
Mongodb_分片集群模式
前面介绍的副本集模式实现了数据库高可用。
但是还是存在的问题是:
所有的从节点都是从主节点全面拷贝,这样数据量过大时,从节点压力大。还有就是海量数据时存在硬件瓶颈,
毕竟每一个机器的存储量总是有限的。
现在分片模式可以解决上述问题,实现可扩展性。
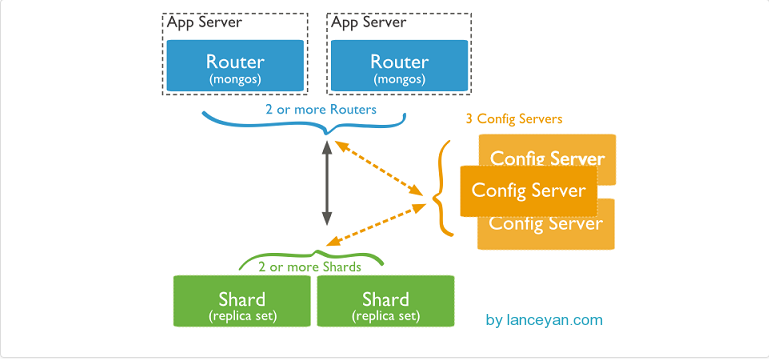
mongos:数据库集群请求的入口
所有对数据库的请求都是经过mogos进行协调,分发给不同的shard server。
config server:存储数据库分配元信息(路由,分片等信息)
mongos没有物理内存来存储路由数据信息和分片服务器信息,需要从配置服务器读取。在每次mongos启动时会
从配置服务器读取配置信息,缓存到内存中。配置服务器内容改变时,会通知mongos来获取信息。
shard:分片服务器
将数据进行分片,从而可以达到可扩展的扩容的效果
本地进行测试:
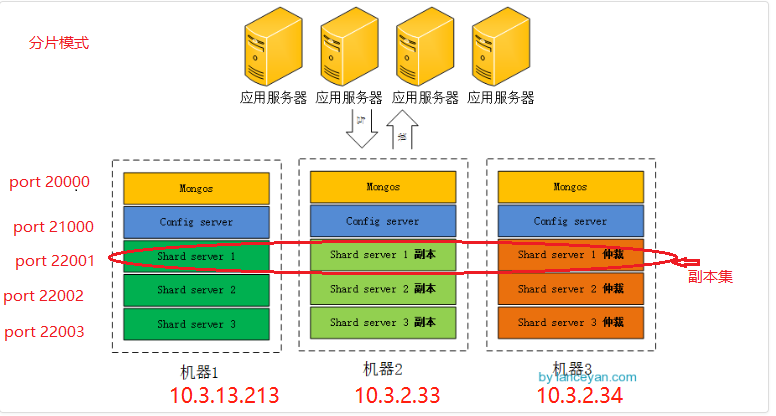
本地环境搭建
1.分别在/usr/local/server下创建文件夹:config mongodb mongos shard1 shard2 shard3
2.在这几个文件夹下分别创建 日志文件夹log和数据文件夹 data
3.启动分片shard服务器:在三台机器上分别运行
/usr/local/server/mongodb/bin/mongod --fork --shardsvr --replSet shard1 --port 22001 -bind_ip 0.0.0.0 --dbpath /usr/local/server/shard1/data/ --logpath /usr/local/server/shard1/log/shard1.log
/usr/local/server/mongodb/bin/mongod --fork --shardsvr --replSet shard2 --port 22002 -bind_ip 0.0.0.0 --dbpath /usr/local/server/shard2/data/ --logpath /usr/local/server/shard2/log/shard2.log
/usr/local/server/mongodb/bin/mongod --fork --shardsvr --replSet shard3 --port 22003 -bind_ip 0.0.0.0 --dbpath /usr/local/server/shard3/data/ --logpath /usr/local/server/shard3/log/shard3.log
10.3.13.213(三台任意一台机器上都可以)上:
//设置第一个分片
>/usr/local/server/mongodb/bin/mongo --port 22001
>use admin
>config = { _id:"shard1", members:[
{_id:0,host:"10.3.13.213:22001"},
{_id:1,host:"10.3.2.33:22001"},
{_id:2,host:"10.3.2.34:22001",arbiterOnly:true}
]
}
>rs.initiate(config);
>rs.status() #查看状态
//设置第二个分片
>/usr/local/server/mongodb/bin/mongo --port 22002
>use admin
config = { _id:"shard2", members:[
{_id:0,host:"10.3.13.213:22002"},
{_id:1,host:"10.3.2.33:22002"},
{_id:2,host:"10.3.2.34:22002",arbiterOnly:true}
]
}
rs.initiate(config);
//设置第三个分片
>/usr/local/server/mongodb/bin/mongo --port 22003
>use admin
config = { _id:"shard3", members:[
{_id:0,host:"10.3.13.213:22003"},
{_id:1,host:"10.3.2.33:22003"},
{_id:2,host:"10.3.2.34:22003",arbiterOnly:true}
]
}
rs.initiate(config);
4.启动config服务器
在三台机器上分别运行
/usr/local/server/mongodb/bin/mongod --fork --configsvr --port 21000 --replSet docdetection -bind_ip 0.0.0.0 --dbpath /usr/local/server/config/data --logpath /usr/local/server/config/log/logs
#初始化配置服务器
>/usr/local/server/mongodb/bin/mongo --port 21000
>use admin
configdb1 = { _id:"docdetection", members:[
{_id:0,host:"10.3.13.213:21000",priority:3},
{_id:1,host:"10.3.2.33:21000",priority:2},
{_id:2,host:"10.3.2.34:21000",priority:1}
]
}
rs.initiate(configdb1);
配置路由服务器
/usr/local/server/mongodb/bin/mongo --port 20000
>use admin
#串联路由服务器与分片副本集1
db.runCommand( { addshard : "shard1/10.3.13.213:22001,10.3.2.33:22001,10.3.2.34:22001"});
#串联路由服务器与分片副本集2
db.runCommand( { addshard : "shard2/10.3.13.213:22002,10.3.2.33:22002,10.3.2.34:22002"});
#串联路由服务器与分片副本集3
db.runCommand( { addshard : "shard3/10.3.13.213:22003,10.3.2.33:22003,10.3.2.34:22003"});
#查看分片服务器的配置
db.runCommand( { listshards : 1 } );
6.测试:
#指定数据库testdb分片生效
/usr/local/server/mongodb/bin/mongo --port 20000 #连接上mongos服务器(任意一个)
>use admin # 分片只针对admin数据库里运行
#指定testdb分片生效
mongos> db.runCommand({enablesharding:"testdb"})
#指定数据库里需要分片的集合和片键
mongos> db.runCommand( { shardcollection : "testdb.table1",key : {id: 1} } )
插入测试数据
for (var i = 1; i <= 100000; i++)
db.table1.save({id:i,"test1":"testval1"});
#查看分片情况如下
db.table1.stats();
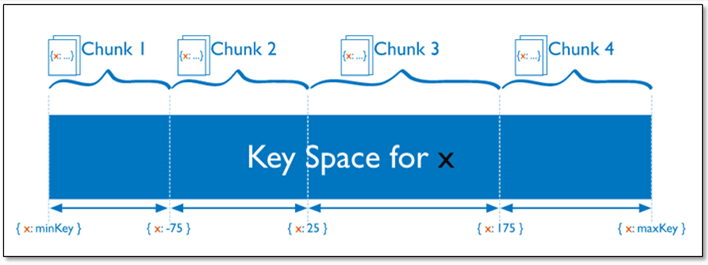
chunck
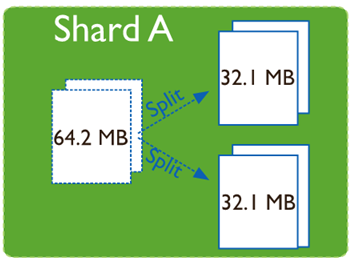
在一个shard server内部,MongoDB还是会把数据分为chunks,每个chunk代表这个shard server内部一部分数据
Splitting:当一个chunk的大小超过配置中的chunk size时,MongoDB的后台进程会把这个chunk切分成更小的chunk,从而避免chunk过大的情况
Balancing:在MongoDB中,balancer是一个后台进程,负责chunk的迁移,从而均衡各个shard server的负载,系统初始1个chunk,
chunk size默认值64M,生产库上选择适合业务的chunk size是最好的。
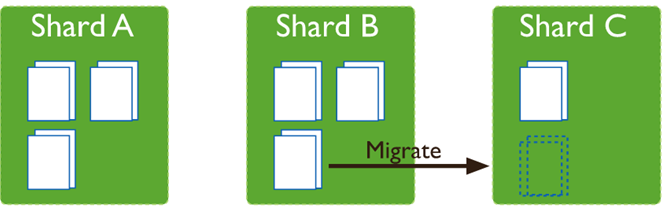
mongodb如何进行分片
mongodb支持自动分片,也就是数据库的具体分片结构对于应用程序来说不可见。
路由服务器:维护内容列表,指明每一个分片包含什么数据,所有的请求都是经过路由服务器进行转发。
sh.status() 查看集群状态
对集合分片时,需要选择一个片键(share key),片键是集合的一个键,mongodb根据这个键来拆分数据。
在查询时:一种包含片键的查询:可以直接定位到指定的分片上去查询--定向查询,
其它的查询:会发送到所有的分片上,然后将结果聚合,分散聚合查询。
基于范围的分片
admin> db.runCommand( { shardcollection : "数据库名称.集合名称",key : {分片键: 1} } )
基于hash的分片
admin > sh.shardCollection( "数据库名.集合名", { 片键: "hashed" } )

分片键选择
1、递增的sharding key
数据文件挪动小。(优势)
因为数据文件递增,所以会把insert的写IO永久放在最后一片上,造成最后一片的写热点。同时,随着最后一片的数据量增大,将不断的发生迁移至之前的片上。
2、随机的sharding key
数据分布均匀,insert的写IO均匀分布在多个片上。(优势)
大量的随机IO,磁盘不堪重荷。
3、混合型key
大方向随机递增,小范围随机分布。
为了防止出现大量的chunk均衡迁移,可能造成的IO压力。我们需要设置合理分片使用策略(片键的选择、分片算法(range、hash))
参考:http://www.lanceyan.com/tech/arch/mongodb_shard1.html
https://www.cnblogs.com/clsn/p/8214345.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号