
Tesseract_ocr 字符识别基础及训练字库、合并字库
字符训练网上一搜一大堆,但作为一个初学者而言,字符合并网上却写的很笼统
首先,需要 生成的字符集.tif文件,位置文件 .box ,只要有这两个文件在,就可以合并字典(这个说的很有道理的样子)
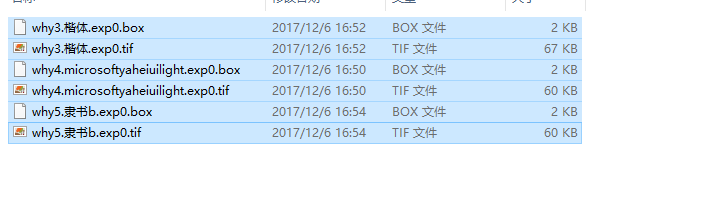
好了,我现在有三个需要合并的字典
(1).(why3.楷体.exp0.tif,why3.楷体.exp0.box)
(2).(why4.microsoftyaheiuilight.exp0.tif,why4.microsoftyaheiuilight.exp0.box)
(3). (why5.隶书b.exp0.tif,why5.隶书b.exp0.box)
1、先生成相对应的 .tr 文件
//自己的命令根据自己的情况进行修改
tesseract why3.楷体.exp0.tif why3.楷体.exp0 nobatch box.train
tesseract why4.microsoftyaheiuilight.exp0.tif why4.microsoftyaheiuilight.exp0 nobatch box.train
tesseract why5.隶书b.exp0.tif why5.隶书b.exp0 nobatch box.train
2、从所有文件中提取字符
//自己的命令根据自己的情况进行修改
unicharset_extractor why3.楷体.exp0.box why4.microsoftyaheiuilight.exp0.box why5.隶书b.exp0.box
3、生成字体特征文件
新建的font.txt文件,在文件中把所有box文件对应的字体特征都加进去(如果不知道,可以去原来考出来的字库文件找.font_properties文件查看)
楷体 0 0 0 0 0
microsoftyaheiuilight 0 0 0 0 0
隶书b 0 1 0 0 0
写完之后,执行如下命令:
mftraining -F font.txt -U unicharset why3.楷体.exp0.tr why4.microsoftyaheiuilight.exp0.tr why5.隶书b.exp0.tr
4 、聚集所有.tr 文件
cntraining why3.楷体.exp0.tr why4.microsoftyaheiuilight.exp0.tr why5.隶书b.exp0.tr
5 、重命名文件,我把unicharset, inttemp, normproto, pfftable,shapetable 这几个文件加了前缀why. (自己定,随意) //我加的是together.
6、合并所有文件 生成一个大的字库文件
combine_tessdata together.
目录下生成的结果如下: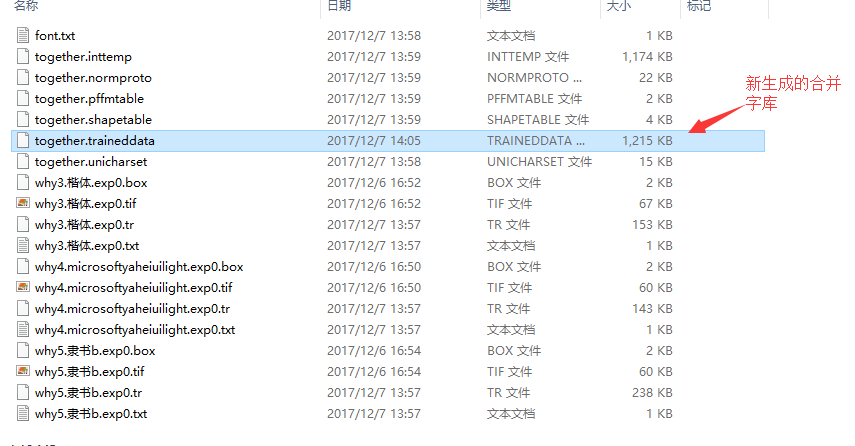
把合并字库拷进如下目录: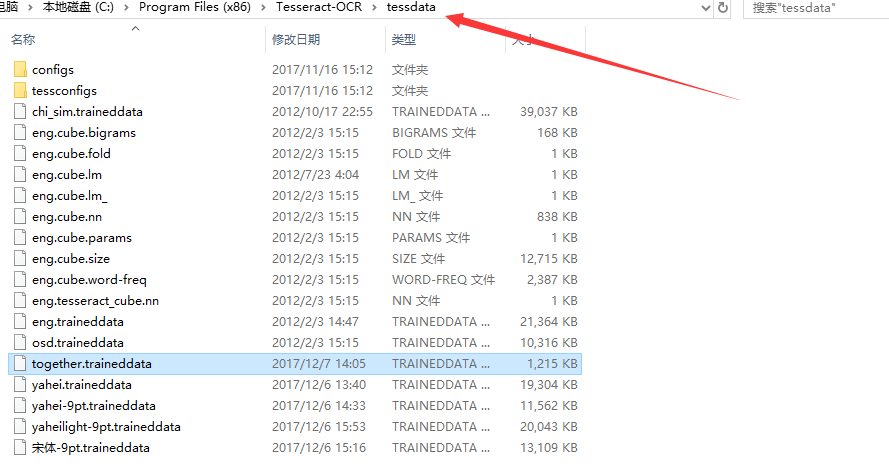
测试图片如下:

执行如下代码:
# coding=utf-8 __author__ = 'syq' #https://github.com/tesseract-ocr import sys import importlib #reload(sys) importlib.reload(sys); #sys.setdefaultencoding('utf-8') import os; os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8' try: from pyocr import pyocr from PIL import Image except ImportError: print('模块导入错误,请使用pip安装,pytesseract依赖以下库:') print('http://www.lfd.uci.edu/~gohlke/pythonlibs/#pil') print('http://code.google.com/p/tesseract-ocr/') raise SystemExit tools = pyocr.get_available_tools()[:] if len(tools) == 0: print("No OCR tool found") sys.exit(1) print("Using '%s'" % (tools[0].get_name())) print(tools[0].image_to_string(Image.open('pic\\123.png'),lang='together'))
结果如下:

效果还可以,厉害了
参考:http://blog.csdn.net/dragoo1/article/details/8439272
http://www.lxway.com/815805156.htm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号