

ES优化:查询太慢?看看ES是如何把索引的性能压榨到极致的!
章的最后提到了倒排索引,不知道有没有勾起大家的好奇心,ES的索引是怎么做,为什么他会被广泛地叫做搜索引擎而不是数据库?根源在它的索引,所以这一篇带你一探究竟。
言归正传,说起索引肯定是绕不开经典的B-Tree,来看两张图简单回顾下你们大学的课本内容。
B-Tree
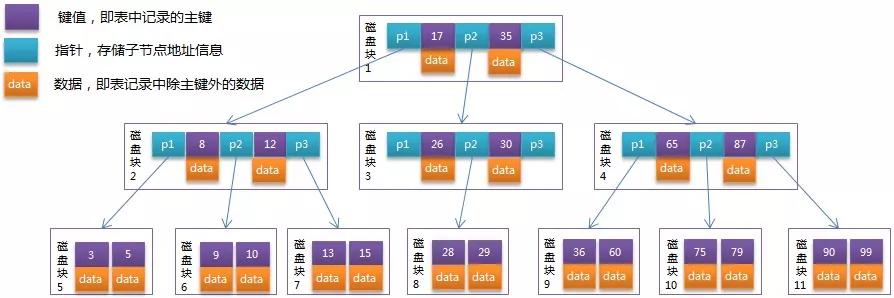
B+Tree
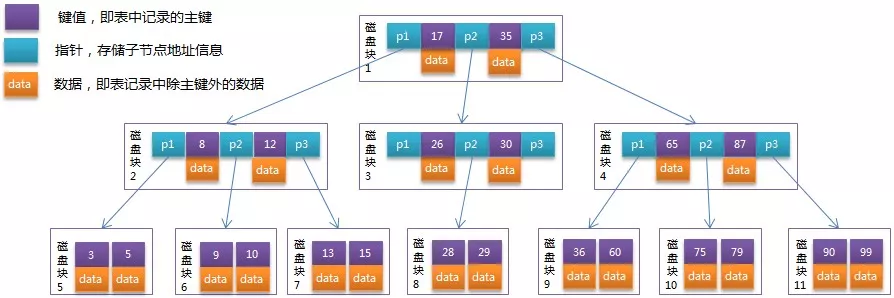
B+Tree是B-Tree的优化,两者的区别由图应该是可以看得比较清楚的。
- 非叶子节点只存储键值信息。
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
笼统的来说,b-tree 索引是为写入优化的索引结构。所以当我们不需要支持快速的更新的时候,可以用预先排序等方式换取更小的存储空间,更快的检索速度等好处,其代价就是更新慢。要进一步深入的化,还是要看一下 Lucene 的倒排索引是怎么构成的。

看个具体的倒排索引实例,写入如下三条数据;
| ID | Name | Sex |
| 1 | Kate | Female |
| 2 | John | Male |
| 3 | Bill | Male |
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name
| Term | Posting List |
| Kate | 1 |
| John | 2 |
| Bill | 3 |
Sex
| Term | Posting List |
| Female | 1 |
| Male | [2,3] |
问题来了,在Term量非常大的时候,怎么快速找到目标Term的位置?来看看ES是怎么做的。
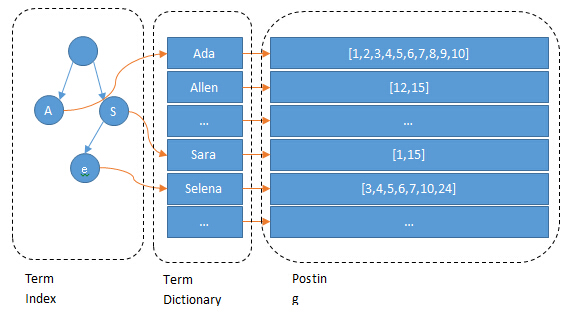
Term Dictionary:把Term按字典序排列,然后用二分法查找Term (存在磁盘)
Term Index:是Term Dictionary的索引,存Term的前缀,和与该前缀对应的Term Dictionary中的第一个Term的block的位置,找到这个第一个Term后会再往后顺序查找,直到找到目标Term。(存在内存)
Term Index的压缩
所以,理论上Term Index的数据结构就是:
Map<Term的前缀, 对应的block的位置>
但是Term量大的情况下同样会把内存撑爆。所以有了基于FST的压缩技术。
Finite State Transducers(FST):有穷状态转换器,Term Index采用的压缩技术。
举个例子:
Map[“cat” - > 5, “deep” - > 10, “do” - > 15, “dog” - > 2, “dogs” - > 8 ]
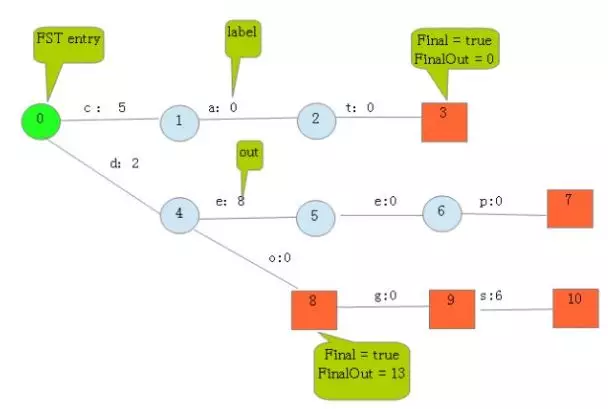
- 每条边有两条属性,一个表示label(key的元素,上图有点问题,应该是指向a的),另一个表示Value(out)。
- 每个节点有两个属性,Final=true/false(有key再这个节点结束则为true);final为true时,还有个FinalOut,FinalOut=entry的value值-该路径out值之和。
- 举个例子:8号节点,对应的entry的key是do,value是15,而该路径out值之和是2,所以FinalOut=15-2=13
- out值怎么来的?
- 当只有一条数据写入时如cat,则第一个字节即“c”的out值就等于该entry的value值即“5”;
- 当deep写入时因为后面d开头的数据还没写,所以“d”的out值就是“10”;
- 当do写入时,因为“d”=“10”,所以“o”=“15”-“10”=“5”
- 当dog写入时,因为“d”=“10”,“o”=“5”,已经超过了dog的值“2”,此时,会把“d”设为“2”,“o”设为“0”,这样才能满足dog=“2”的情况。
- 但是,这样deep和do的out值就要重新分配了
- deep的整条路径和为“10”,已知“d”=“2”,所以“e”承包剩下的“8”。
- do的整条路径和为“15”,已经“d”=“2”,“o”=“0”,没有label了,所以FinalOut=15-2-0=13。
由上所述,不难得出,FST查询的复杂度时O(1),能快速定位到目的Term前缀的Block位置。
Posting List的压缩
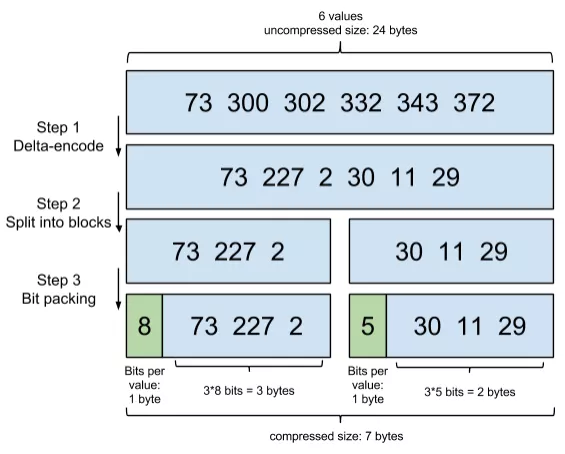
关键在于:增量编码压缩,将大数变小数,按字节存储。
原理就是通过增量,将原来的大数变成小数仅存储增量值,再精打细算按bit排好队,最后通过字节存储。
BitMaps
假设有某个posting list: [1,3,4,7,10]
对应的bitmap就是: [1,0,1,1,0,0,1,0,0,1]
用0/1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。Bitmap的缺点是存储空间随着文档个数线性增长。

将posting list按照65535为界限分块,比如第一块所包含的文档id范围在0~65535之间,第二块的id范围是65536~131071,以此类推。
再用<商,余数>的组合表示每一组id,这样每组里的id范围都在0~65535内了,剩下的就好办了,既然每组id不会变得无限大,那么我们就可以通过最有效的方式对这里的id存储。
short[] 占的空间:2bytes(65535 = 2^16-1 是2bytes 能表示的最大数)
bitmap 占的空间: 65536/8 = 8192bytes
当block块里元素个数不超过4096,用short[],因为4096个short[]才等于 8192bytes;而一个bitmap就等于8192bytes了,虽然它能存65536个元素。
联合索引
联合索引通俗地说就是找到满足多个搜索条件的文档ID。那么这种场景下,倒排索引如何满足快速查询的要求呢?
利用跳表(Skip list)的数据结构快速做“与”运算,或者
利用上面提到的bitset按位“与”
先看看跳表的数据结构:
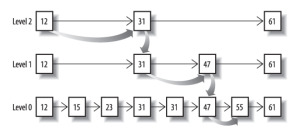
将一个有序链表level0,挑出其中几个元素到level1及level2,每个level越往上,选出来的指针元素越少,查找时依次从高level往低查找,比如55,先找到level2的31,再找到level1的47,最后找到55,一共3次查找,查找效率和2叉树的效率相当,但也是用了一定的空间冗余来换取的。
假设有下面三个posting list需要联合索引:
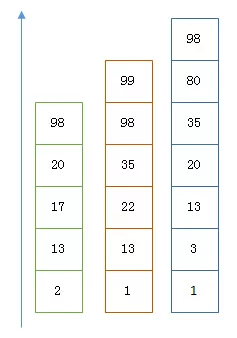
如果使用跳表,对最短的posting list中的每个id,逐个在另外两个posting list中查找看是否存在,最后得到交集的结果。
如果使用bitset,就很直观了,直接按位与,得到的结果就是最后的交集。

