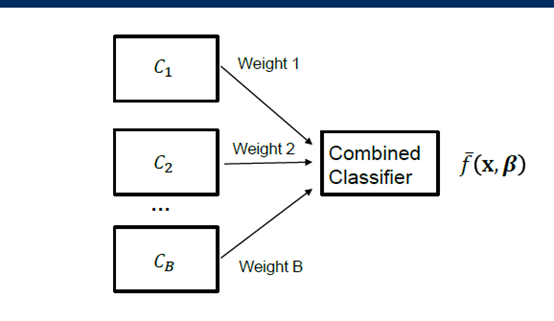
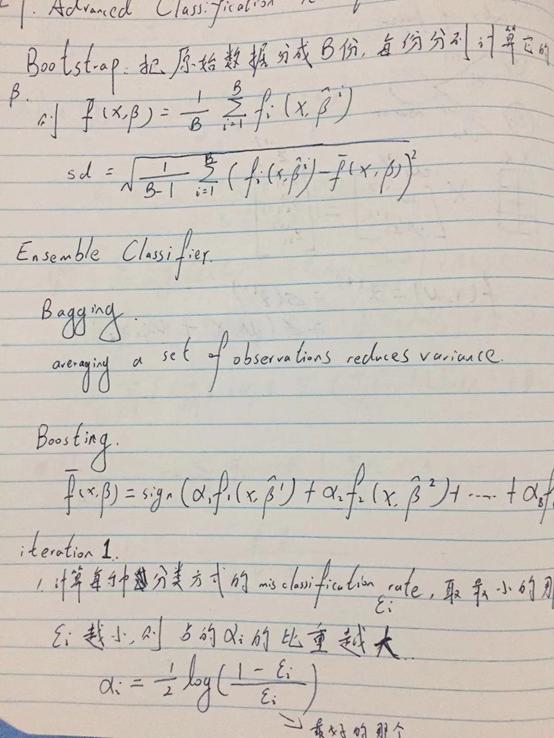集成算法
- bagging
把训练集分为B个(可重复),即bootstrap数据集,然后分别求出其中的beta值然后进行加权平均。如果每个子集的错误都是独立的,这种方法就可以减小误差。Variance一定减小。
在决策树方面,这种方法尤为有效。缺点是解释性降低。代表算法有random forest。
- boosting
每一次的迭代都要在上一次的基础之上,而不是一次性完成所有的数据集分类。后一步的分类需要关注更多(权重更大)在那些前一步分类不正确的地方上面。最后根据权重来投票决出最终结果。代表算法有adaboost 以及现阶段最为有效的XGBboost和Lgboost