

消息队列
消息队列的好处
1、解耦:

系统A只负责将生产的userId写入到消息队列中,系统A为生产者
系统B,C,D作为消费者,从消息队列中去取userId即可。实现了解耦
2、异步
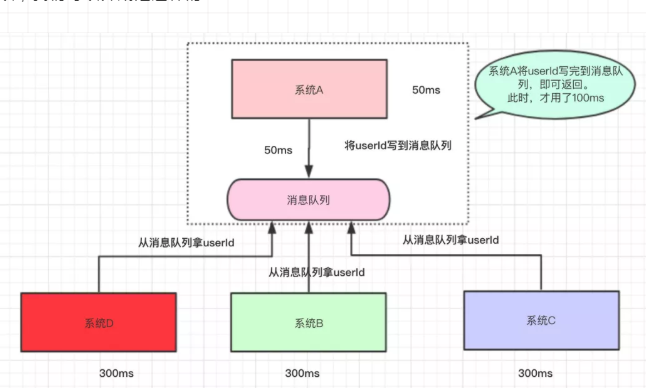
系统A是主要业务,将数据写入到消息队列即可返回,而其它系统则只需异步的去读取就可以了。
3、削峰,限流
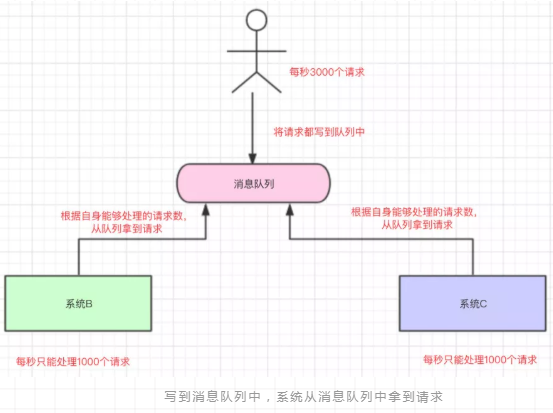
在高并发的场景下,将请求写入到消息队列中,然后系统根据自身的要求去从消息队列中获取请求来处理。
消息队列模式
1、点对点模式(消费者主动拉取消息)
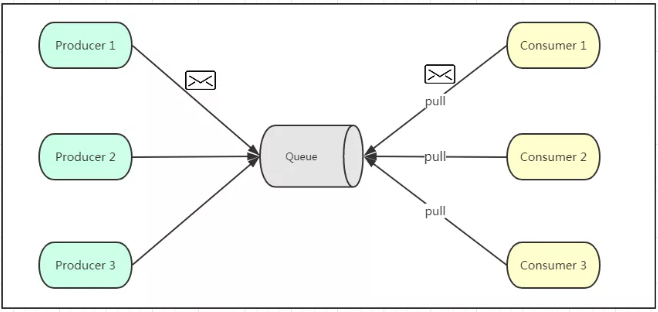
点对点模式通常是基于拉取或者轮询的消息传送模型,这个模型的特点是发送到队列的消息被一个且只有一个消费者进行处理
优点:
生产者将消息放入消息队列后,由消费者主动的去拉取消息进行消费。点对点模型的优点是消费者拉取消息的频率可以由自己控制。
缺点:
但是消息队列是否有消息需要消费,在消费者端无法感知,所以在消费者端需要额外的线程去监控
2、发布订阅模式(推送消息)
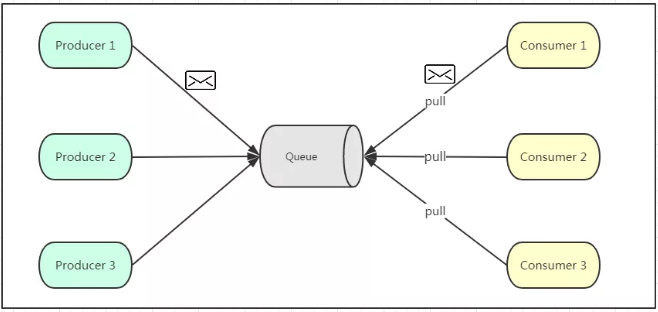
生产者将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者
优点:
由于是消费者被动接收推送,所以无需感知消息队列是否有待消费的消息!
缺点:
但是 Consumer1、Consumer2、Consumer3 由于机器性能不一样,所以处理消息的能力也会不一样,
但消息队列却无法感知消费者消费的速度!
消息队列存在的问题与解决思路
1、可用性降低
在加入MQ之前,你不用考虑MQ服务器挂掉的情况,引入MQ之后你就需要去考虑了,可用性降低。
解决思路:
引入消息队列后,系统的可用性下降。实际项目中发送MQ消息,如果不做集群,其中mq机器出了故障宕机了,
那么mq消息就不能发送了,系统就崩溃了,所以我们需要集群MQ,当其中一台MQ出了故障,其余的MQ机器可以接着继续运转
2、如何保证消息不被重复消费
解决思路:
<1> 如果消息是做数据库的插入操作,给这个消息做一个唯一主键,
那么就算出现重复消费的情况,就会导致主键冲突,避免数据库出现脏数据。
<2> 如果你拿到这个消息做redis的set的操作,不用解决,因为你无论set几次结果都是一样的,
set操作本来就算幂等操作。
<3> 如果上面两种情况还不行,准备一个第三服务方来做消费记录。以redis为例,给消息分配一个全局id,
只要消费过该消息,将<id,message>以K-V形式写入redis。那消费者开始消费前,先去redis中查询有没消费记录即可。
3、如何保证从消息队列里拿到的数据按顺序执行
解决思路:
<1> rabbitmq:拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点;
或者就一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理
<2> kafka:一个topic,一个partition,一个consumer,内部单线程消费,
写N个内存queue,然后N个线程分别消费一个内存queue即可
Kafka应用场景
消息系统或是说消息队列中间件是当前处理大数据一个非常重要的组件,用来解决应用解耦、异步通信、流量控制等问题,
从而构建一个高效、灵活、消息同步和异步传输处理、存储转发、可伸缩和最终一致性的稳定系统。
当前比较流行的消息中间件有Kafka、RocketMQ、RabbitMQ、ZeroMQ、ActiveMQ、MetaMQ、Redis等,这些消息中间件在性能及功能上各有所长。
如何选择一个消息中间件取决于我们的业务场景、系统运行环境、开发及运维人员对消息中件间掌握的情况等。
我认为在下面这些场景中,Kafka是一个不错的选择。
(1)消息系统。Kafka作为一款优秀的消息系统,具有高吞吐量、内置的分区、备份冗余分布式等特点,为大规模消息处理提供了一种很好的解决方案。
(2)应用监控。利用Kafka采集应用程序和服务器健康相关的指标,如CPU占用率、IO、内存、连接数、TPS、QPS等,然后将指标信息进行处理,
从而构建一个具有监控仪表盘、曲线图等可视化监控系统。例如,很多公司采用Kafka与ELK(ElasticSearch、Logstash和Kibana)整合构建应用服务监控系统。
(3)网站用户行为追踪。为了更好地了解用户行为、操作习惯,改善用户体验,进而对产品升级改进,将用户操作轨迹、内容等信息发送到Kafka集群上,
通过Hadoop、Spark或Strom等进行数据分析处理,生成相应的统计报告,为推荐系统推荐对象建模提供数据源,进而为每个用户进行个性化推荐。
(4)流处理。需要将已收集的流数据提供给其他流式计算框架进行处理,用Kafka收集流数据是一个不错的选择,而且当前版本的Kafka提供了Kafka Streams支持对流数据的处理。
(5)持久性日志。Kafka可以为外部系统提供一种持久性日志的分布式系统。日志可以在多个节点间进行备份,Kafka为故障节点数据恢复提供了一种重新同步的机制。
同时,Kafka很方便与HDFS和Flume进行整合,这样就方便将Kafka采集的数据持久化到其他外部系统。
多维度比较kafka与rabbitmq
稳定性(rabbitmq占优)
RabbitMq 比Kafka 成熟,在稳定性上,可靠性上, RabbitMq 胜于 Kafka (理论上)。
在架构模型方面
RabbitMQ遵循AMQP协议,RabbitMQ的broker由Exchange,Binding,queue组成,其中exchange和binding组成了消息的路由键;
客户端Producer通过连接channel和server进行通信,Consumer从queue获取消息进行消费(长连接,queue有消息会推送到consumer端,consumer循环从输入流读取数据)。
rabbitMQ以broker为中心;有消息的确认机制。
kafka遵从一般的MQ结构,producer,broker,consumer,以consumer为中心,消息的消费信息保存的客户端consumer上,consumer根据消费的点,从broker上批量pull数据;无消息确认机制。
在吞吐量(kafka占优)
kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。
rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;
基于存储的可靠性的要求存储可以采用内存或者硬盘。
可用性方面
rabbitMQ支持miror的queue,主queue失效,miror queue接管。
kafka的broker支持主备模式。
集群负载均衡方面
kafka采用zookeeper对集群中的broker、consumer进行管理,可以注册topic到zookeeper上;通过zookeeper的协调机制,
producer保存对应topic的broker信息,可以随机或者轮询发送到broker上;并且producer可以基于语义指定分片,消息发送到broker的某分片上。
rabbitMQ的负载均衡需要单独的loadbalancer进行支持。
定位不同
Kafka 的定位主要在日志等方面, 因为Kafka 设计的初衷就是处理日志的,可以看做是一个日志(消息)系统一个重要组件,
针对性很强。
所以 如果业务方面还是建议选择 RabbitMq
消息量大小:(kafka占优)
如果你的消息量很大,比如 100k+/sec,那么 rabbitMQ 几乎不能有效处理,大量的消息会滞留在这个 broker 上。但是很多时候,
我们的应用如果消息量在一个较小的数量级,这个就不会给 kafka 太大的优势了。
要注意的是 kafka 是分布式的消息系统,它的高 throughput,也是部分取决于你是不是有一个比较大的服务器群,
如果只是一个很小规模的系统,kafka 可能也没法完全施展它的优势。
关于 message 的顺序:(kafka占优)
Kafka 的消息说白了就是一个 log。它会保证所有的消息是 in order 的。但是它也不允许你对消息的顺序有任何改动。
与之相反,rabbitMQ 从某种意义上来说,它在每个 queue 上都维护了消息的一个逻辑拷贝。
什么意思呢?两个方面。第一,kafka 的消息永远按顺序来,rabbitMQ 的消息投放基本上是不保证顺序的(AMQP 0.9.1 model 中的原话:
“one producer channel, one exchange, one queue, one consumer channel" is required for in-order delivery“)。
第二,上面说的保证顺序,很多时候是一个优势,但是在一些特定的情况下其实是一个劣势。
举个例子。如果在处理一个消息的过程中,一个consumer 突然挂了。kafka 是不管的,怎么善后,由 consumer 客户端自行解决。而对于 rabbitMQ,
它可以对消息进行重新排序或重组,这样相对的 queue 就可以重试。换句话说,rabbitMQ 的 broker 帮你在 failure 的时候保存你的状态。而 kafka 的用户
,正是因为它允许任意的consumer,所以它其实有一个未知的 consumer 组,那么它的 queue 所有的逻辑都必须是独立于 consumer 的,
因此也就没有办法很好的干涉消息的顺序。
Kafka是严格保证了消息队列的顺序,就是一个topic下面的一个分区内只能给一个消费者消费,对于一个分区来说,kafka是不支持并发,但是可以通过扩大分区实现并发
Rabbitmq 不承诺消息的顺序性,因此可以并发多线程处理。在队列中不必排队。如果对处理的顺序没有要求,就可以用Rabbitmq教容易的实现并发。
consumer 的多样性:(kafka占优)
Kafka 是 producer 为中心的,因此他不会对 consumer 是不是能按需方便的拿到消息,人家才不管你。
而 rabbitMQ 是 broker 为中心的,因此它会很大程度上考虑到 consumer 的接受能力等。这就意味着,
如果你的 consumer 是各种各样不用的机器或者服务器端,kafka 有着绝对优势。
而 rabbitMQ 只能处理相对比较 相同类型的 consumer 服务器群。
关于单条 message 的处理:(rabbitmq占优)
kafka 中每一条消息其实都是没有 id 的。因为全是字节流,消息是通过一个 offset 来标示的。
而 rabbitMQ 其实每个 message 有类型,也有标示。这样,一些 fail 的消息就可以被放到未来的一个时间来重新投送和处理。
这个消息就叫做 “dead letter” , 然后rabbitMQ 中你可以指定一个 exchange 来专门处理这些消息的重新发送。
这个 exchange 就是 dead letter exchange。它可以处理失败消息的重发以及多次失败后的 expiration。
总结:
kafka 支持高流量,但是消息就被当作简单有序的 log,侧重于消息共享,不能做太多的基于逐条消息的处理。
而rabbitMQ 支持中小流量,但是在消息处理上有很大的灵活性
参考:
Kafka、RabbitMQ、RocketMQ等消息中间件的对比 —— 消息发送性能和区别

