main.go:9 0xe583d7 4889d9 mov rcx, rbx main.go:9 0xe583da e801abffff call $fmt.Println对于
var s4 []int此类声明,go仅仅是给该对象设置了一个nil指针,真正使用的时候,将其通过runtime.convTslice()转化为slice,再使用。runtime.convTslice()源码如下:func convTslice(val []byte) (x unsafe.Pointer) { // Note: this must work for any element type, not just byte. // 判断起始指针是否为nil,是则返回一个空slice if (*slice)(unsafe.Pointer(&val)).array == nil { x = unsafe.Pointer(&zeroVal[0]) } else { // 否则将内存中的数据给一个新的地址存储 x = mallocgc(unsafe.Sizeof(val), sliceType, true) *(*[]byte)(x) = val } return }这里有一个点需要注意,convTslice()方法中
入参val是一个struct slice{},由此,我们就可以追溯到slice的数据结构是如下模样的:type slice struct { array unsafe.Pointer len int cap int }而对于
s5 := []int{}这种声明方式,其反汇编代码如下:# 通过runtime.zerobase 返回一个默认0值 main.go:8 0xe58335 488d15a4610f00 lea rdx, ptr [runtime.zerobase] main.go:8 0xe5833c 4889542438 mov qword ptr [rsp+0x38], rdx main.go:8 0xe58341 8402 test byte ptr [rdx], al main.go:8 0xe58343 eb00 jmp 0xe58345 # 将其写到s5的位置上 main.go:8 0xe58345 4889542450 mov qword ptr [rsp+0x50], rdx main.go:8 0xe5834a 440f117c2458 movups xmmword ptr [rsp+0x58], xmm15使用s5时也是需要通过
runtime.convTslice()将内存空间中的数据转化为一个slice。可以看到这两种方式都没有真正的分配一块内存,而是只写了一个对象的指针,对于len和cap都没有进行初始化,否则应该有连续三个8字节的块被初始化。
总结一下,通过上面的分析,我们知道针对于5种创建slice的方式,其内部实现逻辑如下:
- 字面量创建:
s := []int{1,2,3},该种方式会调用runtime.newobject实例化一个cap为提供数据个数的连续内存块用于存放数据,本例中为3,创建的slice对象。- 起始指针指向新创建的内存块
- len = len(s)
- cap = len
- 内置函数make创建:
make([]T, len, cap),该方式会通过runtime.makeslice创建一个大小为cap的内存块,然后按照给定的参数将数据写入slice中:- 起始指针指向新创建的内存块
- len = 给定的len
- cap = 给定的cap
- 切取其他数据结构:
s := array[1:2],该方式不会再申请物理内存,而只是创建slice,并修改其值- 起始指针指向被引用数组的被引用起始位置,本例中为array[1]的地址
- len = s中显示指定的长度
- cap = 从被引用起始位置到被引用内存块结束的位置的数据个数
var s []int:赋值nil,使用时转化为slices := []int{}:赋值为nil,使用时转化为slice
2. 随机访问
slice本身支持数据的随机访问,计算机基础知识告诉我们,底层是通过计算目标数据的地址直接访问的,这里我们做实验验证一下,查看如下代码:
// main.go
package main
import "fmt"
func main() {
s := []int{1,2,3,4,5}
s[2] = 10
s[10] = 9
fmt.Println(s)
}
上面的例子创建了一个slice s,并对其第3和第10个元素进行访问,明显前者是正确访问的,后者会导致程序崩溃,我们通过反汇编查看该过程。
main.go:7 0x418318 488d0561950000 lea rax, ptr [rip+0x9561]
main.go:7 0x41831f 90 nop
# 创建slice底层数组,并为其填充数据
main.go:7 0x418320 e81b53f6ff call $runtime.newobject
main.go:7 0x418325 4889442428 mov qword ptr [rsp+0x28], rax
main.go:7 0x41832a 48c70001000000 mov qword ptr [rax], 0x1
main.go:7 0x418331 488b4c2428 mov rcx, qword ptr [rsp+0x28]
main.go:7 0x418336 8401 test byte ptr [rcx], al
main.go:7 0x418338 48c7410802000000 mov qword ptr [rcx+0x8], 0x2
main.go:7 0x418340 488b4c2428 mov rcx, qword ptr [rsp+0x28]
main.go:7 0x418345 8401 test byte ptr [rcx], al
main.go:7 0x418347 48c7411003000000 mov qword ptr [rcx+0x10], 0x3
main.go:7 0x41834f 488b4c2428 mov rcx, qword ptr [rsp+0x28]
main.go:7 0x418354 8401 test byte ptr [rcx], al
main.go:7 0x418356 48c7411804000000 mov qword ptr [rcx+0x18], 0x4
main.go:7 0x41835e 488b4c2428 mov rcx, qword ptr [rsp+0x28]
main.go:7 0x418363 8401 test byte ptr [rcx], al
main.go:7 0x418365 48c7412005000000 mov qword ptr [rcx+0x20], 0x5
main.go:7 0x41836d 488b4c2428 mov rcx, qword ptr [rsp+0x28]
main.go:7 0x418372 8401 test byte ptr [rcx], al
main.go:7 0x418374 eb00 jmp 0x418376
# 创建slice对象
main.go:7 0x418376 48894c2440 mov qword ptr [rsp+0x40], rcx
main.go:7 0x41837b 48c744244805000000 mov qword ptr [rsp+0x48], 0x5
main.go:7 0x418384 48c744245005000000 mov qword ptr [rsp+0x50], 0x5
main.go:8 0x41838d eb00 jmp 0x41838f
# 通过计算s[2]的地址访问s[2]的值
main.go:8 0x41838f 48c741100a000000 mov qword ptr [rcx+0x10], 0xa
=> main.go:9 0x418397* 488b4c2448 mov rcx, qword ptr [rsp+0x48]
main.go:9 0x41839c 488b542440 mov rdx, qword ptr [rsp+0x40]
# 使用索引与s的len比较
main.go:9 0x4183a1 4883f90a cmp rcx, 0xa
# 如果没有问题,则将数据放入slice
main.go:9 0x4183a5 7705 jnbe 0x4183ac
# 索引越界,程序处理出错,跳转到错误处理
main.go:9 0x4183a7 e998000000 jmp 0x418444
main.go:9 0x4183ac 48c7425009000000 mov qword ptr [rdx+0x50], 0x9
通过这部分反汇编代码,我们就可以清楚地看到随机访问的整个过程。
3. 追加
slice本身是可以进行修改的,go提供了append([]T, T...)方法用于岁slice进行数据追加,同时也通过该方法实现了slice的扩容,接下来我们通过下面的例子对slice的追加策略进行探究。
// main.go
package main
import "fmt"
func main() {
s := []int{}
s = append(s, 1)
s = append(s, 2)
s = append(s, 3)
fmt.Println(s)
}
这里为了通用性,我们分析第9行代码s = append(s, 2),因为第8行s = append(s, 1)必定需要扩容,所以不能代表全部情况,现在查看第9行反汇编代码:
main.go:9 0xa58378 488d7302 lea rsi, ptr [rbx+0x2]
main.go:9 0xa5837c 0f1f4000 nop dword ptr [rax], eax
# 比较slice当前cap和需要的容量
main.go:9 0xa58380 4839f1 cmp rcx, rsi
# 如果当前容量够用,直接插入数据
main.go:9 0xa58383 7302 jnb 0xa58387
# 如果当前容量不够用,进行扩容
main.go:9 0xa58385 eb02 jmp 0xa58389
main.go:9 0xa58387 eb27 jmp 0xa583b0
# 扩容代码
main.go:8 0xa58389 48895c2440 mov qword ptr [rsp+0x40], rbx
main.go:9 0xa5838e 4889c3 mov rbx, rax
main.go:9 0xa58391 4889cf mov rdi, rcx
main.go:9 0xa58394 488d05c5830000 lea rax, ptr [rip+0x83c5]
main.go:9 0xa5839b 4889d1 mov rcx, rdx
main.go:9 0xa5839e 6690 data16 nop
main.go:9 0xa583a0 e87b45faff call $runtime.growslice
main.go:9 0xa583a5 488d7301 lea rsi, ptr [rbx+0x1]
main.go:9 0xa583a9 488b5c2440 mov rbx, qword ptr [rsp+0x40]
main.go:9 0xa583ae eb00 jmp 0xa583b0
# 插入新数据代码
main.go:9 0xa583b0 488d14d8 lea rdx, ptr [rax+rbx*8]
main.go:9 0xa583b4 488d5208 lea rdx, ptr [rdx+0x8]
# s = append(s,T),将新的slice放回到原地址中
main.go:9 0xa583b8 48c70202000000 mov qword ptr [rdx], 0x2
main.go:9 0xa583bf 4889442470 mov qword ptr [rsp+0x70], rax
main.go:9 0xa583c4 4889742478 mov qword ptr [rsp+0x78], rsi
main.go:9 0xa583c9 48898c2480000000 mov qword ptr [rsp+0x80], rcx
可以看到,go语言中slice是否需要扩容的判断并不是在go中实现的,而扩容的具体逻辑是runtime.growslice()函数。下面查看runtime.growslice()源码:
// runtime/slice.go
// growslice handles slice growth during append.
// It is passed the slice element type, the old slice, and the desired new minimum capacity,
// and it returns a new slice with at least that capacity, with the old data
// copied into it.
// The new slice's length is set to the old slice's length,
// NOT to the new requested capacity.
// This is for codegen convenience. The old slice's length is used immediately
// to calculate where to write new values during an append.
// TODO: When the old backend is gone, reconsider this decision.
// The SSA backend might prefer the new length or to return only ptr/cap and save stack space.
func growslice(et *_type, old slice, cap int) slice {
...
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
// 1. 计算新slice的容量
// (1) 如果原容量小于256,则是原容量的2倍
const threshold = 256
if old.cap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
// (2)否则每次增加 old.cap/4 + 192
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
// 2. 根据新容量快速算出是否需要多少内存
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For goarch.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == goarch.PtrSize:
lenmem = uintptr(old.len) * goarch.PtrSize
newlenmem = uintptr(cap) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if goarch.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
// The check of overflow in addition to capmem > maxAlloc is needed
// to prevent an overflow which can be used to trigger a segfault
// on 32bit architectures with this example program:
//
// type T [1<<27 + 1]int64
//
// var d T
// var s []T
//
// func main() {
// s = append(s, d, d, d, d)
// print(len(s), "\n")
// }
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
// The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length).
// Only clear the part that will not be overwritten.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// 3. 分配新slice的物理空间
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in old.array since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem-et.size+et.ptrdata)
}
}
// 4. 将旧数据拷贝到新空间中
memmove(p, old.array, lenmem)
// 5. 返回生成的slice
return slice{p, old.len, newcap}
}
通过上面的分析,我们可以看到,slice的扩容策略是:
- 旧slice容量 < 256,则newSlice.cap两倍递增
- 旧slice容量 >= 256,则newSlice.cap = (old.cap + 3 * 256)/4
而且注意,这里产生了一个新的指针,新指针与旧指针指向的位置不同,因此才需要s = append(s, T)。
至此,slice的内容基本分析完毕。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号