Map
HashMap

public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
//初始容量 默认为16
static final int default_initial_capacity = 1 << 4; // aka 16
//最大容量 这是个非常大的值, 一般只要内存够用,这就可以看作是无限大
static final int maximum_capacity = 1 << 30;
//扩容因子 当键值对的数量大于 16 * 0.75 = 12 时,就会触发扩容。
static final float default_load_factor = 0.75f;
//链表转红黑树阀值
static final int treeify_threshold = 8;
//红黑树转链表阀值
static final int untreeify_threshold = 6;
//数组
transient Node<K, V>[] table;
int threshold;//扩容阀值 当实际大小(容量*填充比)超过临界值时,会进行扩容
final float loadFactor;//扩容因子
//链表节点
static class Node<K, V> implements Map.Entry<K, V> {
final int hash;
final K key;
V value;
java.util.HashMap.Node<K, V> next;
}
//红黑树节点
static final class TreeNode<k, v> extends LinkedHashMap.Entry<k, v> {
TreeNode<k, v> parent; // 父节点
TreeNode<k, v> left; //左子树
TreeNode<k, v> right;//右子树
TreeNode<k, v> prev; // needed to unlink next upon deletion
boolean red; //颜色属性
TreeNode(int hash, K key, V val, Node<k, v> next) {
super(hash, key, val, next);
}
//返回当前节点的根节点
final TreeNode<k, v> root() {
for (TreeNode<k, v> r = this, p; ; ) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
}
}
HashMap hashMap = new HashMap();
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
HashMap hashMap = new HashMap(11);
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)//校验容量
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//设置扩容因子 设置扩容阀值
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
- 重要属性包括:
- Node类型数组table:数组每个位置就是一个桶位
- 初始容量default_initial_capacity:初始容量16
- 最大容量maximum_capacity:这是个非常大的值,肯定够用,一般不用考虑这个
- 默认扩容因子default_load_factor:默认0.75,当存储元素达到容量的百分75时进行扩容
- 红黑树转链表阀值treeify_threshold:8
- 链表转红黑树阀值untreeify_threshold:6
- 链表节点Node:
- 红黑树节点TreeNode:
- 构造器有两个:
- 无参构造器:
- 指定容量构造器:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;//数组
Node<K,V> p;//桶位上的元素
int n, i;
if ((tab = table) == null || (n = tab.length) == 0)//初始化
n = (tab = resize()).length;
//新插入的桶位置上如果为null,直接插入(没有哈希冲突)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {//桶位上已经有元素了(哈希冲突)
Node<K,V> e;
K k;
//桶位上的元素和要新插入的元素的key相同,直接覆盖
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//桶位上的元素不是新插入的元素,这个时候就要遍历桶位下的链表或者红黑树,
//挨个比对,如果找到就覆盖,没找到则插入到链表或者红黑树
else if (p instanceof TreeNode)//如果桶位上是TreeNode,则表示当前元素个数已经超过8,直接走红黑树插入逻辑
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//链表插入逻辑
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//如果桶位的下一个节点是null
p.next = newNode(hash, key, value, null);//创建一个新节点插入的next位置
if (binCount >= TREEIFY_THRESHOLD - 1) // 如果达到红黑树阀值,则进行红黑树转换
treeifyBin(tab, hash);
break;
}
//如果发现相同的key值就结束遍历,直接覆盖
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//进入这个分支表示,此次插入的新元素原来已经存在,是覆盖的,不是新增
//这种情况不需要更新size,扩容,直接返回即可
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//如果当前大小大于门限,门限原本是初始容量*0.75
if (++size > threshold)
resize();//扩容两倍
afterNodeInsertion(evict);
return null;
}
- 首先判断是否初次使用,如果是,则初始化数组,默认大小为16。
- 计算key的hash值,定位到数组的索引位置,判断数组该位置的值是否为null,如果为null直接赋值给数组的该位置
- 如果不为null,判断当前数组下的哈希碰撞处理方式是链表还是红黑树(通过检查第一个节点类型即可,是treeNode还是Node),然后走两种结构的逻辑。
- 红黑树逻辑略
- 链表采用尾插法:即从第一个节点开始往后遍历,知道找到最后一个节点,然后创建新节点插入,期间如果遇到相同key的元素,直接覆盖即可。
- 如果当前为红黑树并且数量小于6,则转为链表,如果当前为链接且大于8则转为红黑树。
- 最后进行扩容逻辑:创建一个大小为原来两倍的数组,然后将老数组元素一个一个插入进去
问题1:扩容阀值为什么是0.75?
随着map存储元素数量的增加,发生哈希碰撞的概率也越来越高,0.75是经过计算定下的值,也就是说在map容量使用达到百分75之前,发生哈希碰撞的概率是可以接受的。 达到百分之75之后发生哈希碰撞的概率是不可接受的。
问题2:链表为什么尾插法?
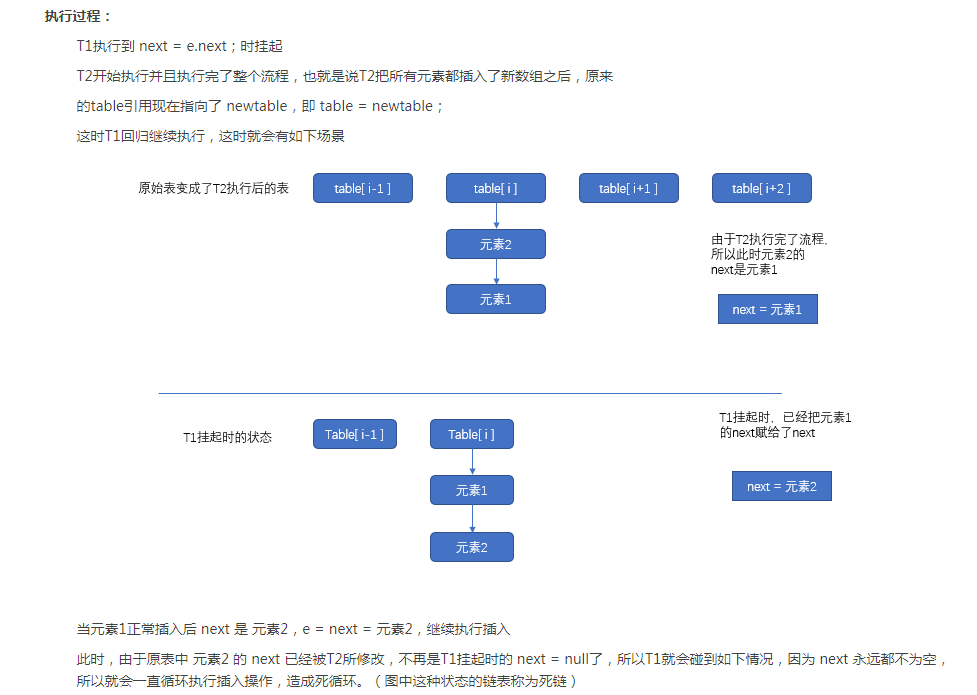
ConcurrentHashmap
jdk1.8之前是通过将整个map分成多个segment,然后更新的时候以segment为单位加锁。
jdk1.8开始用Unsafe的cas + sychronize锁。
我们看一下jdk1.8的put方法是怎么实现的
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0; //用来计算在这个节点总共有多少个元素,用来控制扩容或者转移为树
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
//第一次put的时候table没有初始化,则初始化table
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //桶位上没有元素
//创建一个节点,通过unsafe的cas添加到桶位上
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
/*
* 如果检测到某个节点的hash值是MOVED,则表示正在进行数组扩张的数据复制阶段,
* 则当前线程也会参与去复制,通过允许多线程复制的功能,一次来减少数组的复制所带来的性能损失
*/
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {//桶位上有元素
V oldVal = null;
synchronized (f) {//加锁
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount); //计数
return null;
}
- 当桶位上没有元素,向桶位添加元素时,采用Unsafe的cas操作
- 当遍历链表或者红黑树的时候用sychronize加锁。
LinkedHashMap
LinkedHashMap是HashMap的子类,内部既维护了HashMap的数据结构,同时维护了一个双向链表来提供顺序性。

支持两种顺序:按照插入顺序和按照访问顺序。
插入顺序:先添加的在前面,后添加的在后面。修改操作不影响顺序
访问顺序:所谓访问指的是get/put操作,对一个键执行get/put操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始的是最久没有被访问的,这就是访问顺序。
Map<String, Integer> seqMap = new LinkedHashMap<>();
seqMap.put("c",100);
seqMap.put("d",200);
seqMap.put("a",500);
seqMap.put("d",300);
for(Entry<String,Integer> entry:seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}//输出结果为c d a
Map<String, Integer> accessMap = new LinkedHashMap<>(16,0.75f,true);
accessMap.put("c",100);
accessMap.put("d",200);
accessMap.put("a",500);
accessMap.get("c");//这部会把c元素移动到链表尾部
accessMap.put("d",300);//这部会把d元素移动到链表尾部
for(Map.Entry<String,Integer> entry:accessMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}//输出结果 a c d
核心属性
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V> {
static class Entry<K, V> extends HashMap.Node<K, V> {
java.util.LinkedHashMap.Entry<K, V> before, after;
Entry(int hash, K key, V value, Node<K, V> next) {
super(hash, key, value, next);
}
}
transient java.util.LinkedHashMap.Entry<K, V> head;
transient java.util.LinkedHashMap.Entry<K, V> tail;
/**
* 用来指定LinkedHashMap的迭代顺序,
* true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾
* false则表示按照插入顺序来
*/
final boolean accessOrder;
添加方法:
添加逻辑继承于HashMap,但是在HashMap中设置了两个钩子方法:newNode和afterNodeInsertion。
LinkedHashMap在这两个方法中实现了链表特性。
HashMap.Node<K,V> newNode(int hash, K key, V value, HashMap.Node<K,V> e) {
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
//设置before、after、head、tail属性
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
//插入后把最老的Entry删除,不过removeEldestEntry总是返回false,
//所以不会删除,估计又是一个钩子方法给子类用的,这里忽略吧
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
查找方法:
public V get(Object key) {
HashMap.Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)//查询使用的HashMap的实现
return null;
if (accessOrder)//如果为true,表示通过迭代的时候根据访问顺序来迭代,所以这里访问后要更新内部链表结构,来满足后续迭代
afterNodeAccess(e);
return e.value;
}
TreeMap
底层红黑树实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号