
py基础---多线程、多进程、协程
Python基础__线程、进程、协程
1、什么是线程(thread)?
线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位,一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程中并发执行不同的任务。
官方解释:
A thread is an execution context, which is all the information a CPU needs to execute a stream of instructions.
Suppose you're reading a book, and you want to take a break right now, but you want to be able to come back and resume reading from the exact point where you stopped. One way to achieve that is by jotting down the page number, line number, and word number. So your execution context for reading a book is these 3 numbers.
If you have a roommate, and she's using the same technique, she can take the book while you're not using it, and resume reading from where she stopped. Then you can take it back, and resume it from where you were.
Threads work in the same way. A CPU is giving you the illusion that it's doing multiple computations at the same time. It does that by spending a bit of time on each computation. It can do that because it has an execution context for each computation. Just like you can share a book with your friend, many tasks can share a CPU.
On a more technical level, an execution context (therefore a thread) consists of the values of the CPU's registers.
Last: threads are different from processes. A thread is a context of execution, while a process is a bunch of resources associated with a computation. A process can have one or many threads.
Clarification: the resources associated with a process include memory pages (all the threads in a process have the same view of the memory), file descriptors (e.g., open sockets), and security credentials (e.g., the ID of the user who started the process).
2、什么是进程(process)?
一个进程就是一个应用程序,是系统进行资源分配和调度的基本单位,是操作系统结构的基础,在早期面向进程设计的计算机结构中, 进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器,进程是线程的容器,程序是指令、数据以及其组织形式的描述,一个进程包含多个线程。
官方解释:
An executing instance of a program is called a process.
Each process provides the resources needed to execute a program. A process has a virtual address space, executable code, open handles to system objects, a security context, a unique process identifier, environment variables, a priority class, minimum and maximum working set sizes, and at least one thread of execution. Each process is started with a single thread, often called the primary thread, but can create additional threads from any of its threads.
3、进程和线程的区别
- 线程共享创建它的进程的地址空间(每个进程有自己的地址空间)。
- 线程可以直接访问其进程的数据(每个进程拥有自己父进程的数据副本。)
- 线程可以直接与其进程的其他线程通信(每个进程必须使用第三方手段来与兄弟进程进行通信,比如消息队列)
- 新线程很容易创建(创建新的进程需要父进程来创建,子进程是父进程的拷贝)
- 线程可以对同一进程的线程进行相当大的控制(进程只能控制子进程)
- 对主线程的更改(取消、优先级更改等),可能会影响进程的其他线程的行为(对父进程的更改不会影响子进程)
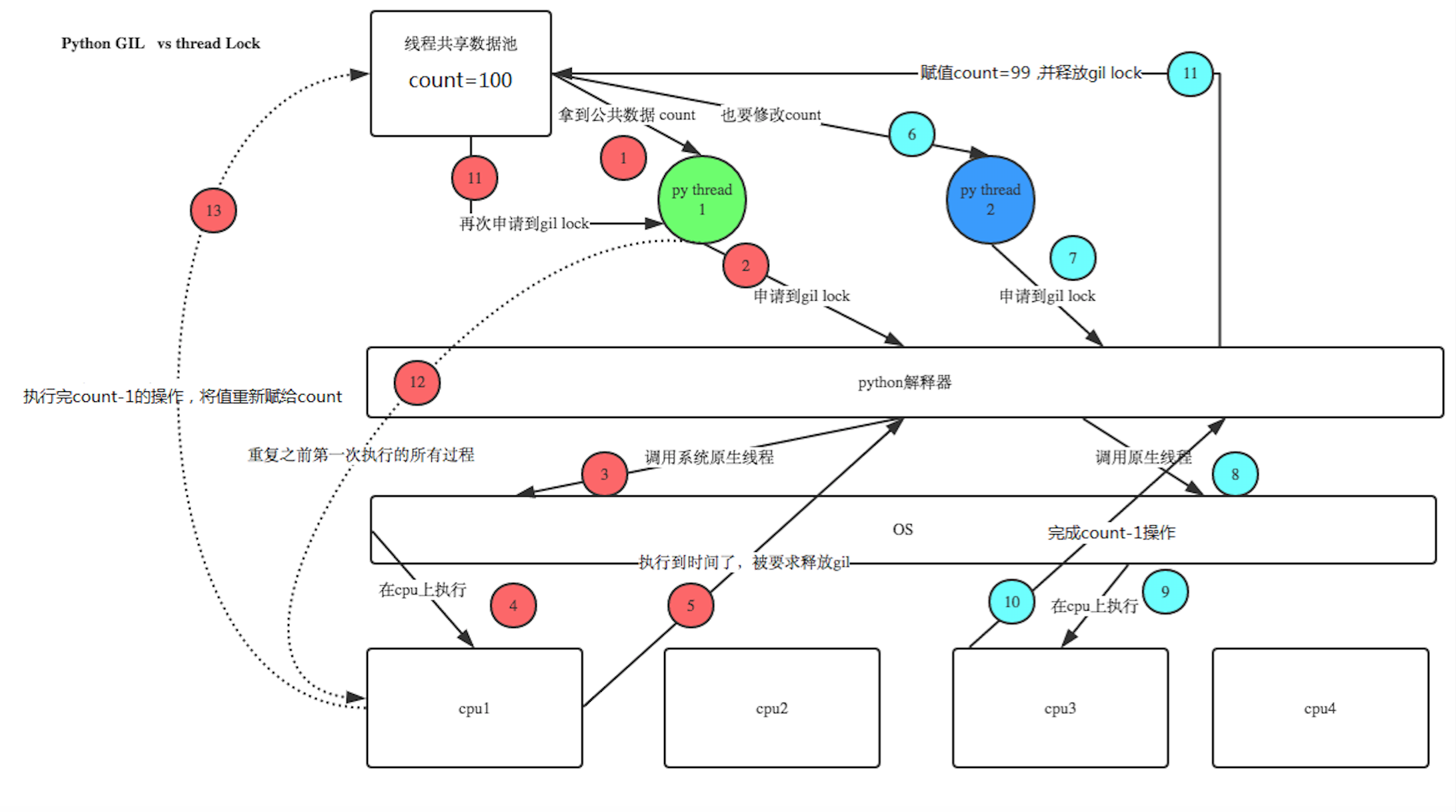
4、GIL全局解释器锁
在python中,一次只能有一个线程在执行,如果想要利用多核多处理器资源,尽量使用多进程去处理。
官方解释:
Cpython实现细节:在Cpython中,由于Global Interpreter Lock,只有一个线程可以同时执行python代码(某些面向性能的库可能会避免这个限制)如果你希望应用程序更好地利用多核机器的计算资源,建议你使用多处理,但是,如果要同时运行多个I/O绑定任务,则线程仍然是一个合适的模型。
总结:所以如果底层python解释器的话,我们python的多线程只适合IO密集型任务,不适合CPU计算密集型任务。
5、多线程(threading模块)
-
模块以及相关方法
threading模块:
threading.Thread(target=?,args=(arg1,arg2...)):
创建threading线程对象,target参数将要运行的函数的变量名填写到这里,args参数是要运行函数需要的参数。
start():让线程开始执行任务
join():默认线程开起来之后就和主线程没有关系了,主线程结束和join没关系,调用join方法,会让主线程再调用join方法的地方等待,知道子线程完成操作,主线程才继续往下执行代码。
setDaemon(True):默认为False,默认主线程与其他线程没有关系,但是有时候,我们想要主线程关闭的时候,把其他线程也关闭了(不关心其他线程是不是执行完任务了),我们将其他线程设置为主线程的守护进程。注意:该方法需要在线程开始之前执行threading.currentThread(): 返回当前的线程变量。
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
run(): 用以表示线程活动的方法。
start():启动线程活动。
join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
isAlive(): 返回线程是否活动的。
getName(): 返回线程名。
setName(): 设置线程名。 -
如何使用threading模块创建多线程
-
直接调用
# author:Dman # date:2019/3/26 import threading import time def foo(n): print('foo___start___%s' % n) time.sleep(1) print('end foo____') def bar(): print('bar___start') time.sleep(2) #time.sleep的时候并不会占用cpu print('end bar____') t1 = threading.Thread(target=foo,args=(2,)) t2 = threading.Thread(target=bar) t1.start() t2.start() print('_________main______') -
使用继承的方式调用
# author:Dman # date:2019/3/27 """ 使用自定义类的方式去创建thread 步骤: 1、继承threading.Thread类 2、必须重写父方法,run()方法。 3、可以重写父类方法 """ import threading import time class Mythred(threading.Thread): def __init__(self,num): # super(Mythred,self).__init__() threading.Thread.__init__(self) self.num = num def run(self): print('threading %s is running at %s ' % (threading.current_thread(), time.ctime())) time.sleep(3) if __name__ == '__main__': t1 = Mythred(1) t2 = Mythred(2) t1.start() t2.start()
-
-
join方法的疑问
# author:Dman # date:2019/3/27 """ threading 中方法,join方法的理解与使用。 join方法 """ import threading from time import ctime,sleep import time def music(func): for i in range(2): print ("Begin listening to %s. %s" %(func,ctime())) sleep(4) print("end listening %s"%ctime()) def move(func): for i in range(2): print ("Begin watching at the %s! %s" %(func,ctime())) sleep(5) print('end watching %s'%ctime()) if __name__ == '__main__': threads = [] t1 = threading.Thread(target=music, args=('七里香',)) threads.append(t1) t2 = threading.Thread(target=move, args=('阿甘正传',)) threads.append(t2) for t in threads: # t.setDaemon(True) t.start() # t.join() #位置1 # t1.join() #位置2 # t2.join()######## #位置3 print ("all over %s" %ctime())总结:
1、位置1:会阻塞所有的子线程,父进程会在所有程序执行完成之后就执行
2、位置2:只会阻塞线程 t1,在 t1子线程执行完毕之后,主线程就会继续执行print函数。
3、位置3:只会阻塞线程 t2,在 t2子线程执行完毕之后,主线程就会继续执行print函数。
-
多线程数据共享和同步
如果多个线程共同对某个数据进行修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步,使用thread类的Lock和RLock可以是实现简单的线程同步。
-
同步锁:又称互斥锁 ------threading.Lock
作用:解决多个线程访问共享变量的时候出现的数据的问题。
# author:Dman # date:2019/3/27 """ 没有同步锁案例 """ """ 下面程序执行顺序: 1、我们打开了100个线程去执行addnum函数,其中addnum是对一个全局变量num进行-1的操作,我们的理想的状态时num左后等于0 实际运行结果是: 100个线程开始抢GIL,抢到的将被CPU执行 1、执行global num 2、temp = num 赋值操作 3、执行time.sleep(0.1) ---(解释:这个语句相当于发生IO阻塞,挂起,GIL释放,下一步num=temp-1还未被执行,因此全局变量num的值仍为 100) 4、其他99个线程开始抢GIL锁,重复上面的步骤 5、其他98个线程开始抢GIL锁,重复上面的步骤 ... (备注:如果阻塞的事件够长,由于cpu的执行速度很快,也就是切换的快,在发生阻塞的0.1秒钟,如果100个 线程都切换一遍那么,每个线程就都拿到num=100这个变量,后面再执行-1操作,那么当所有线程结束,得到的结果都是99.) """ import time import threading def addNum(): global num #在每个线程中都获取这个全局变量 # num-=1 #这个操作速度很快 temp=num # print('--get num:',num) # 每个线程执行到这一步就只能拿到变量num = 100, time.sleep(0.1) num =temp-1 #对此公共变量进行-1操作 if __name__ == '__main__': num = 100 #设定一个共享变量 thread_list = [] for i in range(5): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: #等待所有线程执行完毕 t.join() print('final num:', num ) #------运行结果------- final num: 99![]()
# author:Dman # date:2019/3/28 """ 线程锁使用实例 1、使用threading.Lock()方法得到锁对象 2、在方法中调用acquire()和release()方法去包围我们的代码, 那么同一时刻就只有一个线程可以访问acquire和release包围的代码块。 """ import time import threading def addNum(): global num # 在每个线程中都获取这个全局变量 # num-=1 #这个操作速度很快 lock.acquire() # 获取锁 temp = num # print('--get num:',num) # 每个线程执行到这一步就只能拿到变量num = 100, time.sleep(0.1) num = temp - 1 # 对此公共变量进行-1操作 lock.release() # 释放锁 if __name__ == '__main__': lock = threading.Lock() num = 100 # 设定一个共享变量 thread_list = [] for i in range(100): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: # 等待所有线程执行完毕 t.join() print('final num:', num)思考:同步锁和GIL的区别
总结:
1、线程锁又称互斥锁、同步锁,为了防止多个代码同时访问共享变量的时候,出现问题。
2、在threading模块中,通过Lock类来创建锁对象,通过aquire方法和release方法去包围需要保护的代码
-
线程死锁和递归锁
-
死锁
死锁现象,见代码如下:
# author:Dman # date:2019/3/30 """ 线程死锁: 在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,因为系统判断这部分资源都正在使用,所有这两个线程在无外力作用下将一直等待下去。 """ import threading import threading,time class myThread(threading.Thread): def doA(self): lockA.acquire() print(self.name,"gotlockA",time.ctime()) time.sleep(3) lockB.acquire() # 要求获取LockB print(self.name,"gotlockB",time.ctime()) lockB.release() lockA.release() def doB(self): lockB.acquire() print(self.name,"gotlockB",time.ctime()) time.sleep(2) lockA.acquire() # 要求获取LockA print(self.name,"gotlockA",time.ctime()) lockA.release() lockB.release() def run(self): self.doA() self.doB() if __name__=="__main__": lockA=threading.Lock() lockB=threading.Lock() threads=[] for i in range(5): threads.append(myThread()) for t in threads: t.start() for t in threads: t.join()#等待线程结束,后面再讲。 -
递归锁-----threading.RLock
作用:为了解决锁嵌套的问题,解决死锁问题。
# author:Dman # date:2019/3/30 """ 递归锁(RLock)也叫可重入锁:解决死锁问题,看 线程锁_test3.py 特点:可以多次acquire。 内部使用计数器来维护。acquire的时候计数器加1,release的时候计数器减1 结果:锁的是内部代码块,同一时刻保证只有一个线程执行该代码块。 使用场景:当我们修改多个变量是有关联的,我们只能对自己的方法去锁定,但是不能保证别人的方法是锁定的,所以当我们内部锁定了之后,其他函数也可能锁定,这样就出现了多把锁的情况。 """ import threading import threading,time class myThread(threading.Thread): def doA(self): # lockA.acquire() lock.acquire() print(self.name,"gotlockA",time.ctime()) time.sleep(3) # lockB.acquire() # 要求获取LockB lock.acquire() print(self.name,"gotlockB",time.ctime()) # lockB.release() # lockA.release() lock.release() lock.release() def doB(self): lock.acquire() print(self.name,"gotlockB",time.ctime()) time.sleep(2) lock.acquire() # 要求获取LockA print(self.name,"gotlockA",time.ctime()) lock.release() lock.release() def run(self): self.doA() self.doB() if __name__=="__main__": # lockA=threading.Lock() # lockB=threading.Lock() lock = threading.RLock() threads=[] for i in range(5): threads.append(myThread()) for t in threads: t.start() for t in threads: t.join()#等待线程结束,后面再讲。 -
案例使用案例----银行取钱:
# author:Dman # date:2019/3/30 """ 递归锁场景---案例 """ import threading class Account: def __init__(self,name,money): self.name = name self.balance = money self.lock = threading.RLock() def withdraw(self,amount): with self.lock: self.balance -= amount def deposit(self,amount): with self.lock: # with上下文管理,帮我们acquire 和release self.balance += amount def transfer(from_user, to_user,amount): # 锁不可以加在这里,因为其他的线程执行其他方法在不加锁的情况下数据同样是不安全的 from_user.withdraw(amount) to_user.deposit(amount) if __name__ == '__main__': alex = Account('alex',100) dman = Account('xiaohu',20000) t1 = threading.Thread(target=transfer, args=(alex, dman, 100)) t1.start() t2 = threading.Thread(target=transfer, args=(dman, dman, 200)) t2.start() t1.join() t2.join() print('>>>', alex.balance) print('>>>', dman.balance)总结:
1、创建递归锁的方法:使用threading.RLock类去创建递归锁对象。同互斥锁一样,使用aquire和release方法去包围代码块
2、递归锁是为了解决锁嵌套的时候的问题。
-
-
条件变量同步---threading.Condition
-
作用:为了实现多个线程之间的交互,它本身也提供了RLock或Lock的方法,还提供了wait()、notify()、notifyAll()方法
wait():条件不满足时调用,线程会释放锁并进入等待阻塞;
notify():条件创造后调用,通知等待池激活一个线程;
notifyAll():条件创造后调用,通知等待池激活所有线程。# author:Dman # date:2019/3/30 """ 条件变量------实现线程的限制 应用场景:有一类线程需要满足条件之后才能继续执行。,为了在满足一定条件后,唤醒某个线程,防止该线程一直不被执行 """ import threading,time from random import randint class Producer(threading.Thread): def run(self): global L while True: val=randint(0,100) print('生产者',self.name,":Append"+str(val),L) if lock_con.acquire(): L.append(val) lock_con.notify() # lock_con.release() time.sleep(3) class Consumer(threading.Thread): def run(self): global L while True: lock_con.acquire() # print('ok1') if len(L)==0: lock_con.wait() print('消费者',self.name,":Delete"+str(L[0]),L) del L[0] lock_con.release() time.sleep(0.25) if __name__=="__main__": L=[] lock_con=threading.Condition()#获取一个Condition对象 threads=[] for i in range(5): threads.append(Producer()) threads.append(Consumer()) for t in threads: t.start() for t in threads: t.join()总结:
1、使用threading.Condition()获取一个Condition对象,里面默认使用RLock,也可以自己手动传参数。
-
-
同步条件---threading.Event
-
作用:Event和Condition差不多,只是少了锁的功能,因此Event用于不访问共享变量的条件环境
event.isSet():返回event的状态值;
event.wait():如果 event.isSet()==False将阻塞线程;
event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度;
event.clear():恢复event的状态值为False。
# author:Dman # date:2019/3/30 """ event没有锁功能,但是实现了线程之间的交互。内部有标志位 实现了函数: isSet():返回event 的状态值 wait():如果event的状态值位False将阻塞线程 set(): 设置event的状态值位True clear():设置event的状态值为False 交叉执行。 """ import threading,time class Boss(threading.Thread): def run(self): print("BOSS:今晚大家都要加班到22:00。") event.isSet() or event.set() time.sleep(5) print("BOSS:<22:00>可以下班了。") event.isSet() or event.set() class Worker(threading.Thread): def run(self): event.wait() print("Worker:哎……命苦啊!") time.sleep(0.25) event.clear() event.wait() print("Worker:OhYeah!") if __name__=="__main__": event=threading.Event() #获取event对象 threads=[] for i in range(5): threads.append(Worker()) threads.append(Boss()) for t in threads: t.start() for t in threads: t.join() #---------运行结果--------------- BOSS:今晚大家都要加班到22:00。 Worker:哎……命苦啊! Worker:哎……命苦啊!Worker:哎……命苦啊! Worker:哎……命苦啊! Worker:哎……命苦啊! BOSS:<22:00>可以下班了。 Worker:OhYeah! Worker:OhYeah! Worker:OhYeah!Worker:OhYeah! Worker:OhYeah!
-
-
信号量
-
作用:用来控制线程并发数的,使用BoundedSemaphore或Semaphore类来管理一个内置的计数器,每当调用acquire方法时-1,调用release方法时+1.
计数器不能小于0,当计数器为0时,acquire方法将阻塞线程至同步锁定状态,知道其他线程调用release方法。(类似停车场的概念)
BoundedSemaphore与Semaphore的唯一区别在于前者将调用release时检查计数器是否超过了计数器的初始值,如果超过了将抛出一个异常。
# author:Dman # date:2019/3/30 """ 1、信号量 2、信号量和递归锁的区别: 3、应用场景: 4、信号量的创建: """ import threading,time class MyThread(threading.Thread): def run(self): if semaphore.acquire(): print(self.name) time.sleep(5) semaphore.release() if __name__ =='__main__': semaphore = threading.BoundedSemaphore(5) thrs = [] for i in range(13): thrs.append(MyThread()) for i in thrs: i.start() # print('___main function close _____')
-
-
多线程数据共享利器--queue队列模块
-
作用:多个线程间进行安全的信息交互的时候
queue队列类的方法
创建一个“队列”对象
import Queue
q = Queue.Queue(maxsize = 10)
Queue.Queue类即是一个队列的同步实现。队列长度可为无限或者有限。可通过Queue的构造函数的可选参数maxsize来设定队列长度。如果maxsize小于1就表示队列长度无限。将一个值放入队列中
q.put(10)
调用队列对象的put()方法在队尾插入一个项目。put()有两个参数,第一个item为必需的,为插入项目的值;第二个block为可选参数,默认为
1。如果队列当前为空且block为1,put()方法就使调用线程暂停,直到空出一个数据单元。如果block为0,put方法将引发Full异常。将一个值从队列中取出
q.get()
调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。如果队列为空且block为True,get()就使调用线程暂停,直至有项目可用。如果队列为空且block为False,队列将引发Empty异常。Python Queue模块有三种队列及构造函数:
1、Python Queue模块的FIFO队列先进先出。 class queue.Queue(maxsize)
2、LIFO类似于堆,即先进后出。 class queue.LifoQueue(maxsize)
3、还有一种是优先级队列级别越低越先出来。 class queue.PriorityQueue(maxsize)此包中的常用方法(q = Queue.Queue()):
q.qsize() 返回队列的大小
q.empty() 如果队列为空,返回True,反之False
q.full() 如果队列满了,返回True,反之False
q.full 与 maxsize 大小对应
q.get([block[, timeout]]) 获取队列,timeout等待时间
q.get_nowait() 相当q.get(False)
非阻塞 q.put(item) 写入队列,timeout等待时间
q.put_nowait(item) 相当q.put(item, False)
q.task_done() 在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一个信号
q.join() 实际上意味着等到队列为空,再执行别的操作案例一
# author:Dman # date:2019/3/30 import queue """ 队列 queue:是线程安全的 相比较列表:为什么队列是线程安全的 """ import threading,queue,time,random class Production(threading.Thread): def run(self): while True: r = random.randint(0,100) q.put(r) print('生产出来%s号包子' % r) time.sleep(1) class Proces(threading.Thread): def run(self): while True: re = q.get() print('吃掉%s号包子'% re) if __name__ == '__main__': q = queue.Queue(10) threads = [Production(),Production(),Proces()] for t in threads: t.start()案例二:
# author:Dman # date:2019/4/3 #实现一个线程不断生成一个随机数到一个队列中(考虑使用Queue这个模块) # 实现一个线程从上面的队列里面不断的取出奇数 # 实现另外一个线程从上面的队列里面不断取出偶数 import random,threading,time from queue import Queue #Producer thread class Producer(threading.Thread): def __init__(self, t_name, queue): threading.Thread.__init__(self,name=t_name) self.data=queue def run(self): for i in range(10): #随机产生10个数字 ,可以修改为任意大小 randomnum=random.randint(1,99) print ("%s: %s is producing %d to the queue!" % (time.ctime(), self.getName(), randomnum)) self.data.put(randomnum) #将数据依次存入队列 time.sleep(1) print ("%s: %s finished!" %(time.ctime(), self.getName())) #Consumer thread class Consumer_even(threading.Thread): def __init__(self,t_name,queue): threading.Thread.__init__(self,name=t_name) self.data=queue def run(self): while 1: try: val_even = self.data.get(1,5) #get(self, block=True, timeout=None) ,1就是阻塞等待,5是超时5秒 if val_even%2==0: print ("%s: %s is consuming. %d in the queue is consumed!" % (time.ctime(),self.getName(),val_even)) time.sleep(2) else: self.data.put(val_even) time.sleep(2) except: #等待输入,超过5秒 就报异常 print ("%s: %s finished!" %(time.ctime(),self.getName())) break class Consumer_odd(threading.Thread): def __init__(self,t_name,queue): threading.Thread.__init__(self, name=t_name) self.data=queue def run(self): while 1: try: val_odd = self.data.get(1,5) if val_odd%2!=0: print ("%s: %s is consuming. %d in the queue is consumed!" % (time.ctime(), self.getName(), val_odd)) time.sleep(2) else: self.data.put(val_odd) time.sleep(2) except: print ("%s: %s finished!" % (time.ctime(), self.getName())) break #Main thread def main(): queue = Queue() producer = Producer('Pro.', queue) consumer_even = Consumer_even('Con_even.', queue) consumer_odd = Consumer_odd('Con_odd.',queue) producer.start() consumer_even.start() consumer_odd.start() producer.join() consumer_even.join() consumer_odd.join() print ('All threads terminate!') if __name__ == '__main__': main()案例3:相比较,list不是线程安全的
import threading,time li=[1,2,3,4,5] def pri(): while li: a=li[-1] print(a) time.sleep(1) try: li.remove(a) except: print('----',a) t1=threading.Thread(target=pri,args=()) t1.start() t2=threading.Thread(target=pri,args=()) t2.start()
-
-
6、多进程
-
多进程概念
由于GIL的存在,默认的Cpython解释器中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU资源,在python中大部分需要使用多进程,Python提供了multiprocessing模块,这个模块支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
该模块的使用和threading模块类似,api大致相同,但是需要注意几点:
1、在unix平台上,某个进程终结之后,该进程需要被父进程调用wait,否则进程成为僵尸进程,所以有必要对每个process对象调用join方法(实际上等于wait),对于多线程来说 ,由于只有一个进程,所以不存在此必要性。
2、multiprocessing模块提供了Pipe和Queue,效率上更高,赢优先考虑Pipe和Queue,避免使用Lock、Event等同步方式(因为他们占据的不是进程的资源。)
3、多进程应该避免共享资源,在多线程中,我们可以比较容易的共享资源,比如使用全局变量或者传递参数,在多进程的情况下,由于每个进程有自己独立的内存空间,以上方法不合适。此时我们可以通过共享内存和Manager的方法来共享资源,但这样做提高了程序的复杂度。
4、另外、在windows系统下,需要注意的是想要启动一个子进程,必须加上
if __name__ == '__main__': -
创建多进程------multiprocessing.Process
-
直接调用
from multiprocessing import Process import time def f(name): time.sleep(1) print('hello', name,time.ctime()) if __name__ == '__main__': p_list=[] for i in range(3): p = Process(target=f, args=('alvin',)) p_list.append(p) p.start() for i in p_list: p.join() print('end') -
类的方式调用
from multiprocessing import Process import time class MyProcess(Process): def __init__(self): super(MyProcess, self).__init__() #self.name = name def run(self): time.sleep(1) print ('hello', self.name,time.ctime()) if __name__ == '__main__': p_list=[] for i in range(3): p = MyProcess() p.start() p_list.append(p) for p in p_list: p.join() print('end')
-
-
多进程之间的通信,有三种方式
-
multiprocessing.Queue
from multiprocessing import Process, Queue def f(q,n): q.put([42, n, 'hello']) if __name__ == '__main__': q = Queue() p_list=[] for i in range(3): p = Process(target=f, args=(q,i)) p_list.append(p) p.start() print(q.get()) print(q.get()) print(q.get()) for i in p_list: i.join() -
multiprocessing.Pipe
from multiprocessing import Process, Pipe def f(conn): conn.send([42, None, 'hello']) conn.close() if __name__ == '__main__': parent_conn, child_conn = Pipe() p = Process(target=f, args=(child_conn,)) p.start() print(parent_conn.recv()) # prints "[42, None, 'hello']" p.join()1、Pipe()函数返回一个由管道连接的连接对象,默认情况下是双工(双向)。
2、Pipe()返回的两个连接对象代表管道的两端。 每个连接对象都有send() 和recv()方法(以及其他方法)。 请注意,如果两个进程(或线程)同时尝试读取或写入管道的同一端,则管道中的数据可能会损坏。 当然,同时使用管道的不同端的进程不存在损坏的风险。
-
multiprocessing.Manager
from multiprocessing import Process, Manager def f(d, l,n): d[n] = '1' d['2'] = 2 d[0.25] = None l.append(n) print(l) if __name__ == '__main__': with Manager() as manager: d = manager.dict() l = manager.list(range(5)) p_list = [] for i in range(10): p = Process(target=f, args=(d, l,i)) p.start() p_list.append(p) for res in p_list: res.join() print(d) print(l)1、Manager()返回的管理器对象控制一个服务器进程,该进程保存Python对象并允许其他进程使用代理操作它们。
2、Manager()返回的管理器将支持类型列表,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Barrier,Queue,Value和Array。
-
-
进程间同步----multiprocessing.Lock
from multiprocessing import Process, Lock def f(l, i): l.acquire() try: print('hello world', i) finally: l.release() if __name__ == '__main__': lock = Lock() for num in range(10): Process(target=f, args=(lock, num)).start()进程间同步,只使用父进程的锁,(另外尽量避免这种情况)
-
进程池----multiprocessing.Pool
from multiprocessing import Process,Pool import time def Foo(i): time.sleep(2) return i+100 def Bar(arg): print('-->exec done:',arg) pool = Pool(5) for i in range(10): pool.apply_async(func=Foo, args=(i,),callback=Bar) #pool.apply(func=Foo, args=(i,)) print('end') pool.close() pool.join()进程池内部维护一个进程序列,当使用时,就去进程池中获取一个进程,如果进程池中没有可供使用的进程,那么程序就会等待,直到进程池中有可用的进程为止。
进程池中的两个方法:
1、apply
2、map
3、apply_async 是异步的,也就是在启动进程之后会继续后续的代码,不用等待进程函数返回
4、map_async 是异步的,
5、join语句要放在close语句后面
7、协程
-
协程是什么?
-
协程,又称微线程,英文名为Coroutine,协程是用户态的轻量级的线程。协程拥有自己的寄存器上下文和栈。协程调用切换时,将寄存器上下文和栈保存到其他地方,在切换回来的时候,可以恢复先前保存的寄存器上下文和栈,因此:
协程能保留上一次调用的状态,每次过程重入的时候,就相当于进入上一次调用的状态,换种说话,进入上一次离开时所处的逻辑流的位置
总结:
1、协程必须在只有一个单线程里实现并发
2、修改共享数据不需要加锁
3、用户程序里自己保存多个控制流的上下文和栈
4、一个协程遇到IO操作自动切换到其他线程
-
-
协程的好处?
1、无需线程上下文切换的开销
2、无需院子操作锁定以及同步的开销(原子操作是不需要同步,所谓原子操作是指不会被线程调度机制打断的操作,也就是说该操作必须执行完毕,才能进行线程切换;原子操作可以是一个步骤,也可以是多个操作步骤)
3、方便切换控制流,简化编程模型
4、高并发+高扩展+低成本:一个CPU支持上万的协程都不是问题,所以很适合高并发的问题。
-
协程的缺点
1、无法利用多核资源:协程的本质是一个单线程,它不能同时将单个CPU的多个核用上,协程需要和进程配合才能利用多核CPU;我们日常所编写的大部分应用没有这个必要,除非是CPU密集性应用
2、进行阻塞操作入IO会阻塞掉整个程序
-
yield实现协程案例
# author:Dman # date:2019/4/1 import time import queue def consumer(name): print('---开始生产包子') while True: new_baozi = yield print("[%s] is eating baozi %s" % (name,new_baozi)) def producer(): next(con1) next(con2) n = 0 while n<5: n += 1 con1.send(n) con2.send(n) print("\033[32;1m[producer]\033[0m is making baozi %s" % n) if __name__ == '__main__': con1 = consumer('c1') con2 = consumer('c2') p = producer() #------------------运行结果--------------- ---开始生产包子 ---开始生产包子 [c1] is eating baozi 1 [c2] is eating baozi 1 [producer] is making baozi 1 [c1] is eating baozi 2 [c2] is eating baozi 2 [producer] is making baozi 2 [c1] is eating baozi 3 [c2] is eating baozi 3 [producer] is making baozi 3 [c1] is eating baozi 4 [c2] is eating baozi 4 [producer] is making baozi 4 [c1] is eating baozi 5 [c2] is eating baozi 5 [producer] is making baozi 5 -
greenlet模块支持的协程
相比较yield,可以在任意函数之间随意切换,而不需要把这个函数先声明成为generaor。(但是它无法自动遇到IO阻塞去切换,必须手动去切换)
from greenlet import greenlet def test1(): print(12) gr2.switch() print(34) gr2.switch() def test2(): print(56) gr1.switch() print(78) gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch() #调用switch去切换执行函数 #----------执行结果---------------- 12 56 34 78 -
gevent模块支持的协程
-
理解
使用gevent,可以获得极高的并发性能,但gevent只能在Unix/Linux下运行,在Windows下不保证正常安装和运行。(它可以在遇到IO阻塞的时候自动切换)
由于gevent是基于IO切换的协程,所以最神奇的是,我们编写的Web App代码,不需要引入gevent的包,也不需要改任何代码,仅仅在部署的时候,用一个支持gevent的WSGI服务器,立刻就获得了数倍的性能提升。具体部署方式可以参考后续“实战”-“部署Web App”一节。
-
简单案例
# author:Dman # date:2019/4/1 """ gevent 封装了greenlet,这个不需要自己去切换,遇到io阻塞,模块会自己去切换任务。 我们只需要把gevent对象加到里面 """ import gevent def func1(): print('\033[31;1m李闯在跟海涛搞...\033[0m') gevent.sleep(2) #模拟IO阻塞,自动开始切换 print('\033[31;1m李闯又回去跟继续跟海涛搞...\033[0m') def func2(): print('\033[32;1m李闯切换到了跟海龙搞...\033[0m') gevent.sleep(1) print('\033[32;1m李闯搞完了海涛,回来继续跟海龙搞...\033[0m') gevent.joinall([ gevent.spawn(func1), #将函数加到里面。 gevent.spawn(func2), # gevent.spawn(func3), ]) #-----------执行结果------------- 李闯在跟海涛搞... 李闯切换到了跟海龙搞... 李闯搞完了海涛,回来继续跟海龙搞... 李闯又回去跟继续跟海涛搞... -
同步IO和异步IO的区别
# author:Dman # date:2019/4/1 import gevent def task(pid): """ Some non-deterministic task """ gevent.sleep(0.5) print('Task %s done' % pid) def synchronous(): for i in range(1, 10): task(i) def asynchronous(): #异步io函数 threads = [gevent.spawn(task, i) for i in range(10)] gevent.joinall(threads) print('Synchronous:'.center(20,'-')) synchronous() print('Asynchronous:'.center(20,'-')) asynchronous() -
简单的异步爬虫,遇到IO阻塞会自动切换任务
from gevent import monkey import time monkey.patch_all() # 在最开头的地方gevent.monkey.patch_all();把标准库中的thread/socket等给替换掉, # 这样我们在后面使用socket的时候可以跟平常一样使用,无需修改任何代码,但是它变成非阻塞的了. # import gevent from urllib.request import urlopen def f(url): print('GET: %s' % url) resp = urlopen(url) data = resp.read() print('%d bytes received from %s.' % (len(data), url)) list = ['https://www.python.org/','https://www.yahoo.com/','https://github.com/'] start = time.time() # for url in l: # f(url) gevent.joinall([ gevent.spawn(f, list[0]), gevent.spawn(f, list[1]), gevent.spawn(f, list[2]), ]) print(time.time()-start) #-----------输出结果--------------- GET: https://www.python.org/ GET: https://www.yahoo.com/ GET: https://github.com/ 48560 bytes received from https://www.python.org/. 82655 bytes received from https://github.com/. 536556 bytes received from https://www.yahoo.com/. 3.361192226409912
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号