Python中常用数据类型结构的基本操作(字典,列表,元祖,集合等)[持续更新]
数据结构:就是计算机存储、组织数据的结构。
四种常用的数据结构
列表(LIST)
集合(set)
元组(Tuple)
字典(Dictionary)
字典dict常用操作


什么是字典 字典(Dictionary)是Python中的内置数据结构 字典非常适合表达结构化数据 { '姓名':'汪峰','性别':'男' '绩效评级':'A','工资':'1000' } 字典的特点 采用键(KEY):值(VALUE)形式表达数据 KEY不允许重复。 可以运行时修改,动态调整存储空间。 创建字典的两种方式 使用{}创建字典 dict1 = {} #空的字典 print(type(dict1)) dict2 = {'name':'汪峰' , 'sex':'男' , 'hiredate':'1997-10-20' , 'grade':'A' , 'job':'销售' , 'salary':1000 , 'welfare':100 } 使用dict函数创建字典 dict3 = dict(name='汪峰',sex='男'。。。。。) dict4 = dict.fromkeys(['name' , 'sex' , 'hiredate' , 'grade']) print(dict4) {'name': None, 'sex':None ,'hiredate':None ,'grade':None} 如果写成 dict4 = dict.fromkeys(['name' , 'sex' , 'hiredate' , 'grade':'N/A']) print(dict4) 默认值None会变成N/A 字典的取值操作 employee = {'name':'汪峰' , 'sex':'男' , 'hiredate':'1997-10-20' , 'grade':'A' , 'job':'销售' , 'salary':1000 , 'welfare':100 } #字典的取值1 name = employee['name'] #字典的取值2 name = employee.get('name') print(employee.get('dept' , '其他部门')) 如果没有字典中没有dept这个KEY,用get 可以使用设定的默认值‘其他部门’ #in 成员运算符 print('name' in employee) #TRUE print('dept' in employee) #FALSE # 遍历字典1 for key in employee: v = employee[key] print(v) #遍历字典2 for k,v in employee: print(k,v) //会打印出所有键值对 # 字典的更新操作 employee = {'name':'汪峰' , 'sex':'男' , 'hiredate':'1997-10-20' , 'grade':'A' , 'job':'销售' , 'salary':1000 , 'welfare':100 } #对单个KV进行更新 employee['grade'] = 'B' #对多个KV进行更新 employee.update(salary = 1200,welfare = 150) # 字典的新增操作与更新操作完全相同,有则更新,无则新增的原则。 employee['dept'] = '研发部' employee.update(dept='财务部') # 字典的删除操作 #1,pop 删除指定kv employee.pop('dept') #2,popitem 删除最后一个kv kv = employee.popitem() #3,clear 清空字典 employee.clear() # 字典的常用操作 # 1,setdefault为字典设置默认值,如果某个KEY已经存在则忽略默认值,如果不存在则设置 emp1 = {'name':'jack' , 'grade':''B} emp2 = {'name':'lily' } emp2.setdefault('grade' ,'C') //比下面代码效率高 # if 'grade' not in emp2 # emp2['grade'] = 'C' #2,获取字典的视图 #(1)KEYS 代表获取所有的键 ks = emp1.keys() print(ks) //返回一个视图 dict_keys(['name','grade']) #(2) values 代表获取所有的值 vs= emp1.values() print(vs) //返回一个视图 dict_values # (3)items 代表获取所有的键值对 its = emp1.items() print(its) //返回一个视图 dict_items 视图会随着emp1原始数据的变化而动态变化。 # 3,利用字典格式化字符串 #老版本的字符串格式化 emp_str = "姓名:%(name)s,评级:%(grade)s,入职时间:%(hiredate) s" %emp1 #新版本 emp_str1 = "姓名:{name}, 评级:{grade}, 入职时间:{hiredate}".format_map(emp1) # 散列值(HASH) h1 = hash(“abc”) print(h1) hash散列值,接近唯一ID值 特点1,被hash的值有一点变化,生成的hash值就完全不同。 2,在同一次运行中,被hash的值相同,生成hash值就一定相同。 3,每运行一次,hash值就会重新生成一次。 #字典的存储原理 把KEY进行哈希运算,生成一个的哈希值作为内存地址,在这个地址中存储VALUE 效率高,建议结构化数据使用。 比如,name, hash(name) = 837181093 。 837181093这个内存中存储 “张三 #字典在项目中的应用 #两个独立系统之间进行数据传输,比如人力资源系统和财务系统,通过格式化的字 符串导入解析。 员工数据.TXT 7782,CLARK, MANAGER, SALES 5000$ 7934, MILLER, SALESMAN, SALES, 3000$ 7369, SMITH, ANALYST, RESEARCH, 2000 每一组用$分割 # 处理员工数据 source = "7782,CLARK, MANAGER, SALES 5000$7934, MILLER, SALESMAN, SALES, 3000$7369, SMITH, ANALYST, RESEARCH, 2000" employee_list = source.split("$") print(employee_list) #保存所有解析后的员工信息,key是员工编号,value是包含完整员工信息的字典 all_emp = {} for i in range(0,len(employee_list)) //range函数 range(start, stop[, step]) 创建一个整数列表,一般用在 for 循环中。 e = employee_list[i].split(",") #创建员工字典 employee = {"no" : e[0], "name" : e[1], "job":e[2], "department" : e[3], "salary" : e[4]} all_emp[employee['no']] = employee #生成的数据形式{'7782' : {'no':'7782','name':'clark','job':'manager','department':'sales','salary':5000}, '7934'.........} //这样可以通过get员工编号取得这个员工全部信息 empno = input("请输入员工编号:") emp = all_emp.get(empno) print("工号:{no},姓名:{name},岗位:{job},部门:{deparment},工资:{salary}".format_map(emp))
字典也是 Python 提供的一种常用的数据结构,它用于存放具有映射关系的数据。
比如有份成绩表数据,语文:79,数学:80,英语:92,这组数据看上去像两个列表,但这两个列表的元素之间有一定的关联关系。如果单纯使用两个列表来保存这组数据,则无法记录两组数据之间的关联关系。
为了保存具有映射关系的数据,Python 提供了字典,字典相当于保存了两组数据,其中一组数据是关键数据,被称为 key;另一组数据可通过 key 来访问,被称为 value。形象地看,字典中 key 和 value 的关联关系如图 1 所示:
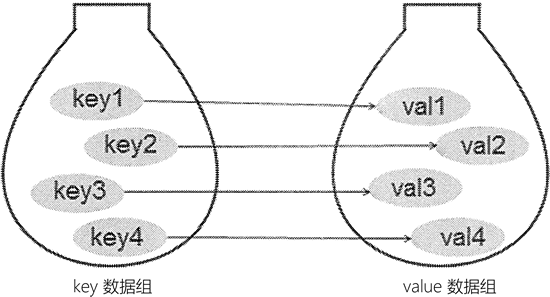
图 1 字典保存的关联数据
由于字典中的 key 是非常关键的数据,而且程序需要通过 key 来访问 value,因此字典中的 key 不允许重复。
程序既可使用花括号语法来创建字典,也可使用 dict() 函数来创建字典。实际上,dict 是一种类型,它就是 Python 中的字典类型。
在使用花括号语法创建字典时,花括号中应包含多个 key-value 对,key 与 value 之间用英文冒号隔开;多个 key-value 对之间用英文逗号隔开。
如下代码示范了使用花括号语法创建字典:
scores = {'语文': 89, '数学': 92, '英语': 93}
print(scores)
# 空的花括号代表空的dict
empty_dict = {}
print(empty_dict)
# 使用元组作为dict的key
dict2 = {(20, 30):'good', 30:'bad'}
print(dict2)
上面程序中第 1 行代码创建了一个简单的 dict,该 dict 的 key 是字符串,value 是整数;第 4 行代码使用花括号创建了一个空的字典;第 7 行代码创建的字典中第一个 key 是元组,第二个 key 是整数值,这都是合法的。
需要指出的是,元组可以作为 dict 的 key,但列表不能作为元组的 key。这是由于 dict 要求 key 必须是不可变类型,但列表是可变类型,因此列表不能作为元组的 key。
在使用 dict() 函数创建字典时,可以传入多个列表或元组参数作为 key-value 对,每个列表或元组将被当成一个 key-value 对,因此这些列表或元组都只能包含两个元素。例如如下代码:
vegetables = [('celery', 1.58), ('brocoli', 1.29), ('lettuce', 2.19)] # 创建包含3组key-value对的字典 dict3 = dict(vegetables) print(dict3) # {'celery': 1.58, 'brocoli': 1.29, 'lettuce': 2.19} cars = [['BMW', 8.5], ['BENS', 8.3], ['AUDI', 7.9]] # 创建包含3组key-value对的字典 dict4 = dict(cars) print(dict4) # {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
如果不为 dict() 函数传入任何参数,则代表创建一个空的字典。例如如下代码:
# 创建空的字典 dict5 = dict() print(dict5) # {}
还可通过为 dict 指定关键字参数创建字典,此时字典的 key 不允许使用表达式。例如如下代码:
# 使用关键字参数来创建字典 dict6 = dict(spinach = 1.39, cabbage = 2.59) print(dict6) # {'spinach': 1.39, 'cabbage': 2.59}
上面粗体字代码在创建字典时,其 key 直接写 spinach、cabbage,不需要将它们放在引号中。
字典的基本用法
对于初学者而言,应牢记字典包含多个 key-value 对,而 key 是字典的关键数据,因此程序对字典的操作都是基于 key 的。基本操作如下:
通过 key 访问 value 。 通过 key 添加 key-value 对。 通过 key 删除 key-value 对。 通过 key 修改 key-value 对。 通过 key 判断指定 key-value 对是否存在。 通过 key 访问 value 使用的也是方括号语法,就像前面介绍的列表和元组一样,只是此时在方括号中放的是 key,而不是列表或元组中的索引。
如下代码示范了通过 key 访问 value:
scores = {'语文': 89}
# 通过key访问value
print(scores['语文'])
如果要为 dict 添加 key-value 对,只需为不存在的 key 赋值即可:
# 对不存在的key赋值,就是增加key-value对 scores['数学'] = 93 scores[92] = 5.7 print(scores) # {'语文': 89, '数学': 93, 92: 5.7}
如果要删除宇典中的 key-value 对,则可使用 del 语句。例如如下代码:
# 使用del语句删除key-value对 del scores['语文'] del scores['数学'] print(scores) # {92: 5.7}
如果对 dict 中存在的 key-value 对赋值,新赋的 value 就会覆盖原有的 value,这样即可改变 dict 中的 key-value 对。例如如下代码:
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 对存在的key-value对赋值,改变key-value对
cars['BENS'] = 4.3
cars['AUDI'] = 3.8
print(cars) # {'BMW': 8.5, 'BENS': 4.3, 'AUDI': 3.8}
如果要判断字典是否包含指定的 key,则可以使用 in 或 not in 运算符。需要指出的是,对于 dict 而言,in 或 not in 运算符都是基于 key 来判断的。例如如下代码:
# 判断cars是否包含名为'AUDI'的key print('AUDI' in cars) # True # 判断cars是否包含名为'PORSCHE'的key print('PORSCHE' in cars) # False print('LAMBORGHINI' not in cars) # True
通过上面介绍可以看出,字典的 key 是它的关键。换个角度来看,字典的 key 就相当于它的索引,只不过这些索引不一定是整数类型,字典的 key 可以是任意不可变类型。
可以这样说,字典相当于索引是任意不可变类型的列表:而列表则相当于 key 只能是整数的字典。因此,如果程序中要使用的字典的 key 都是整数类型,则可考虑能否换成列表。
此外,还有一点需要指出,列表的索引总是从 0 开始、连续增大的;但字典的索引即使是整数类型,也不需要从 0 开始,而且不需要连续。因此,列表不允许对不存在的索引赋值:但字典则允许直接对不存在的 key 赋值,这样就会为字典增加一个 key-value 对。
列表不允许对不存在的索引赋值,但字典则允许直接对不存在的 key 赋值。
字典的常用方法
字典由 dict 类代表,因此我们同样可使用 dir(dict) 来查看该类包含哪些方法。在交互式解释器中输入 dir(dict) 命令,将看到如下输出结果:
>>> dir(dict) ['clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values'] >>>
下面介绍 dict 的一些方法。
clear()方法
clear() 用于清空字典中所有的 key-value 对,对一个字典执行 clear() 方法之后,该字典就会变成一个空字典。例如如下代码:
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
print(cars) # {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 清空cars所有key-value对
cars.clear()
print(cars) # {}
get()方法
get() 方法其实就是根据 key 来获取 value,它相当于方括号语法的增强版,当使用方括号语法访问并不存在的 key 时,字典会引发 KeyError 错误;但如果使用 get() 方法访问不存在的 key,该方法会简单地返回 None,不会导致错误。例如如下代码:
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 获取'BMW'对应的value
print(cars.get('BMW')) # 8.5
print(cars.get('PORSCHE')) # None
print(cars['PORSCHE']) # KeyError
update()方法
update() 方法可使用一个字典所包含的 key-value 对来更新己有的字典。在执行 update() 方法时,如果被更新的字典中己包含对应的 key-value 对,那么原 value 会被覆盖;如果被更新的字典中不包含对应的 key-value 对,则该 key-value 对被添加进去。例如如下代码:
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
cars.update({'BMW':4.5, 'PORSCHE': 9.3})
print(cars)
从上面的执行过程可以看出,由于被更新的 dict 中己包含 key 为“AUDI”的 key-value 对,因此更新时该 key-value 对的 value 将被改写;但如果被更新的 dict 中不包含 key 为“PORSCHE”的 key-value 对,那么更新时就会为原字典增加一个 key-value 对。
items()、keys()、values()
items()、keys()、values() 分别用于获取字典中的所有 key-value 对、所有 key、所有 value。这三个方法依次返回 dict_items、dict_keys 和 dict_values 对象,Python 不希望用户直接操作这几个方法,但可通过 list() 函数把它们转换成列表。如下代码示范了这三个方法的用法:
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 获取字典所有的key-value对,返回一个dict_items对象
ims = cars.items()
print(type(ims)) # <class 'dict_items'>
# 将dict_items转换成列表
print(list(ims)) # [('BMW', 8.5), ('BENS', 8.3), ('AUDI', 7.9)]
# 访问第2个key-value对
print(list(ims)[1]) # ('BENS', 8.3)
# 获取字典所有的key,返回一个dict_keys对象
kys = cars.keys()
print(type(kys)) # <class 'dict_keys'>
# 将dict_keys转换成列表
print(list(kys)) # ['BMW', 'BENS', 'AUDI']
# 访问第2个key
print(list(kys)[1]) # 'BENS'
# 获取字典所有的value,返回一个dict_values对象
vals = cars.values()
# 将dict_values转换成列表
print(type(vals)) # [8.5, 8.3, 7.9]
# 访问第2个value
print(list(vals)[1]) # 8.3
从上面代码可以看出,程序调用字典的 items()、keys()、values() 方法之后,都需要调用 list() 函数将它们转换为列表,这样即可把这三个方法的返回值转换为列表。
在 Python 2.x 中,items()、keys()、values() 方法的返回值本来就是列表,完全可以不用 list() 函数进行处理。当然,使用 list() 函数处理也行,列表被处理之后依然是列表。
pop方法
pop() 方法用于获取指定 key 对应的 value,并删除这个 key-value 对。如下方法示范了 pop() 方法的用法:
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
print(cars.pop('AUDI')) # 7.9
print(cars) # {'BMW': 8.5, 'BENS': 8.3}
此程序中,第 2 行代码将会获取“AUDI”对应的 value,并删除该 key-value 对。
popitem()方法
popitem() 方法用于随机弹出字典中的一个 key-value 对。
此处的随机其实是假的,正如列表的 pop() 方法总是弹出列表中最后一个元素,实际上字典的 popitem() 其实也是弹出字典中最后一个 key-value 对。由于字典存储 key-value 对的顺序是不可知的,因此开发者感觉字典的 popitem() 方法是“随机”弹出的,但实际上字典的 popitem() 方法总是弹出底层存储的最后一个 key-value 对。
如下代码示范了 popitem() 方法的用法:
cars = {'AUDI': 7.9, 'BENS': 8.3, 'BMW': 8.5}
print(cars)
# 弹出字典底层存储的最后一个key-value对
print(cars.popitem()) # ('AUDI', 7.9)
print(cars) # {'BMW': 8.5, 'BENS': 8.3}
由于实际上 popitem 弹出的就是一个元组,因此程序完全可以通过序列解包的方式用两个变量分别接收 key 和 value。例如如下代码:
# 将弹出项的key赋值给k、value赋值给v k, v = cars.popitem() print(k, v) # BENS 8.3
setdefault()方法
setdefault() 方法也用于根据 key 来获取对应 value 的值。但该方法有一个额外的功能,即当程序要获取的 key 在字典中不存在时,该方法会先为这个不存在的 key 设置一个默认的 value,然后再返回该 key 对应的 value。
总之,setdefault() 方法总能返回指定 key 对应的 value;如果该 key-value 对存在,则直接返回该 key 对应的 value;如果该 key-value 对不存在,则先为该 key 设置默认的 value,然后再返回该 key 对应的 value。
如下代码示范了 setdefault() 方法的用法:
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 设置默认值,该key在dict中不存在,新增key-value对
print(cars.setdefault('PORSCHE', 9.2)) # 9.2
print(cars)
# 设置默认值,该key在dict中存在,不会修改dict内容
print(cars.setdefault('BMW', 3.4)) # 8.5
print(cars)
fromkeys()方法
fromkeys() 方法使用给定的多个 key 创建字典,这些 key 对应的 value 默认都是 None;也可以额外传入一个参数作为默认的 value。该方法一般不会使用字典对象调用(没什么意义),通常会使用 dict 类直接调用。例如如下代码:
# 使用列表创建包含2个key的字典 a_dict = dict.fromkeys(['a', 'b']) print(a_dict) # {'a': None, 'b': None} # 使用元组创建包含2个key的字典 b_dict = dict.fromkeys((13, 17)) print(b_dict) # {13: None, 17: None} # 使用元组创建包含2个key的字典,指定默认的value c_dict = dict.fromkeys((13, 17), 'good') print(c_dict) # {13: 'good', 17: 'good'}
使用字典格式化字符串
前面章节介绍过,在格式化字符串时,如果要格式化的字符串模板中包含多个变量,后面就需要按顺序给出多个变量,这种方式对于字符串模板中包含少量变量的情形是合适的,但如果字符串模板中包含大量变量,这种按顺序提供变量的方式则有些不合适。可改为在字符串模板中按 key 指定变量,然后通过字典为字符串模板中的 key 设置值。
例如如下程序:
# 字符串模板中使用key temp = '教程是:%(name)s, 价格是:%(price)010.2f, 出版社是:%(publish)s' book = {'name':'Python基础教程', 'price': 99, 'publish': 'C语言中文网'} # 使用字典为字符串模板中的key传入值 print(temp % book) book = {'name':'C语言小白变怪兽', 'price':159, 'publish': 'C语言中文网'} # 使用字典为字符串模板中的key传入值 print(temp % book)
运行上面程序,可以看到如下输出结果:
教程是:Python基础教程, 价格是:0000099.00, 出版社是:C语言中文网
教程是:C语言小白变怪兽, 价格是:0000159.00, 出版社是:C语言中文网
列表list常用操作
1,列表(list) 列表中的数据按放入顺序排列。 列表有正序和倒序两种索引。 正序是从0开始,0,1,2.。。。倒序从列表最后一个元素开始,-1,-2,-3.。。。 列表可存储任意类型数据,且可以重复。 创建列表 变量名 = [元素1,元素2,。。。。] 列表取值 变量 = 列表变量[索引值] list = [‘张三’,‘李四’,‘王五’, '赵六' , ‘钱七’ ] lisi = list[1] 或者 list[-2] print(lisi) //打印出来是 李四 范围取值 列表变量 = 原列表变量[起始索引:结束索引] 在Python中列表范围取值是“左闭右开”,比如 list1 = list[1:4] print(list1) #打印结果是 ['李四','王五','赵六'] 。包括了左边索引1的李四,但没包括右边索引4的赵六。 获取指定元素索引值 index函数用于获取索引值 list.index ('赵六') 遍历列表 for...in...语句 专门用于遍历列表、元组等数据结构 for 迭代变量 in 可迭代对象 例子:编历得到正反索引 persons = ['张三','赵六','李四','王五','赵六','钱七','孙八'] count = len(persons) print(count) i = 0 for p in persons: if p == '赵六': ri = count * -1 + i print(p, i, ri) i += 1 另一种方法 i = 0 while i < len(persons): p = persons[i] if p == '赵六': ri = count * -1 + i i += 1 列表的反转与排序 persons = ['张三','赵六','李四','王五','赵六','钱七','孙八'] persons.reverse() #reverse方法用于反转列表 numbers = [28,32,14,12,53,42] numbers.sort() #sort方法用于排序,默认是升序 numbers.sort(reverse=True) #reverse参数表示降序排列 扩展知识 冒泡排序:多次循环比较 列表的新增、修改、删除操作 list.append(新元素) l ist.insert(索引,新元素) list[索引] = 新值 list[起始索引:结束索引] = 新列表 list.remove(元素) list.pop(索引) 按索引删除指定元素 项目中的使用场景,多维嵌套列表 [[姓名,年龄,工资], [姓名,年龄,工资], [姓名,年龄,工资]] #str = "张三,30,3000" #l = str.split(",") split方法把字符串按照分隔符切割,放入列表 emp_list = [ ] info = input("请输入员工信息:") if info == "": print("程序结束") break info_list = info.split(",") if len(info_list) !=3: print("输入格式错误,请重新输入") continue emp_list.append(info_list) for emp in emp_list: print("{n},年龄:{a},工资:{s}".format(n = emp[0],a = emp[1], s = emp[2])) 列表的其他常用方法和技巧 persons = ['张三','赵六','李四','王五','赵六','钱七','孙八'] cnt = persons.count('赵六') #统计出现次数 # 追加操作 单个追加或追加列表用append方法 多个用 .extend(['','','']) 判断数据是否在列表中存在,返回TRUE或FALSE #in(成员运算符) b = '张三' in persons #copy函数用于列表的复制 persons1 = persons.copy() #clear 函数用于清空列表 persons.clear() 列表存储数据的问题 列表在表达结构化数据时语义不明确 结构化数据是指有明确属性,明确表示规则的数据 比如,['汪峰','男','A','1000','50'] A,1000,50难以理解意义 结构化数据在python中哦一般用字典。
使用遍历在列表(list)中添加字典(dict)常用方法和常见错误
错误示例:
nid = "1,2" print(nid.split(',')) mydict = {} datas = [] for i in nid.split(','): mydict["id"] = str(i) mydict["checked"] = True datas.append(mydict) print(str(datas)) 运行结果: ['1', '2'] [{'id': '2', 'checked': True}, {'id': '2', 'checked': True}]
错误原因:
空dict声明放在了循环外面,每次都是操作这一个实例中的id和checked地址,每次添加的都是同一个内存到list中去了,mydict每次写入的时候改变了内存中的value,但是地址不变,即是,创建了一次内存空间,只会不断的改变value了,添加到list中的时候value已经改了。所以需要在for循环里面去每次循环都创建一个空的dict,以保证之前添加过的不会被改变。
正确代码:
nid = "1,2" print(nid.split(',')) datas = [] for i in nid.split(','): mydict = {} mydict["id"] = str(i) mydict["checked"] = True datas.append(mydict) print(str(datas)) 运行结果: ['1', '2'] [{'id': '1', 'checked': True}, {'id': '2', 'checked': True}]


 浙公网安备 33010602011771号
浙公网安备 33010602011771号