


性能分析指标
转自:
https://www.cnblogs.com/TestWorld/p/5415690.html
https://testerhome.com/articles/20744
一、用户事务分析
用户事务分析是站在用户角度进行的基础性能分析。
1、Transation Sunmmary(事务综述)
对事务进行综合分析是性能分析的第一步,通过分析测试时间内用户事务的成功与失败情况,可以直接判断出系统是否运行正常。
2、Average Transaciton Response Time(事务平均响应时间)
“事务平均响应时间”显示的是测试场景运行期间的每一秒内事务执行所用的平均时间,通过它可以分析测试场景运行期间应用系统的性能走向。根据该图,可以定位出现性能问题的转折点。
说明:随着测试时间的变化,系统处理事务的速度开始逐渐变慢,这说明应用系统随着投产时间的变化,整体性能将会有下降的趋势。
当事务响应时间的曲线开始由缓慢上升,然后处于平衡,最后慢慢下降,可能情况:
1)曲线图持续上升,表明系统的处理能力在下降,事务的响应时间变长;
2)持续平衡,表明并发用户数达到一定数量,再多请求也可能接受不了,等待;
3)当事务的响应时间在下降,表明并发用户的数量在慢慢减少,事务的请求数也在减少。
如果系统没有出现下降,但响应时间越来越长,直到系统瘫痪,引起原因可能如下:
1)程序中用户数连接未做限制,导致请求数不断上升,响应时间不断变长;
2)内存泄露。
3、Transactions per Second(每秒通过事务数,简写TPS)
“每秒通过事务数/TPS”显示在场景运行的每一秒钟,每个事务通过、失败以及停止的数量,使考查系统性能的一个重要参数。通过它可以确定系统在任何给定时刻的时间事务负载。分析TPS主要是看曲线的性能走向。将它与平均事务响应时间进行对比,可以分析事务数目对执行时间的影响。
说明:当压力加大时,点击率/TPS曲线如果变化缓慢或者有平坦的趋势,很有可能是服务器开始出现瓶颈。TPS值,越大说明系统处理能力越强。
4、Total Transactions per Second(每秒通过事务总数)
“每秒通过事务总数”显示在场景运行时,在每一秒内通过的事务总数、失败的事务总署以及停止的事务总数。该曲线走向和TPS曲线走向一致。
5、Transaction Performance Sunmmary(事务性能摘要)
“事务性能摘要”显示方案中所有事务的最小、最大和平均执行时间,可以直接判断响应时间是否符合用户的要求。
说明:重点关注事务的平均和最大执行时间,如果其范围不在用户可以接受的时间范围内,需要进行原因分析。
6、Transaction Response Time Under Load(事务响应时间与负载)
“事务响应时间与负载”是“正在运行的虚拟用户”图和“平均响应事务时间”图的组合,通过它可以看出在任一时间点事务响应时间与用户数目的关系,从而掌握系统在用户并发方面的性能数据,为扩展用户系统提供参考。此图可以查看虚拟用户负载对执行时间的总体影响,对分析具有渐变负载的测试场景比较有用。
7、Transaction Response Time(Percentile)(事务响应时间(百分比))
“事务响应时间(百分比)”是根据测试结果进行分析而得到的综合分析图,也就是工具通过一些统计分析方法间接得到的图表。通过它可以分析在给定事务响应时间范围内能执行的事务百分比。
说明:主要观察,在给定时间的范围内完成事务的百分比
参考值: 10%的TRT(P)<=5s、50%的TRT(P)<=5s、90%的TRT(P)<=5s
8、Transaction Response Time(Distribution)(事务响应时间(分布))
“事务响应时间(分布)”显示在场景运行过程中,事务执行所用时间的分布,通过它可以了解测试过程中不同响应时间的事务数量。如果系统预先定义了相关事务可以接受的最小和最
大事务响应时间,则可以使用此图确定服务器性能是否在可以接受的范围内。
说明:主要观察,大多数事务的响应时间
参考值:TRT(D)<=5s
二、确定CPU、内存泄露问题
1、%processor time(processor_total)
服务器消耗的处理器时间数量.如果服务器专用于sql server 可接受的最大上限是80% -85 %.也就是常见的CPU 使用率。
说明:正常负载下,服务器的CPU利用率应该在80%以下。超过90%,那么很可能存在处理器瓶颈。如果CPU使用率不断上升,内存使用率也不断上升,表明系统可能产生资源争用情况,引起原因,程序资源调配问题。
判断是否内存泄露问题:
内存问题主要检查应用程序是否存在内存泄漏,如果发生了内存泄漏,P rocess Bytes\Private Bytes计数器和Process\Working set 计数器的值往往会升高,同时Avaiable bytes的值会降低。内存泄漏应该通过一个长时间的,用来研究分析所有内存都耗尽时,应用程序反应情况的测试来检验。内存泄露问题经常出现在服务长时间运转的时候,由于部分程序对内存没有释放,而将内存慢慢耗尽,也是提醒大家对系统稳定性测试的关注。
2、%Disk time(physicaldisk_total)
指所选磁盘驱动器忙于为读或写入请求提供服务所用的时间的百分比。如果三个计数器都比较大,那么硬盘不是瓶颈。如果只有%Disk Time比较大,另外两个都比较适中,硬盘可能会是瓶颈。在记录该计数器之前,请在Windows 2000 的命令行窗口中运行diskperf -yD。
说明:正常值<10。若数值持续超过80%,则可能是内存泄漏。
3、Availiable bytes(memory)
用物理内存数. 如果Available Mbytes的值很小(4 MB 或更小),则说明计算机上总的内存可能不足,或某程序没有释放内存。
参考值:4 MB或更小,至少要有10%的物理内存值。
4、Page write/sec
(写的页/秒)每秒执行的物理数据库写的页数。
说明:如果服务器没有足够的内存处理其工作负荷,此数值将一直很高。如果大于80,表示有问题(太多的读写数据操作要访问磁盘,可考虑增加内存或优化读写数据的算法)。
【其他参数】
%User time(processor_total)
表示耗费CPU的数据库操作,如排序,执行aggregate functions等。如果该值很高,可考虑增加索引,尽量使用简单的表联接,水平分割大表格等方法来降低该值。
%DPC time(processor_total)
越低越好。在多处理器系统中,如果这个值大于50%并且Processor:% Processor Time非常高,加入一个网卡可能会提高性能,提供的网络已经不饱和。
Context switch/sec(system)
(实例化inetinfo 和dllhost 进程) 如果你决定要增加线程字节池的大小,你应该监视这三个计数器(包括上面的一个)。增加线程数可能会增加上下文切换次数,这样性能不会上升反而会下降。如果十个实例的上下文切换值非常高,就应该减小线程字节池的大小。
说明:可判断应用程序的问题。如果系统由于应用程序代码效率低下或者系统结构设计有缺陷而导致大量的上下文切换(Context switches/sec显示的上下文切换次数太高)那么就会占用大量的系统资源,如果系统的吞吐量降低并且CPU的使用率很高,并且此现象发生时切换水平在15000以上,那么意味着上下文切换次数过高。
%Disk reads/sec(physicaldisk_total)
每秒读硬盘字节数.
%Disk write/sec(physicaldisk_total)
每秒写硬盘字节数.
Page faults/sec
进程产生的页故障与系统产生的相比较,以判断这个进程对系统页故障产生的影响。
Pages per second
每秒钟检索的页数
该数字应少于每秒一页Working set:理线程最近使用的内存页,反映了每一个进程使用的内存页的数量。如果服务器有足够的空闲内存,页就会被留在工作集中,当自由内存少于一个特定的阈值时,页就会被清除出工作集。
Avg.disk queue length
读取和写入请求(为所选磁盘在实例间隔中列队的)的平均数。该值应不超过磁盘数的1.5~2 倍。要提高性能,可增加磁盘。注意:一个Raid Disk实际有多个磁盘。
Average disk read/write queue length
指读取(写入)请求(列队)的平均数Disk reads/(writes)/s:理磁盘上每秒钟磁盘读、写的次数。两者相加,应小于磁盘设备最大容量。
Average disk sec/read
以秒计算的在此盘上读取数据的所需平均时间。Average disk sec/transfer:指以秒计算的在此盘上写入数据的所需平均时间。
Bytes total/sec
为发送和接收字节的速率,包括帧字符在内。判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较Page read/sec:每秒发出的物理数据库页读取数。这一统计信息显示的是在所有数据库间的物理页读取总数。由于物理 I/O 的开销大,可以通过使用更大的数据高速缓存、智能索引、更高效的查询或者改变数据库设计等方法,使开销减到最小。
三、确定网络问题:
1、Hits per Second(每秒点击次数)
“每秒点击次数”,即使运行场景过程中虚拟用户每秒向Web服务器提交的HTTP请求数。 通过它可以评估虚拟用户产生的负载量,如将其和“平均事务响应时间”图比较,可以查看点击次数对事务性能产生的影响。
说明:通过对查看“每秒点击次数”,可以判断系统是否稳定。系统点击率下降通常表明服务器的响应速度在变慢,需进一步分析,发现系统瓶颈所在。
2、Throughput(吞吐率)
“吞吐率”显示的是场景运行过程中服务器的每秒的吞吐量。其度量单位是字节,表示虚拟用在任何给定的每一秒从服务器获得的数据量。可以依据服务器的吞吐量来评估虚拟用户产生的负载量,以及看出服务器在流量方面的处理能力以及是否存在瓶颈。 “吞吐率”图,是每秒服务器处理的HTTP申请数。 “点击率”图,是客户端每秒从服务器获得的总数据量。
说明:观察3张图(Running Vusers(负载数)/His per Second(点击率)/Throughput(吞吐量)),随着负载的加大,点击率和吞吐量会随之增大。如果系统的吞吐量随着负载的加大出现平坦或降低并且CPU的使用率很高,并且此现象发生时切换水平在15000以上,那么意味着上下文切换次数过高,表明网络饱和。
3、Network Delay Time
说明:网络延迟时间的曲线突起显示有网络故障。
4、Network Sub-Path Time
说明:网络Sub-Path的时间曲线跳跃式的突起证明存在网络故障。
四、确定性能问题是在网络端还是服务端:
1、Web Page Breakdown(页面分解总图)
“页面分解”显示某一具体事务在测试过程的响应情况,进而分析相关的事务运行是否正常。可以按下面四种方式进行进一步细分:
Download Time Breaddown(下载时间细分)
“下载时间细分”图显示网页中不同元素的下载时间,同时还可按照下载过程把时间进行分解,用不同的颜色来显示DNS解析时间、建立连接时间、第一次缓冲时间等各自所占比例。
Component Breakdown(Over Time)(组件细分(随时间变化))
“组件细分”图显示选定网页的页面组件随时间变化的细分图。通过该图可以很容易的看出哪些元素在测试过程中下载时间不稳定。该图特别适用于需要在客户端下载控件较多的页面,通过分析控件的响应时间,很容易就能发现那些控件不稳定或者比较耗时。
Download Time Breakdown(Over Time)(下载时间细分(随时间变化))
“下载时间细分(随时间变化)” 图显示选定网页的页面元素下载时间细分(随时间变化)情况,它非常清晰地显示了页面各个元素在压力测试过程中的下载情况。
“下载时间细分”图显示的是整个测试过程页面元素响应的时间统计分析结果,“下载时间细分(随时间变化)”显示的事场景运行过程中每一秒内页面元素响应时间的统计结果,两者分别从宏观和微观角度来分析页面元素的下载时间。
Time to First Buffer Breakdown(Over Time)(第一次缓冲时间细分(随时间变化))
“第一次缓冲时间细分(随时间变化)”图显示成功收到从Web服务器返回的第一次缓冲之前的这段时间,场景或会话步骤运行的每一秒中每个网页组件的服务器时间和网络时间(以秒为单位)。可以使用该图确定场景或会话步骤运行期间服务器或网络出现问题的时间。
First Buffer Time:是指客户端与服务器端建立连接后,从服务器发送第一个数据包开始计时,数据经过网络传送到客户端,到浏览器接收到第一个缓冲所用的时间。
2、Page Component Breakdown(页面组件细分)
“页面组件细分”图显示每个网页及其组件的平均下载时间(以秒为单位)。可以根据下载组件所用的平均秒数对图列进行排序,通过它有助于隔离有问题的组件。
3、Page Component Breakdown(Over Time)(页面组件分解(随时间变化))
“页面组件分解(随时间变化)”图显示在方案运行期间的每一秒内每个网页及其组件的平均响应时间 (以秒为单位)。
4、Page Download Time Breakdown(页面下载时间细分)
“页面下载时间细分”图显示每个页面组件下载时间的细分,可以根据它确定在网页下载期间事务响应时间缓慢是由网络错误引起还是由服务器错误引起。
“页面下载时间细分”图根据DNS解析时间、连接时间、第一次缓冲时间、SSL握手时间、接收时间、FTP验证时间、客户端时间和错误时间来对每个组件的下载过程进行细分。
5、Page Download Time Breakdown(Over Time)(页面下载时间细分(随时间变化))
“页面下载时间细分(随时间变化)”图显示方案运行期间,每一秒内每个页面组件下载时间的细分。使用此图可以确定网络或服务器在方案执行期间哪一时间点发生了问题。 “页面组件细分(随时间变化)”图和“页面下载时间细分(随时间变化)”图通常结合起来进行分析:首先确定有问题的组件,然后分析它们的下载过程,进而定位原因在哪里。
6、Time to First Buffer Breakdown(第一次缓冲时间细分)
“第一次缓冲时间细分”图显示成功收到从Web服务器返回的第一次缓冲之前的这一段时间内的每个页面组件的相关服务器/网路时间。如果组件的下载时间很长,则可以使用此图确定产生的问题与服务器有关还是与网络有关。
网络时间:定义为第一个HTTP请求那一刻开始,直到确认为止所经过的平均时间。 服务器时间:定义为从收到初始HTTP请求确认开始,直到成功收到来自Web服务器的一次缓冲为止所经过的平均时间。
说明:找出下载耗费时间最多的网页。有助排出DNS的故障,SSL的故障,网络连接的故障。
【其他Web资源分析】
1、HTTP Status Code Summary(HTTP状态代码概要)
“HTTP状态代码概要”显示场景或会话步骤过程中从Web服务器返回的HTTP状态代码数,该图按照代码分组。HTTP状态代码表示HTTP请求的状态。
2、HTTP Responses per Second(每秒HTTP响应数)
“每秒HTTP响应数”是显示运行场景过程中每秒从Web服务器返回的不同HTTP状态代码的数量,还能返回其它各类状态码的信息,通过分析状态码,可以判断服务器在压力下的运行情况,也可以通过对图中显示的结果进行分组,进而定位生成错误的代码脚本。
3、Pages Downloader per Second(每秒下载页面数)
“每秒下载页面数”显示场景或会话步骤运行的每一秒内从服务器下载的网页数。使用此图可依据下载的页数来计算Vuser生成的负载量。
和吞吐量图一样,每秒下载页面数图标是Vuser在给定的任一秒内从服务器接收到的数据量。但是吞吐量考虑的各个资源极其大小(例,每个GIF文件的大小、每个网页的大小)。而每秒下载页面数只考虑页面数。
注:要查看每秒下载页数图,必须在R-T-S那里设置“每秒页面数(仅HTML模式)”。
4、Retries per Second(每秒重试次数)
“每秒重试次数”显示场景或会话步骤运行的每一秒内服务器尝试的连接次数。 在下列情况将重试服务器连接: A、初始连接未经授权 B、要求代理服务器身份验证 C、服务器关闭了初始连接 D、初始连接无法连接到服务器
E、服务器最初无法解析负载生成器的IP地址
5、Retries Summary(重试次数概要)
“重试次数概要”显示场景或会话步骤运行过程中服务器尝试的连接次数,它按照重试原因分组。将此图与每秒重试次数图一起使用可以确定场景或会话步骤运行过程中服务器在哪个时间点进行了重试。
6、Connections(连接数)
“连接数”显示场景或会话步骤运行过程中每个时间点打开的TCP/IP连接数。 借助此图,可以知道何时需要添加其他连接。
说明:当连接数到达稳定状态而事务响应时间迅速增大时,添加连接可以使性能得到极大提高(事务响应时间将降低)。
7、Connections Per Second(每秒连接数)
“每秒连接数”显示方案在运行过程中每秒建立的TCP/IP连接数。
理想情况下,很多HTTP请求都应该使用同一连接,而不是每个请求都新打开一个连接。通过每秒连接数图可以看出服务器的处理情况,就表明服务器的性能在逐渐下降。
8、SSLs Per Second(每秒SSL连接数)
“每秒SSL连接数”显示场景或会话步骤运行的每一秒内打开的新的以及重新使用的SSL连接数。当对安全服务器打开TCP/IP连接后,浏览器将打开SSL连接。
9、Web Page Breakdown(网页元素细分)
“网页元素细分”主要用来评估页面内容是否影响事务的响应时间,通过它可以深入地分析网站上那些下载很慢的图形或中断的连接等有问题的 元素。
10、Time to First Buffer Breakdown(Over Time)(第一次缓冲时间细分(随时间变化))
“第一次缓冲时间细分(随时间变化)”图显示成功收到从Web服务器返回的第一个缓冲之前的这段时间内,场景运行的每一秒中每个网页组件的服务器时间和网络时间。可以使用此图确定场景运行期间服务器或网络出现问题的时间点。
11、Downloader Component Size(KB)(已下载组件大小)
“已下载组件大小”图显示每个已经下载的网页组建的大小。通过它可以直接看出哪些组件比较大并需要进一步进行优化以提高性能。
响应时间
用户通过客户端向服务端发出请求的时间为:T1
服务端接收到请求,处理该请求的时间为:T2
服务端返回数据给客户端时间为:T3
客户端接收到响应数据,处理数据呈现给用户时间为:T4
响应时间系统视角
系统的响应时间Ts= T1+T2+T3
该时间没有包括客户端对数据处理并呈现的时间T4
响应时间用户视角
用户眼中的的响应时间Tu = T1+T2+T3+T4
用户通过客户端发出请求到客户端展现请求结果,这个时间越短越好
响应时间服务器视角
服务器接收到客户端发送的请求,并给出响应,这个过程所消耗的时间为响应时间,即服务器仅关注T2
从不同的视角下,衡量响应时间的指标也各不相同。在实际测试过程中,要明确以什么视角验证被测对象的性能。
并发
并发用户数
简称 VU ,指的是系统中操作业务的用户。一般称为虚拟用户数。并发用户数跟注册用户数,在线用户数有很大差别。并发用户数一定会对服务器产生压力,而在线用户数只是挂在系统上,对服务器不产生压力
在线用户数
在已有系统中选取高峰时刻,在一定时间内使用系统的人数,这些人数可认为是在线用户数
注册用户数
数据库中存在的用户数。并发用户数可以取系统用户数的10%,例如在半个小时内,使用系统的用户数为10万,那么取10%(即1万)作为并发用户数
系统并发数
一般指测试工具为了模拟出用户并发压力而启动的线程,比如jmeter里面的Thread。由于jmeter中的线程有迭代的概念,所以通过线程迭代数就可以模拟出用户单位时间最大的并发数。
注意不要把系统并发数和并发用户数*的概念混在一起哦~
并发视角
广义
单位时间内同时发送给服务器的请求数,强调同时发送。比如一秒钟点击100次查询
狭义
单位时间内同时发送给服务器相同的业务,强调业务请求相同。比如一秒钟有100人点击了查询按钮
服务端视角
并发数为单位时间内服务端接收到的请求数
客户端视角
单位时间内同时发送给服务端的请求数
用户视角
客户端的业务请求一般为用户操作行为,也可理解为并发用户数,又可称为虚拟用户数
吞吐量
单位时间内系统处理请求的数量。吞吐量直接体现了软件系统的业务处理能力
衡量方式
Rps 请求数/单位时间
Hps 点击数/单位时间
Tps 通过事物数/单位时间
Qps 查询数/单位时间
TPS模型
随着压力不断增长,实测系统的资源会不断被消耗,TPS值会因为这些因素而发生变化,并且符合一定的规律
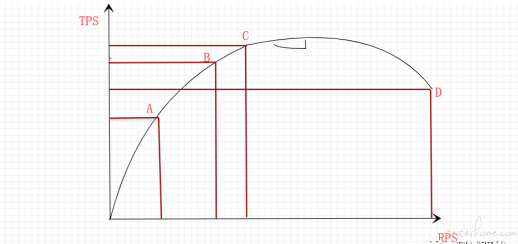
a点:性能期望值
b点:高于期望值,系统资源处于临界点
c点:高于期望值,拐点
d点:超过最大负载,系统崩溃
从上述模型,将性能测试分为3种类型
基准测试
原点到a之间的系统性能,指以系统预期性能指标为前提,对系统不断增加压力,以验证系统能否达到预期性能
负载测试
a到b的系统性能,是指对系统不断地增加压力或一定压力下的持续运行,直到系统的某项或多项性能指标达到极限,例如某种资源已经达到饱和状态等
压力测试
b 到d之间的系统性能,是指超过安全负载的情况下,对系统不断施加压力,直到系统崩溃,找出系统的瓶颈点和崩溃点。
TPS(每秒处理事务数)
一个事务是指客户端向服务器发送请求然后服务器做出反应的过程
单请求事物
事物由单个接口请求构成。如一次登录,一次查询
多请求事物
事物由多个接口请求构成。如登录-查询-新增-退出。这四步操作构成一个完整的事物
TPS的决定性因素
事务是要靠虚拟用户完成
1个用户在1秒内完成1笔事务,那么TPS就是 1
1个事物响应时间是1ms,那么1个用户在1秒内能完成1000笔事务。TPS就是1000
1笔业务响应时间是1s,那么1个用户在1秒内只能完成1笔事务。想达到1000TPS就至少需要1000个用户
因此可以说1个用户能产生1000TPS, 1000个用户也可以产生1000TPS,由响应时间决定
Rps 每秒发起的请求数
并发数=rps*平均响应时间
RPS用来描述施压引擎实际发出的压力大小
RPS模式主要是为了站在服务端视角去直接衡量系统的吞吐能力-TPS而设计的
并发过低时可能达不到预期的RPS,并发过高时可能压力过大直接压垮服务器
按照被压测端需要达到的TPS去设置相应的RPS,应用场景主要是一些动态的接口API,比如登陆、提交订单
吞吐量行业标准
金融行业:1000TPS~50000TPS,不包括互联网化的活动
保险行业:100TPS~100000TPS,不包括互联网化的活动
制造行业:10TPS~5000TPS
互联网电子商务:10000TPS~1000000TPS
互联网中型网站:1000TPS~50000TPS
互联网小型网站: 500TPS~10000TPS


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· DeepSeek 开源周回顾「GitHub 热点速览」
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了