ceph 分布式文件系统
Ceph 介绍
Ceph 是一个能提供文件存储(cephfs)、块存储(rbd)和对象存储(rgw)的分布式存储系统,具有高扩展性、高性能、高可靠性等优点。Ceph 在存储的时候充分利用存储节点的计算能力,在存储每一个数据时都会通过计算得出该数据的位置,尽量的分布均衡。
Ceph 特点
-
高性能
-
摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
-
考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架等。
-
能够支持上千个存储节点的规模,支持TB到PB级的数据。
-
-
高可用性
- 副本数可以灵活控制。
- 支持故障域分割,数据强一致性。
- 多重故障场景自动进行修复自愈。
- 没有单点故障,自动管理。
-
高可扩展性
- 去中心化。
- 扩展灵活。
- 随着节点增加而线性增长。
-
特性丰富
- 支持三种存储接口:块存储、文件存储、对象存储。
- 支持自定义接口,支持多种语言驱动。
Ceph 架构
Ceph支持三种接口:
- Object:有原生的API,而且也兼容Swift和S3的API,适合单客户端使用
- Block:支持精简配置、快照、克隆,适合多客户端有目录结构
- File:Posix接口,支持快照
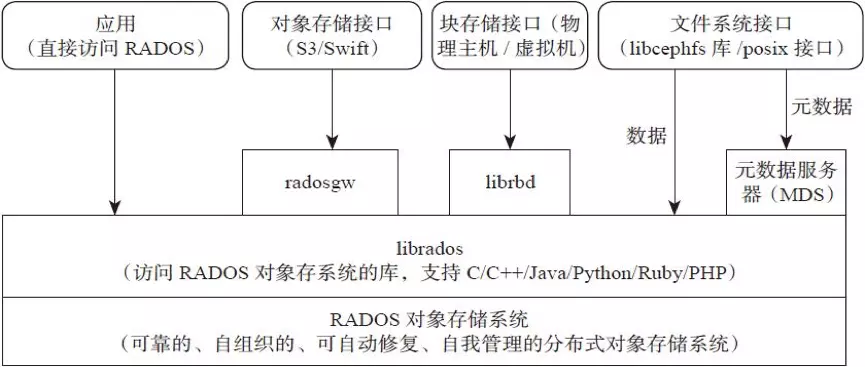
Ceph 核心概念
📌 RADOS
全称Reliable Autonomic Distributed Object Store,即可靠的、自动化的、分布式对象存储系统。RADOS是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
📌 Librados
Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
📌 Crush
Crush算法是Ceph的两大创新之一,通过Crush算法的寻址操作,Ceph得以摒弃了传统的集中式存储元数据寻址方案。而Crush算法在一致性哈希基础上很好的考虑了容灾域的隔离,使得Ceph能够实现各类负载的副本放置规则,例如跨机房、机架感知等。同时,Crush算法有相当强大的扩展性,理论上可以支持数千个存储节点,这为Ceph在大规模云环境中的应用提供了先天的便利。
📌 Pool
Pool是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略,支持两种类型:副本(replicated)和 纠删码( Erasure Code)。
📌 PG
PG( placement group)是一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略,简单点说就是相同PG内的对象都会放到相同的硬盘上,PG是 ceph的逻辑概念,服务端数据均衡和恢复的最小粒度就是PG,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
📌 Object
简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。能否弄一个读写快,利 于共享的出来呢。于是就有了对象存储。最底层的存储单元,包含元数据和原始数据。
Ceph 核心组件
📌 OSD
OSD是负责物理存储的进程,一般配置成和磁盘一一对应,一块磁盘启动一个OSD进程。主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查,负责响应客户端请求返回具体数据的进程等。
Pool、PG和OSD的关系:
- 一个Pool里有很多PG;
- 一个PG里包含一堆对象,一个对象只能属于一个PG;
- PG有主从之分,一个PG分布在不同的OSD上(针对三副本类型);
📌 Monitor
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。负责坚实整个Ceph集群运行的Map视图(如OSD Map、Monitor Map、PG Map和CRUSH Map),维护集群的健康状态,维护展示集群状态的各种图表,管理集群客户端认证与授权。
📌 MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。负责保存文件系统的元数据,管理目录结构。对象存储和块设备存储不需要元数据服务。
📌 Mgr
ceph 官方开发了 ceph-mgr,主要目标实现 ceph 集群的管理,为外界提供统一的入口。例如cephmetrics、zabbix、calamari、promethus。
📌 RGW
RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
📌 Admin
Ceph常用管理接口通常都是命令行工具,如rados、ceph、rbd等命令,另外Ceph还有可以有一个专用的管理节点,在此节点上面部署专用的管理工具来实现近乎集群的一些管理工作,如集群部署,集群组件管理等。
Ceph 存储类型

块存储(RBD)
-
优点:
- 通过Raid与LVM等手段,对数据提供了保护;
- 多块廉价的硬盘组合起来,提高容量;
- 多块磁盘组合出来的逻辑盘,提升读写效率;
-
缺点:
- 采用SAN架构组网时,光纤交换机,造价成本高;
- 主机之间无法共享数据;
-
使用场景
- docker容器、虚拟机磁盘存储分配;
- 日志存储;
- 文件存储;
文件存储(CephFS)
-
优点:
- 造价低,随便一台机器就可以了;
- 方便文件共享;
-
缺点:
- 读写速率低;
- 传输速率慢;
-
使用场景
- 日志存储;
- FTP、NFS;
- 其它有目录结构的文件存储
对象存储(Object)
-
优点:
- 具备块存储的读写高速;
- 具备文件存储的共享等特性;
-
使用场景
- 图片存储;
- 视频存储;
RADOS 存取原理
要实现数据存取需要创建一个pool,创建pool要先分配PG。

如果客户端对一个pool写了一个文件,那么这个文件是如何分布到多个节点的磁盘上呢?
答案是通过CRUSH算法。
Ceph 部署
Ceph 版本介绍
Ceph 社区最新版本是 14,而 Ceph 12 是市面用的最广的稳定版本。
第一个 Ceph 版本是 0.1 ,要回溯到 2008 年 1 月。多年来,版本号方案一直没变,直到 2015 年 4 月 0.94.1 ( Hammer 的第一个修正版)发布后,为了避免 0.99 (以及 0.100 或 1.00 ?),制定了新策略。
x.0.z - 开发版(给早期测试者和勇士们)
x.1.z - 候选版(用于测试集群、高手们)
x.2.z - 稳定、修正版(给用户们)
x 将从 9 算起,它代表 Infernalis ( I 是第九个字母),这样第九个发布周期的第一个开发版就是 9.0.0 ;后续的开发版依次是 9.0.1 、 9.0.2 等等。
| 版本名称 | 版本号 | 发布时间 |
|---|---|---|
| Argonaut | 0.48版本(LTS) | 2012年6月3日 |
| Bobtail | 0.56版本(LTS) | 2013年5月7日 |
| Cuttlefish | 0.61版本 | 2013年1月1日 |
| Dumpling | 0.67版本(LTS) | 2013年8月14日 |
| Emperor | 0.72版本 | 2013年11月9 |
| Firefly | 0.80版本(LTS) | 2014年5月 |
| Giant | Giant | October 2014 - April 2015 |
| Hammer | Hammer | April 2015 - November 2016 |
| Infernalis | Infernalis | November 2015 - June 2016 |
| Jewel | 10.2.9 | 2016年4月 |
| Kraken | 11.2.1 | 2017年10月 |
| Luminous | 12.2.13 | 2020年1月 |
| mimic | 13.2.10 | 2020年4月 |
| nautilus | 14.2.9 | 2020年4月 |
安装前准备
硬件要求:
- 最少三台Centos7系统虚拟机用于部署Ceph集群。硬件配置:2C4G,另外每台机器最少挂载三块硬盘(这里实验只是给了5G)
📝 环境准备
1、关闭防火墙(all)
# systemctl stop firewalld
# systemctl disable firewalld
2、关闭selinux(all)
# sed -i 's/enforcing/disabled/' /etc/selinux/config
# setenforce 0
3、关闭NetworkManager(all)
# systemctl disable NetworkManager
# systemctl stop NetworkManager
4、主机名设定和host绑定(all)
# hostnamectl set-hostname --static 对应主机名
# vim /etc/hosts
192.168.3.27 cdph_node1
192.168.3.60 cdph_node2
192.168.3.95 cdph_node3
5、时间同步(all)
# systemctl restart chronyd.service && systemctl enable chronyd.service
# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
6、配置ssh免密码登陆(ceph_node1节点)
[root@ceph_node1 ~]# ssh-keygen
[root@ceph_node1 ~]# ssh-copy-id ceph_node1
[root@ceph_node1 ~]# ssh-copy-id ceph_node2
[root@ceph_node1 ~]# ssh-copy-id ceph_node3
7、read_ahead,通过数据预读并且记载到随机访问内存方式提高磁盘读操作(all)
# echo "8192" > /sys/block/sda/queue/read_ahead_kb
安装部署
添加yum源
所有节点都需添加
1、添加epel源
yum install epel-release -y
2、添加ceph源(这里使用aliyun源)
# cat >/etc/yum.repos.d/ceph.repo<<EOF
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/x86_64/
enabled=1
gpgcheck=0
priority=1
[ceph-noarch]
name=ceph-noarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/
enabled=1
gpgcheck=0
priority=1
[ceph-source]
name=ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/SRPMS/
enabled=1
gpgcheck=0
priority=1
EOF
安装ceph-deploy
只需要在ceph_node1上安装,因为它是部署节点,别的节点不用安装。
[root@ceph_node1 ~]# yum install ceph-deploy -y
创建集群
在ceph_node1节点上创建集群,创建一个集群配置目录
✏️ 注意:后面大部分操作都必须要cd到此目录内操作
[root@ceph_node1 ~]# mkdir /etc/ceph
[root@ceph_node1 ~]# cd /etc/ceph
创建一个ceph集群
[root@ceph_node1 ceph]# ceph-deploy new ceph_node1 ceph_node2 ceph_node3
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy new ceph_node1 ceph_node2 ceph_node3
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] func : <function new at 0x7fc999dfbde8>
[ceph_deploy.cli][INFO ] verbose : False
......
[ceph_deploy.new][DEBUG ] Resolving host ceph_node3
[ceph_deploy.new][DEBUG ] Monitor ceph_node3 at 192.168.3.95
[ceph_deploy.new][DEBUG ] Monitor initial members are ['ceph_node1', 'ceph_node2', 'ceph_node3']
[ceph_deploy.new][DEBUG ] Monitor addrs are ['192.168.3.27', '192.168.3.60', '192.168.3.95']
[ceph_deploy.new][DEBUG ] Creating a random mon key...
[ceph_deploy.new][DEBUG ] Writing monitor keyring to ceph.mon.keyring...
[ceph_deploy.new][DEBUG ] Writing initial config to ceph.conf...
创建完成会生产以下三个文件
[root@ceph_node1 ~]# ll
total 20
-rw-r--r--. 1 root root 250 Jun 23 09:07 ceph.conf
-rw-r--r--. 1 root root 5521 Jun 23 09:07 ceph-deploy-ceph.log
-rw-------. 1 root root 73 Jun 23 09:07 ceph.mon.keyring
安装ceph软件
在所有ceph集群节点(ceph_node1、ceph_node2、ceph_node3)上安装ceph和ceph-radosgw软件包
# yum install ceph ceph-radosgw -y
# ceph -v
ceph version 13.2.10 (564bdc4ae87418a232fc901524470e1a0f76d641) mimic (stable)
创建mom监控组件
1、增减监控网络,网段为节点网段地址
在[glable]配置段里添加public network
[root@ceph_node1 ceph]# vim /etc/ceph/ceph.conf
[global]
fsid = 4c4e55ae-b4c3-44b2-afdf-81382a17c685
mon_initial_members = ceph_node1, ceph_node2, ceph_node3
mon_host = 192.168.3.27,192.168.3.60,192.168.3.95
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
public network = 192.168.3.0/24
2、监控节点初始化
[root@ceph_node1 ceph]# ceph-deploy mon create-initial
......
[ceph_deploy.gatherkeys][INFO ] Storing ceph.client.admin.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mds.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mgr.keyring
[ceph_deploy.gatherkeys][INFO ] keyring 'ceph.mon.keyring' already exists
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-osd.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-rgw.keyring
[ceph_deploy.gatherkeys][INFO ] Destroy temp directory /tmp/tmpfAMuJ7
# 出现以上信息则表示初始化成功,并会生成如下文件
[root@ceph_node1 ceph]# ll
total 220
-rw-------. 1 root root 113 Jun 23 11:25 ceph.bootstrap-mds.keyring
-rw-------. 1 root root 113 Jun 23 11:25 ceph.bootstrap-mgr.keyring
-rw-------. 1 root root 113 Jun 23 11:25 ceph.bootstrap-osd.keyring
-rw-------. 1 root root 113 Jun 23 11:25 ceph.bootstrap-rgw.keyring
-rw-------. 1 root root 151 Jun 23 11:25 ceph.client.admin.keyring
-rw-r--r--. 1 root root 281 Jun 23 11:25 ceph.conf
-rw-r--r--. 1 root root 139805 Jun 23 11:25 ceph-deploy-ceph.log
-rw-------. 1 root root 73 Jun 23 11:01 ceph.mon.keyring
# 状态为HEALTH表示健康
[root@ceph_node1 ceph]# ceph health
HEALTH_OK
3、将配置文件信息同步到所有ceph集群节点,方便执行一些管理命令
[root@ceph_node1 ceph]# ceph-deploy admin ceph_node1 ceph_node2 ceph_node3
......
[ceph_node1][DEBUG ] connected to host: ceph_node1
[ceph_node1][DEBUG ] detect platform information from remote host
[ceph_node1][DEBUG ] detect machine type
[ceph_node1][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_deploy.admin][DEBUG ] Pushing admin keys and conf to ceph_node2
[ceph_node2][DEBUG ] connected to host: ceph_node2
[ceph_node2][DEBUG ] detect platform information from remote host
[ceph_node2][DEBUG ] detect machine type
[ceph_node2][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_deploy.admin][DEBUG ] Pushing admin keys and conf to ceph_node3
[ceph_node3][DEBUG ] connected to host: ceph_node3
[ceph_node3][DEBUG ] detect platform information from remote host
[ceph_node3][DEBUG ] detect machine type
[ceph_node3][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
4、查看集群状态
[root@ceph_node1 ceph]# ceph -s
cluster:
id: 4cc2e905-73df-41e8-9d83-4a195435931d
health: HEALTH_OK #健康状态为OK
services:
mon: 3 daemons, quorum ceph_node1,ceph_node2,ceph_node3 #mon 3表示三个监控
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
创建mgr管理组件
该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好的管理ceph存储系统。
ceph dashboard图形管理也需要用到mgr
1、创建一个mgr
[root@ceph_node1 ceph]# ceph-deploy mgr create ceph_node1
# 可以看到下面的services中的mgr目前只有ceph_node1节点
[root@ceph_node1 ceph]# ceph -s
cluster:
id: 4cc2e905-73df-41e8-9d83-4a195435931d
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph_node1,ceph_node2,ceph_node3
mgr: ceph_node1(active)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
2、添加多个mgr可以实现HA
[root@ceph_node1 ceph]# ceph-deploy mgr create ceph_node2
[root@ceph_node1 ceph]# ceph-deploy mgr create ceph_node3
# 添加完成再次查看,可以发现已经有三个了。其中ceph_node1为主mgr
[root@ceph_node1 ceph]# ceph -s
cluster:
id: 4cc2e905-73df-41e8-9d83-4a195435931d
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum ceph_node1,ceph_node2,ceph_node3
mgr: ceph_node1(active), standbys: ceph_node2, ceph_node3
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
至此,ceph集群基本搭建完成,但还需要添加osd磁盘。
磁盘管理
创建osd磁盘
接着上面的集群,添加磁盘;将磁盘添加到ceph集群需要osd,osd功能是存储与数据处理,并通过检查他OSD守护进程的心跳来向Ceph Monitors 提供一些监控信息。
1、列出所有节点的磁盘,并使用zap命令清除磁盘信息准备创建osd
#[root@ceph_node1 ceph]# ceph-deploy disk list ceph_node1
......
[ceph_node1][INFO ] Disk /dev/vda: 42.9 GB, 42949672960 bytes, 83886080 sectors
[ceph_node1][INFO ] Disk /dev/sda: 42.9 GB, 42949672960 bytes, 83886080 sectors
[ceph_node1][INFO ] Disk /dev/vdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
[root@ceph_node1 ceph]# ceph-deploy disk list ceph_node2
......
[ceph_node2][INFO ] Disk /dev/vda: 42.9 GB, 42949672960 bytes, 83886080 sectors
[ceph_node2][INFO ] Disk /dev/sda: 42.9 GB, 42949672960 bytes, 83886080 sectors
[ceph_node2][INFO ] Disk /dev/vdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
[root@ceph_node1 ceph]# ceph-deploy disk list ceph_node3
......
[ceph_node3][INFO ] Disk /dev/vda: 42.9 GB, 42949672960 bytes, 83886080 sectors
[ceph_node3][INFO ] Disk /dev/sda: 42.9 GB, 42949672960 bytes, 83886080 sectors
[ceph_node3][INFO ] Disk /dev/vdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
# 通过上面可以看出三个节点都有/dev/vdb磁盘,这是专门为ceph挂载的一个新磁盘,故这里使用/dev/vdb
[root@ceph_node1 ceph]# ceph-deploy disk zap ceph_node1 /dev/vdb
[root@ceph_node1 ceph]# ceph-deploy disk zap ceph_node2 /dev/vdb
[root@ceph_node1 ceph]# ceph-deploy disk zap ceph_node3 /dev/vdb
2、创建osd磁盘
[root@ceph_node1 ceph]# ceph-deploy osd create --data /dev/vdb ceph_node1
....
[ceph_deploy.osd][DEBUG ] Host ceph_node1 is now ready for osd use.
[root@ceph_node1 ceph]# ceph-deploy osd create --data /dev/vdb ceph_node2
....
[ceph_deploy.osd][DEBUG ] Host ceph_node2 is now ready for osd use.
[root@ceph_node1 ceph]# ceph-deploy osd create --data /dev/vdb ceph_node3
....
[ceph_deploy.osd][DEBUG ] Host ceph_node3 is now ready for osd use.
3、验证,可以看到下面的结果中有三个osd,data中一共有60G可用(3个20G合成了一个大磁盘)
[root@ceph_node1 ceph]# ceph -s
cluster:
id: 4cc2e905-73df-41e8-9d83-4a195435931d
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph_node1,ceph_node2,ceph_node3
mgr: ceph_node1(active), standbys: ceph_node2, ceph_node3
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
扩容osd
这里为了示例,故又在ceph_node3节点上添加了一块磁盘/dev/vdc
[root@ceph_node1 ceph]# ceph-deploy disk zap ceph_node3 /dev/vdc
[root@ceph_node1 ceph]# ceph-deploy osd create --data /dev/vdc ceph_node3
[root@ceph_node1 ceph]# ceph -s
cluster:
id: 4cc2e905-73df-41e8-9d83-4a195435931d
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph_node1,ceph_node2,ceph_node3
mgr: ceph_node1(active), standbys: ceph_node2, ceph_node3
osd: 4 osds: 4 up, 4 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 4.0 GiB used, 76 GiB / 80 GiB avail
📌 补充:如果是再加一个集群节点ceph_node4并添加一个磁盘/dev/vdb,那么需要按照如下操作进行
1、准备好ceph_node4基本环节后,安装ceph相关软件
[root@ceph_node4 ~]# yum install ceph ceph-radosgw -y
2、在ceph_node1 上同步配置到ceph_node4
[root@ceph_node1 ceph]# ceph-deploy admin ceph_node4
3、将ceph_node4的磁盘加入集群
[root@ceph_node1 ceph]# ceph-deploy disk zap ceph_node4 /dev/vdb
[root@ceph_node1 ceph]# ceph-deploy osd create --data /dev/vdb ceph_node4
删除osd
ceph和很多存储一样,增加磁盘(扩容)都比较方便,但要删除磁盘(裁减)会比较麻烦,不过一般也不会进行裁剪。
这里以删除ceph_node3节点上的osd.3磁盘为例
1、查看osd磁盘状态
[root@ceph_node1 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.07794 root default
-3 0.01949 host ceph_node1
0 hdd 0.01949 osd.0 up 1.00000 1.00000
-5 0.01949 host ceph_node2
1 hdd 0.01949 osd.1 up 1.00000 1.00000
-7 0.03897 host ceph_node3
2 hdd 0.01949 osd.2 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
2、先标记为out,标记后再次查看状态,可以发现权重置为0了,但状态还是up
[root@ceph_node1 ceph]# ceph osd out osd.3
marked out osd.3.
[root@ceph_node1 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.07794 root default
-3 0.01949 host ceph_node1
0 hdd 0.01949 osd.0 up 1.00000 1.00000
-5 0.01949 host ceph_node2
1 hdd 0.01949 osd.1 up 1.00000 1.00000
-7 0.03897 host ceph_node3
2 hdd 0.01949 osd.2 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 0 1.00000
3、再rm删除,但要先去osd.3对应的节点上停止ceph-osd服务,否则rm不了
[root@ceph_node3 ~]# systemctl stop ceph-osd@3.service
[root@ceph_node1 ceph]# ceph osd rm osd.3
removed osd.3
[root@ceph_node1 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.07794 root default
-3 0.01949 host ceph_node1
0 hdd 0.01949 osd.0 up 1.00000 1.00000
-5 0.01949 host ceph_node2
1 hdd 0.01949 osd.1 up 1.00000 1.00000
-7 0.03897 host ceph_node3
2 hdd 0.01949 osd.2 up 1.00000 1.00000
3 hdd 0.01949 osd.3 DNE 0
4、查看集群状态,可以发现有一条警告,没有在crush算法中删除,osd也恢复了三个,磁盘大小也从80G变为了60G,说明删除成功。
[root@ceph_node1 ceph]# ceph -s
cluster:
id: 4cc2e905-73df-41e8-9d83-4a195435931d
health: HEALTH_WARN
1 osds exist in the crush map but not in the osdmap
services:
mon: 3 daemons, quorum ceph_node1,ceph_node2,ceph_node3
mgr: ceph_node1(active), standbys: ceph_node2, ceph_node3
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
5、在crush算法中和auth验证中删除
[root@ceph_node1 ceph]# ceph osd crush remove osd.3
removed item id 3 name 'osd.3' from crush map
[root@ceph_node1 ceph]# ceph auth del osd.3
updated
6、在osd.3对应的节点上卸载
[root@ceph_node3 ~]# df -h |grep osd
tmpfs 7.8G 52K 7.8G 1% /var/lib/ceph/osd/ceph-2
tmpfs 7.8G 52K 7.8G 1% /var/lib/ceph/osd/ceph-3
[root@ceph_node3 ~]# umount /var/lib/ceph/osd/ceph-3
7、在osd.3对应的节点上删除osd磁盘产生的逻辑卷
[root@ceph_node3 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/vdb ceph-71c3d9a9-b631-4cf8-bd5f-f121ea2f8434 lvm2 a-- <20.00g 0
/dev/vdc ceph-169bac35-0405-424f-b1a6-26506a5fc195 lvm2 a-- <20.00g 0
[root@ceph_node3 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
ceph-169bac35-0405-424f-b1a6-26506a5fc195 1 1 0 wz--n- <20.00g 0
ceph-71c3d9a9-b631-4cf8-bd5f-f121ea2f8434 1 1 0 wz--n- <20.00g
[root@ceph_node3 ~]# lvremove ceph-169bac35-0405-424f-b1a6-26506a5fc195
Do you really want to remove active logical volume ceph-169bac35-0405-424f-b1a6-26506a5fc195/osd-block-26723f3d-d255-494d-bf98-e480ae74bfb4? [y/n]: y
Logical volume "osd-block-26723f3d-d255-494d-bf98-e480ae74bfb4" successfully removed
至此,就完全删除了。如果需要再加回来,按照上面的扩容osd操作即可。
Ceph 存储类型
块存储(RBD)
RBD 介绍
RBD即RADOS Block Device的简称,RBD块存储是最稳定且最常用的存储类型。RBD块设备类似磁盘可以被挂载。 RBD块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在Ceph集群的多个OSD中。如下是对Ceph RBD的理解。
- RBD 就是 Ceph 里的块设备,一个 4T 的块设备的功能和一个 4T 的 SATA 类似,挂载的 RBD 就可以当磁盘用;
- resizable:这个块可大可小;
- data striped:这个块在Ceph里面是被切割成若干小块来保存,不然 1PB 的块怎么存的下;
- thin-provisioned:精简置备,1TB 的集群是能创建无数 1PB 的块的。其实就是块的大小和在 Ceph 中实际占用大小是没有关系的,刚创建出来的块是不占空间,今后用多大空间,才会在 Ceph 中占用多大空间。举例:你有一个 32G 的 U盘,存了一个2G的电影,那么 RBD 大小就类似于 32G,而 2G 就相当于在 Ceph 中占用的空间 ;
块存储本质就是将裸磁盘或类似裸磁盘(lvm)设备映射给主机使用,主机可以对其进行格式化并存储和读取数据,块设备读取速度快但是不支持共享。
ceph可以通过内核模块和librbd库提供块设备支持。客户端可以通过内核模块挂在rbd使用,客户端使用rbd块设备就像使用普通硬盘一样,可以对其就行格式化然后使用;客户应用也可以通过librbd使用ceph块,典型的是云平台的块存储服务(如下图),云平台可以使用rbd作为云的存储后端提供镜像存储、volume块或者客户的系统引导盘等。
使用场景:
- 云平台(OpenStack做为云的存储后端提供镜像存储)
- K8s容器
- map成块设备直接使用
- ISCIS,安装Ceph客户端
RBD 常用命令
| 命令 | 功能 |
|---|---|
| rbd create | 创建块设备映像 |
| rbd ls | 列出 rbd 存储池中的块设备 |
| rbd info | 查看块设备信息 |
| rbd diff | 可以统计 rbd 使用量 |
| rbd map | 映射块设备 |
| rbd showmapped | 查看已映射块设备 |
| rbd remove | 删除块设备 |
| rbd resize | 更改块设备的大小 |
创建块存储并使用
1、建立存储池,并初始化
[root@ceph_node1 ~]# ceph osd pool create rbd_pool 10
pool 'rbd_pool' created
[root@ceph_node1 ~]# rbd pool init rbd_pool
2、创建一个块设备
[root@ceph_node1 ~]# rbd create volume1 --pool rbd_pool --size 10240
[root@ceph_node1 ~]# rbd ls rbd_pool
volume1
[root@ceph_node1 ~]# rbd info volume1 -p rbd_pool
rbd image 'volume1':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
id: 10e06b8b4567
block_name_prefix: rbd_data.10e06b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Tue Jun 23 15:29:29 2020
3、将创建的卷映射成块设备
[root@ceph_node1 ~]# rbd map rbd_pool/volume1
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable rbd_pool/volume1 object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
# 这里报错是因为rbd镜像的一些特性,OS kernel并不支持,所以映射报错
# 解决办法:禁用当前系统内核不支持的相关特性
[root@ceph_node1 ~]# rbd feature disable rbd_pool/volume1 object-map fast-diff deep-flatten
# 再次映射
[root@ceph_node1 ~]# rbd map rbd_pool/volume1
/dev/rbd0
4、查看映射
[root@ceph_node1 ~]# rbd showmapped
id pool image snap device
0 rbd_pool volume1 - /dev/rbd0
# 如果要取消映射使用 rbd unmap /dev/rbd0
5、格式化,挂载
[root@ceph_node1 ~]# mkfs.xfs /dev/rbd0
[root@ceph_node1 ~]# mount /dev/rbd
[root@ceph_node1 ~]# mount /dev/rbd0 /mnt/
📌 删除块存储方法
[root@ceph_node1 ~]# umount /mnt/
[root@ceph_node1 ~]# rbd unmap /dev/rbd0
[root@ceph_node1 ~]# rbd rm rbd_pool/volume1
文件存储(CephFs)
CephFs 介绍
Ceph File System (CephFS) 是与 POSIX 标准兼容的文件系统, 能够提供对 Ceph 存储集群上的文件访问. Jewel 版本 (10.2.0) 是第一个包含稳定 CephFS 的 Ceph 版本. CephFS 需要至少一个元数据服务器 (Metadata Server - MDS) daemon (ceph-mds) 运行, MDS daemon 管理着与存储在 CephFS 上的文件相关的元数据, 并且协调着对 Ceph 存储系统的访问。
对象存储的成本比起普通的文件存储还是较高,需要购买专门的对象存储软件以及大容量硬盘。如果对数据量要求不是海量,只是为了做文件共享的时候,直接用文件存储的形式好了,性价比高。
CephFs 架构
底层是核心集群所依赖的, 包括:
- OSDs (ceph-osd): CephFS 的数据和元数据就存储在 OSDs 上
- MDS (ceph-mds): Metadata Servers, 管理着 CephFS 的元数据
- Mons (ceph-mon): Monitors 管理着集群 Map 的主副本
Ceph 存储集群的协议层是 Ceph 原生的 librados 库, 与核心集群交互.
CephFS 库层包括 CephFS 库 libcephfs, 工作在 librados 的顶层, 代表着 Ceph 文件系统.最上层是能够访问 Ceph 文件系统的两类客户端.
创建CephFs 并使用
1、创建mds(也可以做多个mds实现HA),这里做三个mds
[root@ceph_node1 ceph]# ceph-deploy mds create ceph_node1 ceph_node2 ceph_node3
2、一个Ceph文件系统需要至少两个RADOS存储池(cephfs-data和cephfs-metadata),一个用于数据,一个用于源数据。进行创建者两个
[root@ceph_node1 ceph]# ceph osd pool create cephfs_data 128
pool 'ceph_data' created
[root@ceph_node1 ceph]# ceph osd pool create cephfs_metadata 64
pool 'cephfs_metadata' created
[root@ceph_node1 ceph]# ceph osd pool ls |grep cephfs
cephfs_metadata
cephfs_data
注:一般 metadata pool 可以从相对较少的 PGs 启动, 之后可以根据需要增加 PGs. 因为 metadata pool 存储着 CephFS 文件的元数据, 为了保证安全, 最好有较多的副本数. 为了能有较低的延迟, 可以考虑将 metadata 存储在 SSDs 上.
3、创建一个CephFs
[root@ceph_node1 ceph]# ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 3 and data pool 4
[root@ceph_node1 ceph]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
# 验证至少有一个MDS已经进入 Active 状态
[root@ceph_node1 ceph]# ceph fs status cephfs
cephfs - 0 clients
======
+------+--------+------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------+---------------+-------+-------+
| 0 | active | ceph_node3 | Reqs: 0 /s | 10 | 13 |
+------+--------+------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs_metadata | metadata | 2286 | 17.9G |
| cephfs_data | data | 0 | 17.9G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
| ceph_node1 |
| ceph_node2 |
+-------------+
MDS version: ceph version 13.2.10 (564bdc4ae87418a232fc901524470e1a0f76d641) mimic (stable)
4、在Monitor 上,创建一个用户,用于访问CephFs,cephx配置参考
[root@ceph_node1 ceph]# ceph auth get-or-create client.cephfs mon 'allow r' mds 'allow rw' osd 'allow rw pool=cephfs_data, allow rw pool=cephfs_metadata'
[client.cephfs]
key = AQBfwvFeuRDTIRAAAk5iuuzUlfBBDGPblPJT/w==
5、验证key是否生效
[root@ceph_node1 ceph]# ceph auth get client.cephfs
exported keyring for client.cephfs
[client.cephfs]
key = AQBfwvFeuRDTIRAAAk5iuuzUlfBBDGPblPJT/w==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs_data, allow rw pool=cephfs_metadata"
6、检查CephFs和mds状态
[root@ceph_node1 ceph]# ceph mds stat
cephfs-1/1/1 up {0=ceph_node3=up:active}, 2 up:standby
[root@ceph_node1 ceph]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@ceph_node1 ceph]# ceph fs status
cephfs - 0 clients
======
+------+--------+------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------+---------------+-------+-------+
| 0 | active | ceph_node3 | Reqs: 0 /s | 10 | 13 |
+------+--------+------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs_metadata | metadata | 2286 | 17.9G |
| cephfs_data | data | 0 | 17.9G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
| ceph_node1 |
| ceph_node2 |
+-------------+
MDS version: ceph version 13.2.10 (564bdc4ae87418a232fc901524470e1a0f76d641) mimic (stable)
✏️ 以 kernel client 形式挂载 CephFs
这里在另外一台新的客户端进行挂载示例
1、创建一个挂载目录
[root@localhost ~]# mkdir /cephfs
2、挂载目录
[root@localhost ~]# mount -t ceph 192.168.3.27:6789,192.168.3.60:6789,192.168.3.95:6789:/ /cephfs/ -o name=cephfs,secret=AQBfwvFeuRDTIRAAAk5iuuzUlfBBDGPblPJT/w==
3、自动挂载
[root@localhost ~]# echo "AQBfwvFeuRDTIRAAAk5iuuzUlfBBDGPblPJT/w==" > /etc/ceph/cephfs.key
[root@localhost ~]# echo "192.168.3.27:6789,192.168.3.60:6789,192.168.3.95:6789:/ /cephfs ceph name=cephfs,secretfile=/etc/ceph/cephfs.key,_netdev,noatime 0 0" | tee -a /etc/fstab
4、验证是否挂载成功
[root@localhost ~]# stat -f /cephfs
File: "/cephfs"
ID: 1ca341d1f5d2ea27 Namelen: 255 Type: ceph
Block size: 4194304 Fundamental block size: 4194304
Blocks: Total: 4605 Free: 4605 Available: 4605
Inodes: Total: 0 Free: -1
✏️ 以 FUSE client 形式挂载 CephFs
1、安装ceph-common和ceph-fuse
[root@localhost ~]# yum install ceph-common ceph-fuse -y
2、将集群的ceph.conf拷贝到客户端
[root@ceph_node1 ~]# scp /etc/ceph/ceph.conf 192.168.3.97:/etc/ceph/
[root@localhost ~]# chmod 644 /etc/ceph/ceph.conf
3、在ceph_node1节点上生成客户端密钥,并拷贝到客户端/etc/ceph目录
[root@ceph_node1 ~]# ceph auth get-or-create client.cephfs mon 'allow r' mds 'allow rw' osd 'allow rw pool=cephfs_data, allow rw pool=cephfs_metadata' -o /etc/ceph/ceph.client.cephfs.keyring
[root@ceph_node1 ~]# scp /etc/ceph/ceph.client.cephfs.keyring 192.168.3.97:/etc/ceph/
[root@localhost ~]# chmod 644 /etc/ceph/ceph.client.cephfs.keyring
3、使用ceph-fuse挂载 CephFs
[root@localhost ~]# ceph-fuse --keyring /etc/ceph/ceph.client.cephfs.keyring --name client.cephfs -m 192.168.3.27:6789,192.168.3.60:6789,192.168.3.95:6789 /cephfs/
[root@localhost ~]# df -h |grep cephfs
ceph-fuse 18G 0 18G 0% /cephfs
4、自动挂载
# echo "none /cephfs fuse.ceph ceph.id=cephfs[,ceph.conf=/etc/ceph/ceph.conf],_netdev,defaults 0 0"| sudo tee -a /etc/fstab
或
# echo "id=cephfs,conf=/etc/ceph/ceph.conf /mnt/ceph2 fuse.ceph _netdev,defaults 0 0"| sudo tee -a /etc/fstab
Ceph Dashboard
Ceph 的监控可视化界面方案很多----grafana、Kraken。但是从Luminous开始,Ceph 提供了原生的Dashboard功能,通过Dashboard可以获取Ceph集群的各种基本状态信息。
mimic版 (nautilus版) dashboard 安装。如果是 (nautilus版) 需要安装 ceph-mgr-dashboard
配置Dashboard
1、查看ceph状态,找到active的mgr
[root@ceph_node1 ~]# ceph -s
cluster:
id: 4cc2e905-73df-41e8-9d83-4a195435931d
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph_node1,ceph_node2,ceph_node3
mgr: ceph_node1(active), standbys: ceph_node3, ceph_node2
mds: cephfs-1/1/1 up {0=ceph_node3=up:active}, 2 up:standby
osd: 3 osds: 3 up, 3 in
data:
pools: 3 pools, 202 pgs
objects: 24 objects, 3.5 KiB
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs: 202 active+clean
2、生成并安装自签名的证书
[root@ceph_node1 ~]# ceph dashboard create-self-signed-cert
Self-signed certificate created
3、生产key pair,并配置给ceph mgr
[root@ceph_node1 ~]# mkdir mgr-dashboard
[root@ceph_node1 ~]# cd mgr-dashboard/
[root@ceph_node1 mgr-dashboard]# openssl req -new -nodes -x509 -subj "/O=IT/CN=ceph-mgr-dashboard" -days 3650 -keyout dashboard.key -out dashboard.crt -extensions v3_ca
Generating a 2048 bit RSA private key
.........................................................+++
....................................................+++
writing new private key to 'dashboard.key'
-----
[root@ceph_node1 mgr-dashboard]# ls
dashboard.crt dashboard.key
4、重启下mgr dashboard
[root@ceph_node1 mgr-dashboard]# ceph mgr module disable dashboard
[root@ceph_node1 mgr-dashboard]# ceph mgr module enable dashboard
5、在ceph active mgr上配置server addr和port
若使用默认的8443端口,则可跳过该步骤
[root@ceph_node1 ~]# ceph config set mgr mgr/dashboard/server_addr 192.168.3.27
[root@ceph_node1 ~]# ceph config set mgr mgr/dashboard/server_port 8080
[root@ceph_node1 ~]# ceph mgr services
{
"dashboard": "https://ceph_node1:8443/"
}
6、生成登陆认证的用户名和密码
[root@ceph_node1 ~]# ceph dashboard set-login-credentials admin admin@123
Username and password updated
7、web页面访问
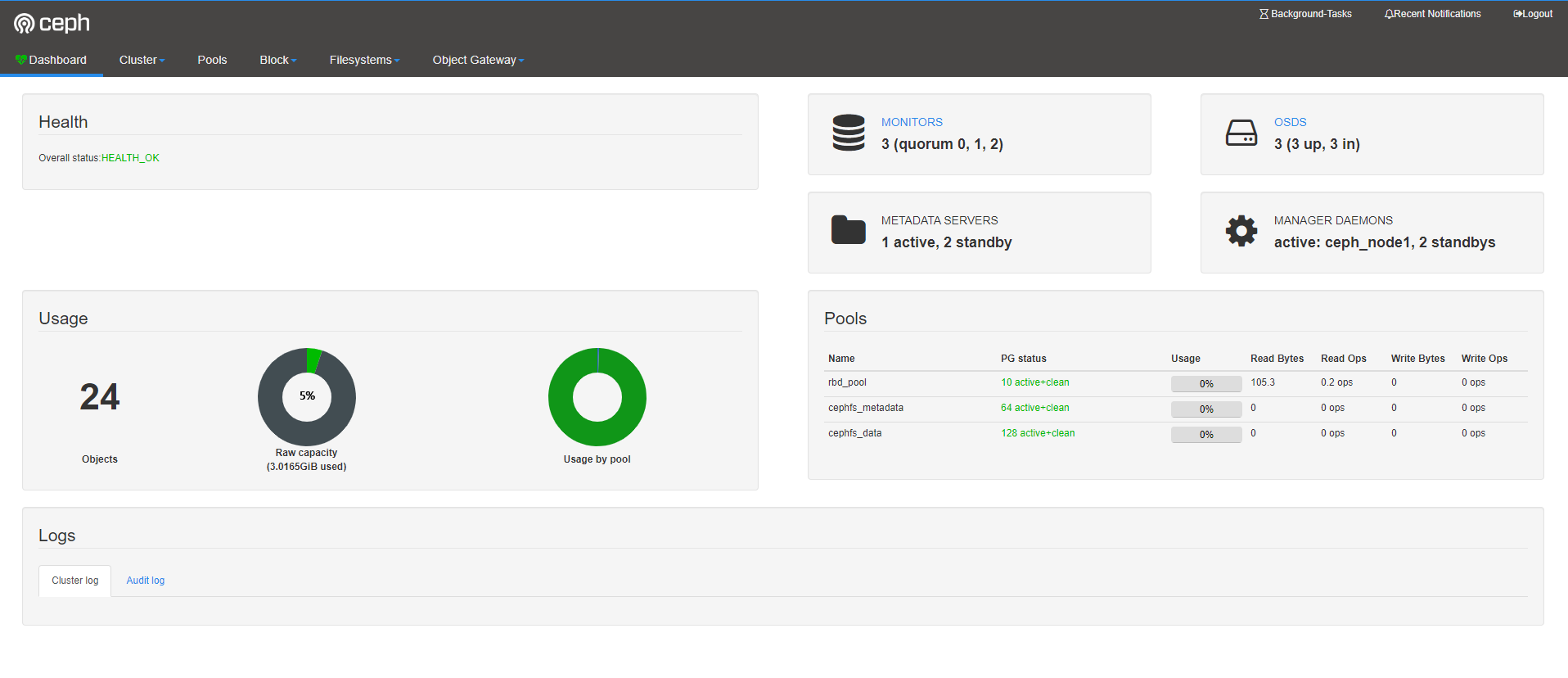

 浙公网安备 33010602011771号
浙公网安备 33010602011771号